EWSJF: 混合ワークロードLLM推論のためのハイブリッド分割型適応スケジューラ
大規模言語モデル(LLM)の推論において、低遅延が求められる短文クエリとスループット重視の長文バッチが混在する「混合ワークロード」は、従来の先入れ先出し(FCFS)方式では先頭ブロッキングを引き起こし、効率を著しく低下させていました。
TL;DR(結論)
大規模言語モデル(LLM)の推論において、低遅延が求められる短文クエリとスループット重視の長文バッチが混在する「混合ワークロード」は、従来の先入れ先出し(FCFS)方式では先頭ブロッキングを引き起こし、効率を著しく低下させていました。本研究が提案するEWSJFは、ワークロードの構造をリアルタイムで学習する適応型スケジューラであり、教師なし分割アルゴリズム「Refine-and-Prune」とベイズメタ最適化を組み合わせることで、リクエストの承認段階で最適なグループ化を実現します。vLLMを用いた検証では、従来方式と比較してシステム全体のスループットを30%以上向上させ、短いリクエストの最初のトークン生成までの時間(TTFT)を最大4倍短縮することに成功しており、公平性と効率性の両立を証明しました。
なぜこの問題か
大規模言語モデル(LLM)の急速な普及に伴い、計算資源のボトルネックはモデルの学習フェーズから推論サービングのフェーズへと移行しており、効率的な推論システムの構築が喫緊の課題となっています。現在の商用LLMサービスでは、チャットボットのような応答速度が重視されるインタラクティブな短文クエリと、文書要約やデータ解析のようなスループットが重視される長文のバッチ処理が同じサーバー上で混在する「混合ワークロード」が一般的です。しかし、vLLMなどの既存の推論フレームワークは、比較的均一なワークロードを想定して最適化されており、このような不均一なトラフィック条件下では深刻なパフォーマンス低下を招きます。 標準的な先入れ先出し(FCFS)ポリシーを採用した場合、単一の非常に長いリクエストがキューの先頭に位置するだけで、後続のすべての短いリクエストが長時間待たされる「先頭ブロッキング(Head-of-Line blocking)」が発生します。…
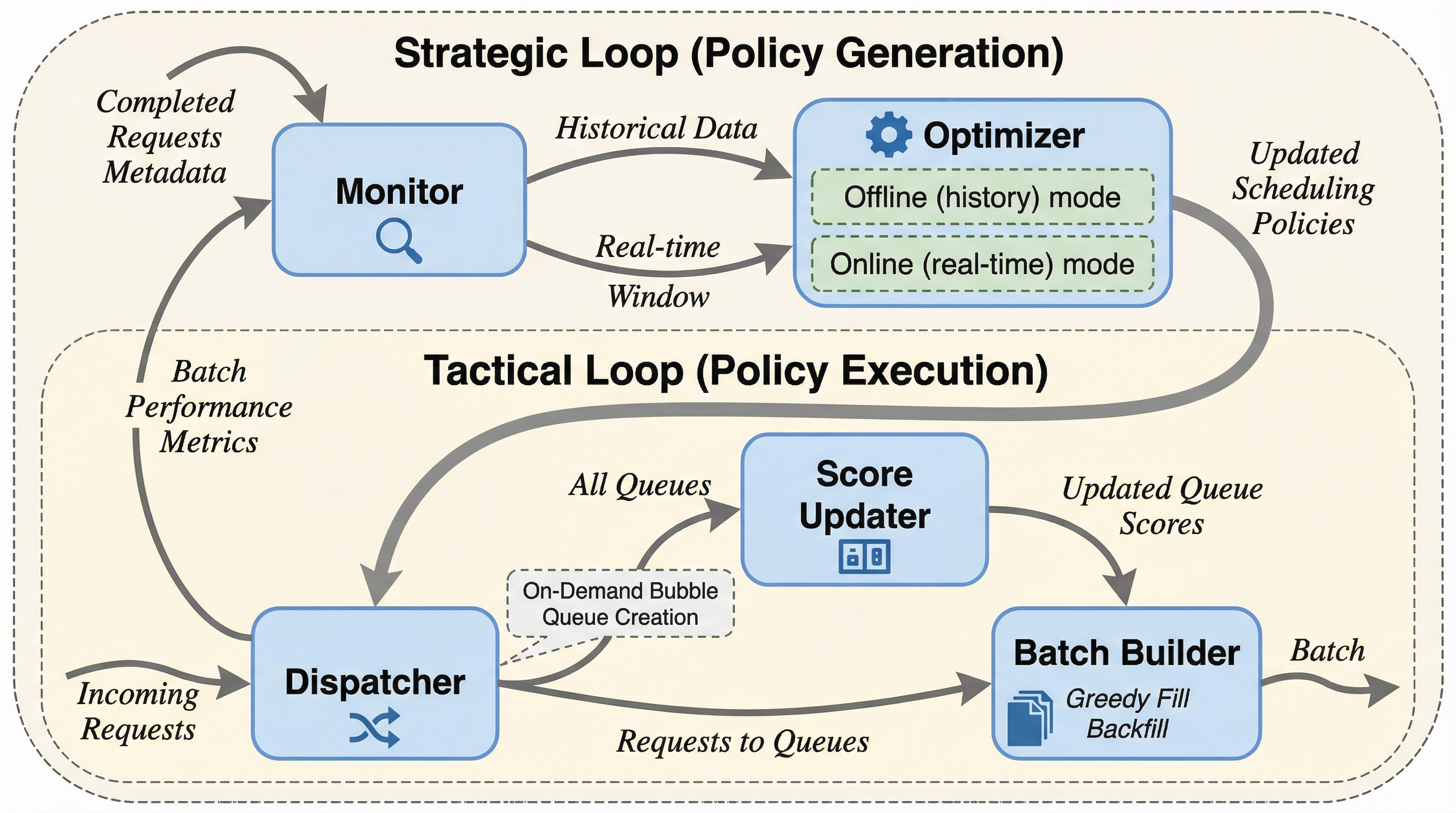
核心:何を提案したのか
本研究では、推論エンジンの内部構造を大幅に変更するのではなく、その上流で動作するインテリジェントな承認コントローラとして「EWSJF(Effective Workload-based Shortest Job First)」を提案しています。EWSJFの根本的な目的は、不均一で予測困難なリクエスト群を、パフォーマンス特性が均一なバッチへと動的に整理することにあります。これにより、後続の実行レベルのスケジューラがより効率的に動作できる環境を整え、単純な最短ジョブ優先(SJF)アルゴリズムが陥りがちな「長いジョブの飢餓状態」や公平性の欠如を回避しながら、システム全体の最適化を図ります。 EWSJFは、主に3つの革新的な技術的柱によって構成されています。第一に、パフォーマンスが均一なリクエストグループを自動的に発見する教師なし分割アルゴリズム「Refine-and-Prune」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related