EWSJF: 混合ワークロードのLLM推論に向けたハイブリッド分割による適応型スケジューラ
大規模言語モデル(LLM)の推論において、短時間の対話型クエリと長時間のバッチ処理が混在すると、従来の先着順方式では長い処理が先頭で詰まり、応答遅延やハードウェア効率の低下を招くという課題がある。
TL;DR(結論)
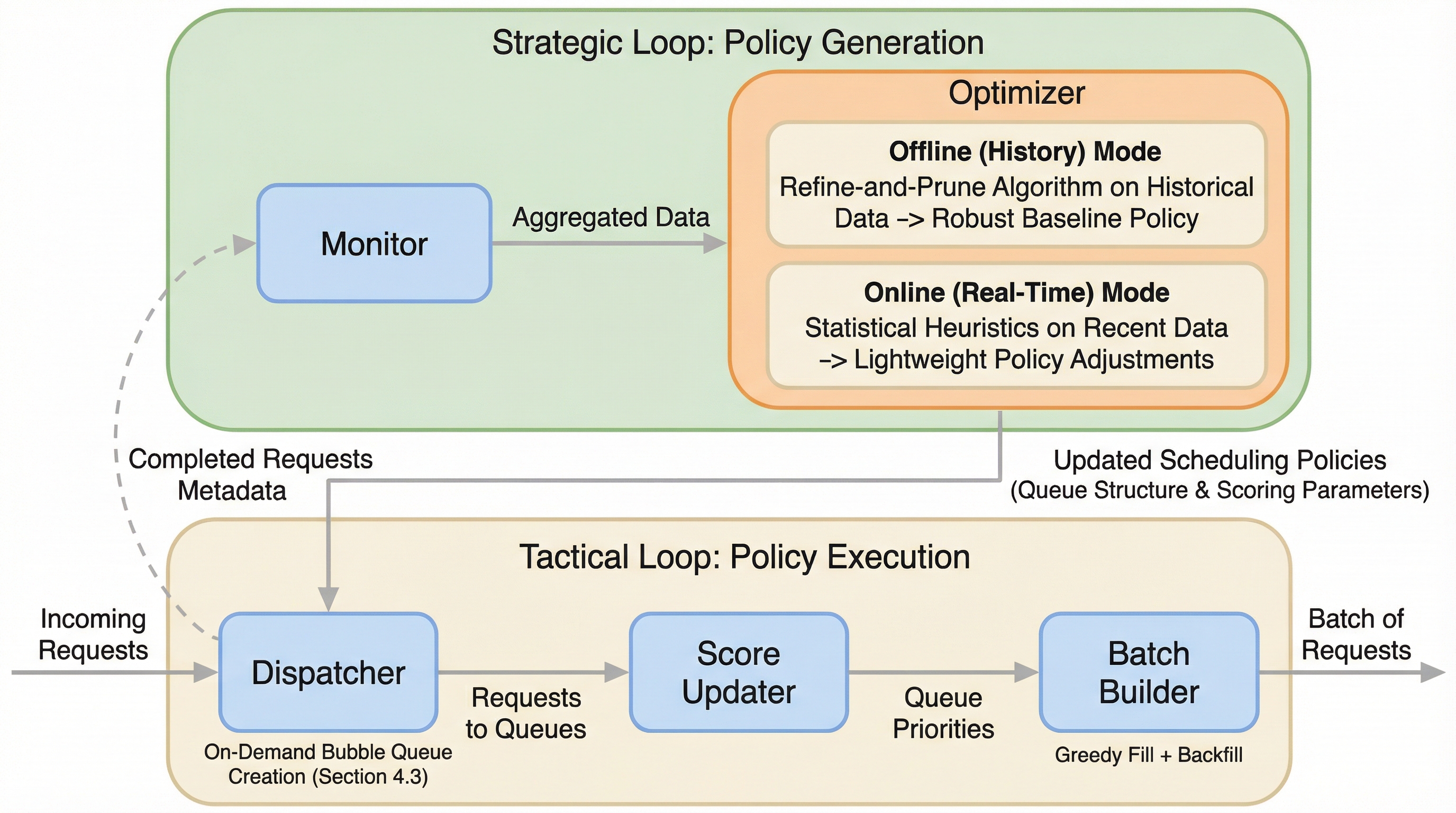
大規模言語モデル(LLM)の推論において、短時間の対話型クエリと長時間のバッチ処理が混在すると、従来の先着順方式では長い処理が先頭で詰まり、応答遅延やハードウェア効率の低下を招くという課題がある。 本研究が提案するEWSJFは、教師なし学習による「Refine-and-Prune」アルゴリズムでリクエストを特性ごとに自動分割し、ベイズ最適化を用いて優先度スコアを動的に調整することで、公平性とスループットを両立させる適応型スケジューラである。 vLLMに実装して検証した結果、従来の先着順方式と比較してシステム全体のスループットを30%以上向上させ、短いリクエストの最初のトークン生成までの時間(TTFT)を最大4倍短縮することに成功し、実用的なサービング基盤としての有効性を示した。
なぜこの問題か
大規模言語モデル(LLM)の普及に伴い、計算のボトルネックは学習フェーズから推論フェーズへと移行しており、効率的なサービングシステムの構築が不可欠となっている。実際の運用環境では、チャットボットのような応答速度が重視される短いクエリと、要約やデータ解析のようなスループットが重視される長いバッチ処理が混在する「混合ワークロード」が一般的になっている。しかし、現在の主要な推論フレームワークは、比較的均一なワークロードに対して最適化されており、性質の異なるリクエストが同時に押し寄せる状況には十分に対応できていない。 標準的な先着順(FCFS)スケジューリングでは、単一の長いリクエストがキューの先頭を占有することで、後続のすべてのリクエストを待たせてしまう「ヘッドオブライン(HoL)ブロッキング」という深刻な問題が発生する。これにより、短いクエリに対する最初のトークン生成までの時間(TTFT)が数分単位で急増することがあり、ユーザー体験を著しく損なう。一方で、ハードウェアのリソースが十分に活用されないという非効率性も生じている。既存の解決策には限界がある。静的な優先度付きキューは、変化し続けるワークロードの分布に適応できない。…
核心:何を提案したのか
本研究は、LLM推論のための適応型リクエストレベルスケジューラである「EWSJF(Effective Workload-based Shortest Job First)」を提案している。EWSJFは、実行エンジンの内部を大幅に変更するのではなく、その上流で動作するインテリジェントなアドミッションコントローラーとして機能する。その主な目的は、異種混合のリクエストをパフォーマンスの観点から均質なグループに整理し、後続の実行エンジンがより効率的に動作できるようにすることである。これにより、既存の推論エンジンの最適化機能を最大限に引き出すことが可能になる。 EWSJFの設計は、3つの主要なアイデアに基づいている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related