ZipMoE: 無損失圧縮とキャッシュアフィニティ・スケジューリングによる効率的なオンデバイスMoEサービング
巨大なメモリを必要とするMixture-of-Experts(MoE)モデルを、エッジデバイスの限られたリソースで効率的に動作させるための推論エンジン「ZipMoE」が提案されました。 モデルの精度を損なう量子化に頼らず、BF16形式の指数ビットに含まれる統計的冗長性を活用した無損失圧縮と、CPUとGPUがメモリを共有するアーキテクチャに最適化した並列処理を導入しています。 実機検証では、既存の最新システムと比較して推論の遅延を最大72.77%削減し、スループットを最大6.76倍に向上させるという、極めて高いパフォーマンス改善を達成しました。
TL;DR(結論)
巨大なメモリを必要とするMixture-of-Experts(MoE)モデルを、エッジデバイスの限られたリソースで効率的に動作させるための推論エンジン「ZipMoE」が提案されました。 モデルの精度を損なう量子化に頼らず、BF16形式の指数ビットに含まれる統計的冗長性を活用した無損失圧縮と、CPUとGPUがメモリを共有するアーキテクチャに最適化した並列処理を導入しています。 実機検証では、既存の最新システムと比較して推論の遅延を最大72.77%削減し、スループットを最大6.76倍に向上させるという、極めて高いパフォーマンス改善を達成しました。
なぜこの問題か
近年、大規模言語モデル(LLM)をモバイルデバイスやエッジデバイス上で直接実行する「オンデバイス推論」への需要が高まっています。オンデバイス推論は、機密データをクラウドに送信する必要をなくし、ネットワークの不安定さによるサービス中断を回避できるため、パーソナルアシスタントやチャットボットなどのアプリケーションにおいて重要です。MoEアーキテクチャは、モデルを専門化された「エキスパート」に分割し、トークンごとに一部のみを活性化させることで、計算負荷を抑えつつモデル容量を拡大できる優れた手法です。しかし、MoEモデルはその巨大なメモリフットプリントが原因で、リソースの限られたエッジデバイスへの展開が非常に困難であるという課題を抱えています。 これまでの研究では、モデルの重みを低精度にする量子化や、構造を削減する剪定(プルーニング)が主に用いられてきました。しかし、量子化による誤差はテンソルやエキスパート、さらにはトークンごとに不均一であり、精度の低下を招くだけでなく、セキュリティ上のリスクも指摘されています。…
核心:何を提案したのか
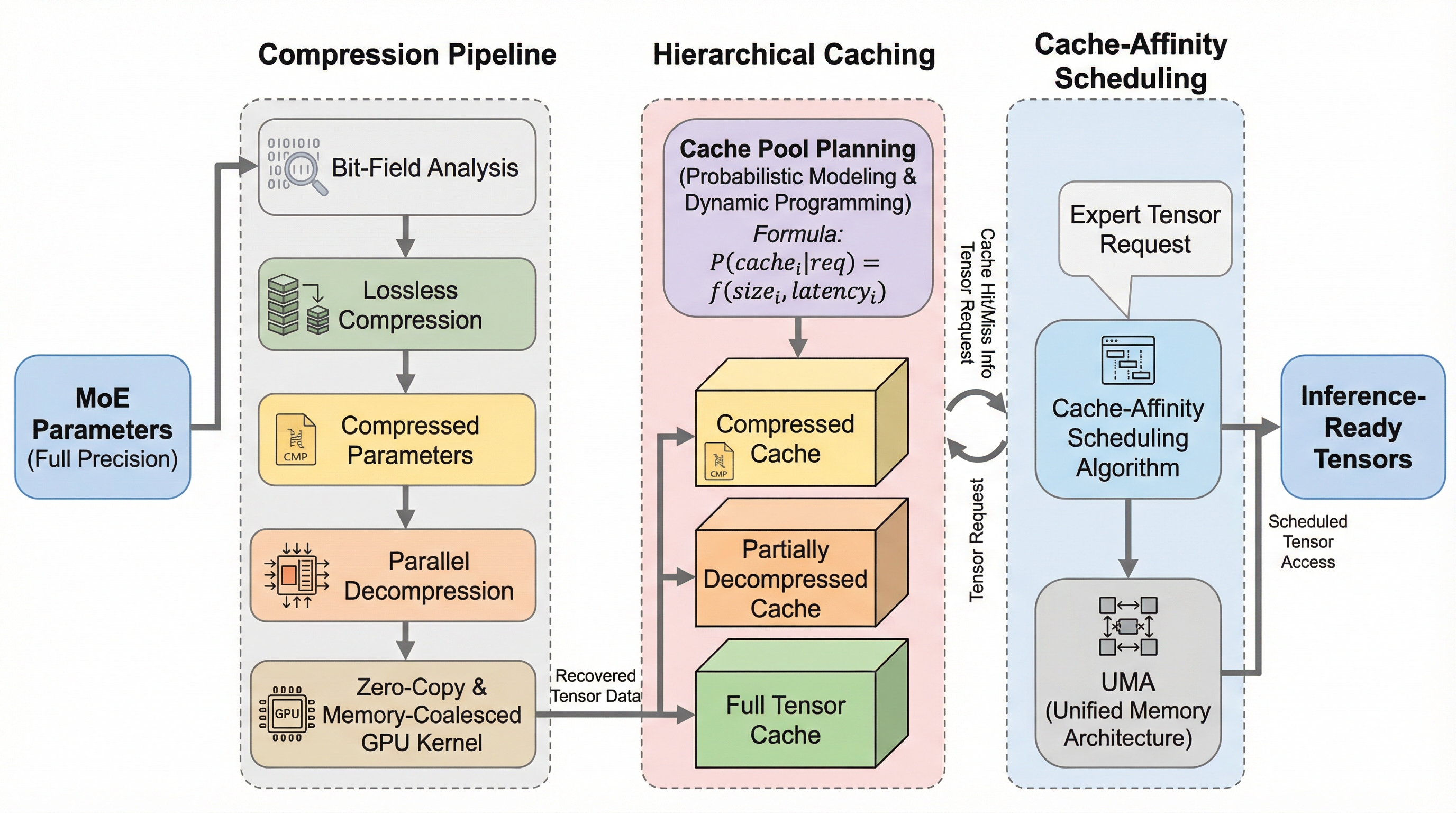
本論文では、モバイルおよびエッジコンピューティングシステム向けに特別に設計された効率的なMoE推論エンジン「ZipMoE」を提案しています。ZipMoEの核心は、MoEパラメータの特定のビットフィールドに存在する大きな統計的冗長性を利用し、I/Oボトルネックを計算中心のワークフローへと転換させることにあります。具体的には、モデルの挙動を完全に維持する「無損失圧縮」と、ハードウェアの特性を最大限に引き出す「キャッシュアフィニティ・スケジューリング」を組み合わせた設計を採用しています。 ZipMoEは、まずBF16(Brain Floating Point)形式のパラメータを、符号・仮数ビットと指数ビットに分離するビットフィールド分解を行います。指数ビットはエントロピーが低く、高い圧縮が可能であることに着目し、これを無損失圧縮することでストレージからの転送量を削減します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related