ScaleSim: 呼び出し距離に基づくメモリ管理による大規模マルチエージェント・シミュレーションの効率化
大規模なマルチエージェント・シミュレーションにおいて、各エージェントが個別に保持するLoRAアダプタやキャッシュなどの膨大なメモリ消費がGPUの物理容量を超え、頻繁なデータ転送による深刻な遅延が発生している。
TL;DR(結論)
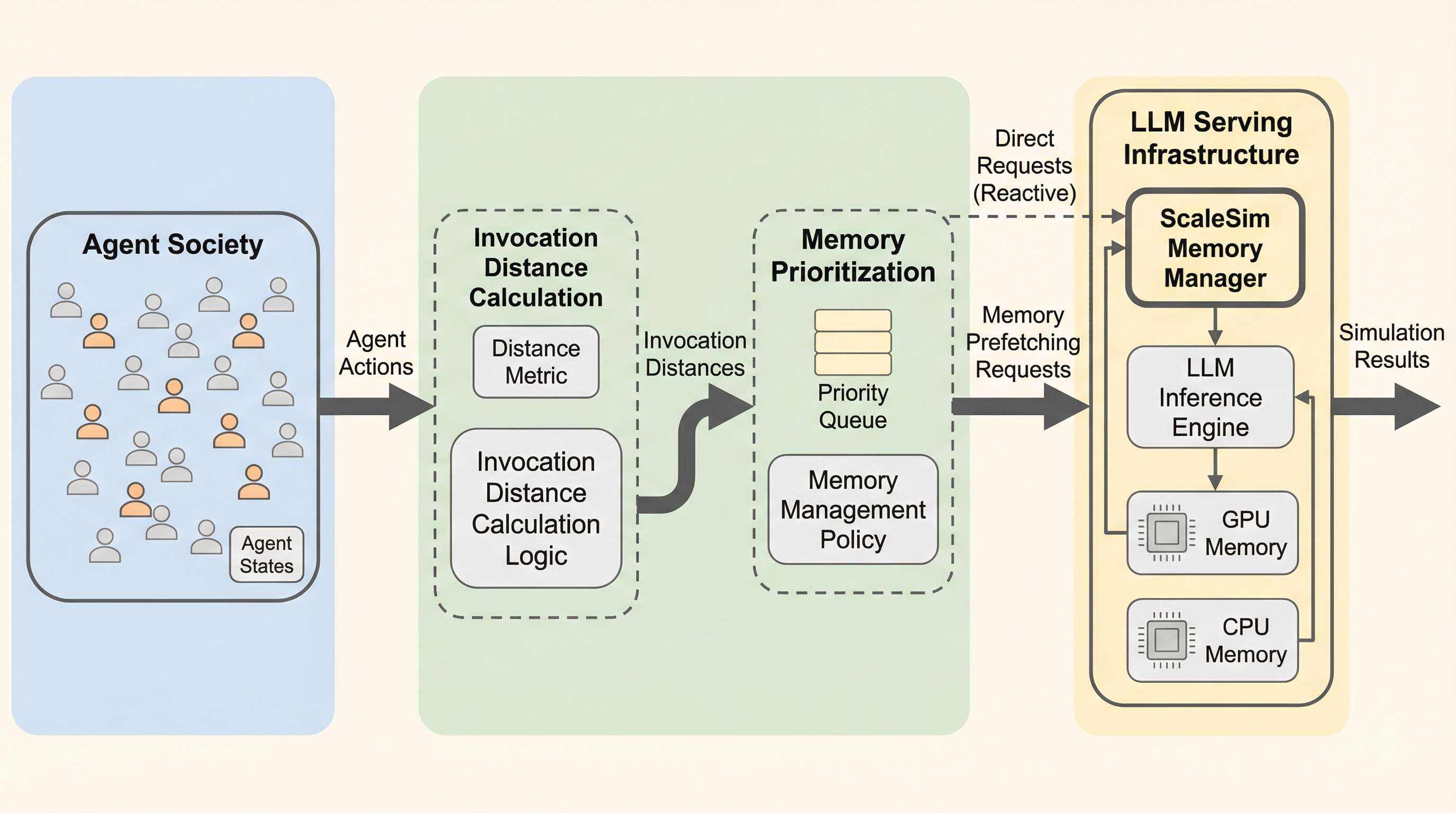
大規模なマルチエージェント・シミュレーションにおいて、各エージェントが個別に保持するLoRAアダプタやキャッシュなどの膨大なメモリ消費がGPUの物理容量を超え、頻繁なデータ転送による深刻な遅延が発生している。本研究では、エージェントの活動が一時的であることと、次のLLM呼び出し順序が予測可能であるという特性に着目し、将来の呼び出しまでの時間的猶予を数値化する新たな抽象化概念「呼び出し距離(Invocation Distance)」を導入した。この距離情報に基づき、メモリの優先的な確保や事前取得、不要なデータの破棄を動的に行うシステム「ScaleSim」を開発し、既存のLLMサービングシステムであるSGLangと比較して最大1.74倍の高速化を達成することに成功した。
なぜこの問題か
LLMを用いたマルチエージェント・シミュレーションは、社会科学、自動運転、都市計画、経済モデリングなど、複雑な相互作用を分析するための重要なツールとして急速に普及している。シミュレーションの規模を拡大し、エージェントの数を増やすことは、行動の多様性を高め、より複雑な相互作用パターンを再現するために不可欠である。しかし、既存のLLMサービングシステムでは、大規模なシミュレーションを効率的に処理することが困難であるという問題がある。その最大のボトルネックは、エージェント固有のメモリ消費にある。各エージェントは、プライベートなモデル、LoRAアダプタ、プレフィックスキャッシュ、行動履歴といった個別のデータをGPU上に保持する必要がある。エージェント数が増加すると、これらのメモリ需要の合計はGPUの物理的な容量を容易に超えてしまう。 既存のシステムはアプリケーションの実行セマンティクスを把握していないため、メモリ管理にはLRU(最近使用されていないものを破棄する)などの汎用的な手法が用いられる。…
核心:何を提案したのか
本研究では、大規模マルチエージェント・シミュレーションに特化したメモリ管理システム「ScaleSim」を提案している。ScaleSimの核心的なアイデアは、シミュレーションの文脈から得られる「呼び出し距離(Invocation Distance)」という統一的な抽象化概念を導入したことである。これは、各エージェントが現在の状態から次にLLMリクエストを発行するまでの相対的な順序を推定する指標である。シミュレーションにおけるエージェントの実行は、LLMを呼び出して行動を決定するフェーズと、その行動を環境内で実行するフェーズの2段階を繰り返す構造を持っている。この構造により、エージェントの活性化は疎であり、かつ次の活性化タイミングを予測することが可能になる。 ScaleSimはこの呼び出し距離を利用して、メモリ管理の意思決定を最適化する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related