ZipMoE: 無損失圧縮とキャッシュアフィニティ・スケジューリングによる効率的なオンデバイスMoEサービング
ZipMoEは、メモリ制約の厳しいエッジデバイスにおいて、Mixture-of-Experts(MoE)モデルを精度劣化なく高速に実行するための革新的な推論システムです。BF16形式のパラメータに含まれる統計的な冗長性を利用した無損失圧縮技術と、マルチコアCPUによる並列展開を組み合わせることで、従来のI/Oボトルネックを計算中心のワークフローへと劇的に転換しました。NVIDIA Jetson AGX Orinを用いた広範な検証では、最新の既存システムと比較して推論遅延を最大72.77%削減し、スループットを最大6.76倍向上させるという圧倒的な性能向上を達成しており、プライバシーと精度が求められるオンデバイスAIの新たな可能性を切り拓いています。
TL;DR(結論)
ZipMoEは、メモリ制約の厳しいエッジデバイスにおいて、Mixture-of-Experts(MoE)モデルを精度劣化なく高速に実行するための革新的な推論システムです。BF16形式のパラメータに含まれる統計的な冗長性を利用した無損失圧縮技術と、マルチコアCPUによる並列展開を組み合わせることで、従来のI/Oボトルネックを計算中心のワークフローへと劇的に転換しました。NVIDIA Jetson AGX Orinを用いた広範な検証では、最新の既存システムと比較して推論遅延を最大72.77%削減し、スループットを最大6.76倍向上させるという圧倒的な性能向上を達成しており、プライバシーと精度が求められるオンデバイスAIの新たな可能性を切り拓いています。
なぜこの問題か
近年、プライバシー保護や低遅延な応答、オフライン環境での利用を目的として、大規模言語モデル(LLM)をスマートフォンやエッジデバイス上で直接動作させる「オンデバイス推論」への需要が急速に高まっています。特にMixture-of-Experts(MoE)アーキテクチャは、モデルの一部のみを動的に活性化させることで、計算コストを抑えつつモデル容量を拡大できるため、LLMの有力な構成要素となっています。しかし、MoEモデルはその巨大なパラメータサイズゆえに、メモリ容量が限られたエッジデバイスへのデプロイにおいて極めて深刻な障壁に直面しています。この問題を解決するために従来用いられてきた「量子化」や「プルーニング」といった手法は、モデルの重みを低精度化することでサイズを削減しますが、これらは情報の損失を伴う「有損失圧縮」です。近年の研究では、こうした有損失圧縮がモデルの精度を低下させるだけでなく、セキュリティ上の脆弱性を生むリスクが指摘されています。例えば、フル精度のモデルでは安全に動作する場合でも、量子化されたモデルでは悪意のあるコード生成やコンテンツ注入攻撃に対して脆弱になることが証明されています。…
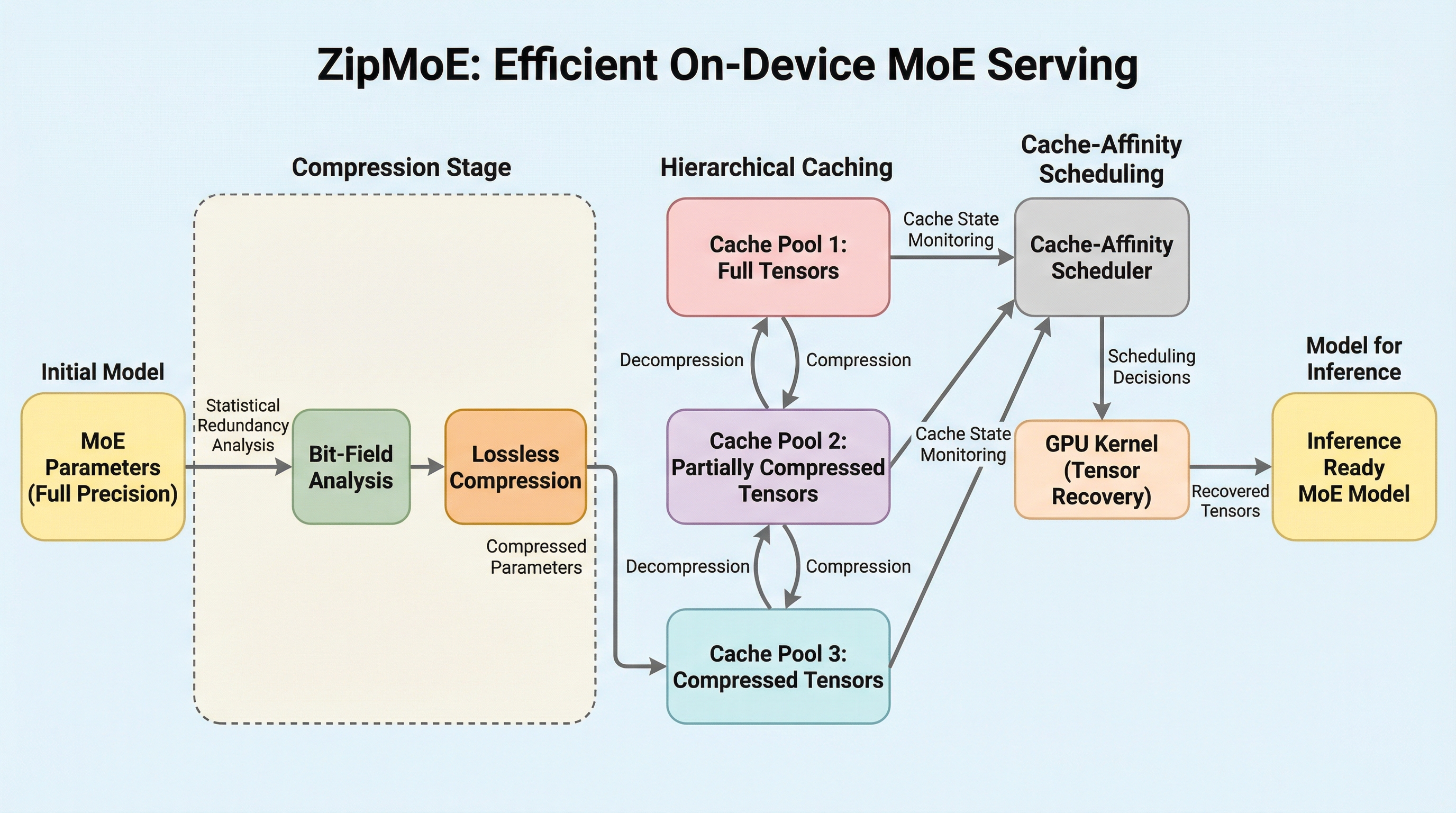
核心:何を提案したのか
本研究が提案する「ZipMoE」は、エッジデバイスのハードウェア特性とMoEモデルのパラメータが持つ統計的冗長性の相乗効果を最大限に引き出す、新しい推論エンジンです。ZipMoEの核心は、モデルの重みを一切改変せずにサイズを削減する「無損失圧縮」と、その展開処理を推論パイプラインに高度に統合した「キャッシュ・スケジューリング協調設計」にあります。具体的には、LLMで標準的に使われるBF16(Brain Floating Point)形式のデータ構造に着目しました。BF16は符号、指数、仮数の各ビットフィールドで構成されますが、本研究の分析により、指数ビットには極めて高い統計的偏り(冗長性)があることが判明しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related