DALI:ローカルPCにおける効率的なMoE推論のためのワークロード認識型オフローディングフレームワーク
混合専門家(MoE)モデルの巨大なパラメータをローカルPCの限られたリソースで扱うため、CPUとGPUの計算資源を動的に最適化して併用する新しいオフローディングフレームワーク「DALI」が提案されました。
TL;DR(結論)
混合専門家(MoE)モデルの巨大なパラメータをローカルPCの限られたリソースで扱うため、CPUとGPUの計算資源を動的に最適化して併用する新しいオフローディングフレームワーク「DALI」が提案されました。 専門家の負荷(ワークロード)をリアルタイムで解析し、強欲アルゴリズムによる最適な計算割り当て、層間の残差情報を活用した高精度なプリフェッチ、過去の負荷傾向に基づくキャッシュ管理を導入することで、通信と計算のボトルネックを解消しています。 既存の最先端フレームワークと比較して、プリフィル段階で最大7.62倍、デコーディング段階で最大3.97倍の高速化を達成し、高価なサーバー級ハードウェアに頼らずに大規模な言語モデルを効率的に実行することを可能にしました。
なぜこの問題か
近年、MixtralやDeepSeek、Qwenといった大規模言語モデル(LLM)において、混合専門家(MoE)アーキテクチャが広く採用されています。MoEは、計算量を比例して増やすことなくモデルの容量を大幅に拡大できるという利点がありますが、その一方で総パラメータ数が膨大になるという課題を抱えています。この膨大なパラメータは、メモリ容量の限られたGPUを搭載したローカルPCでの展開を困難にしています。例えば、NVIDIA H100のようなハイエンドサーバーは80GBのメモリと高速な帯域を備えていますが、その導入コストは20万ドルを超え、多くのユーザーにとって手が届きません。対照的に、RTX 3090や4090を搭載したローカルPCは手頃な価格ですが、ビデオメモリ(VRAM)は24GBから32GB程度に制限されており、PCIe帯域幅もサーバー級に比べると大幅に狭いのが現状です。 このメモリ不足を解消するために、モデルのパラメータをメインメモリ(DRAM)などの二次記憶に逃がす「オフローディング」という手法が注目されています。…
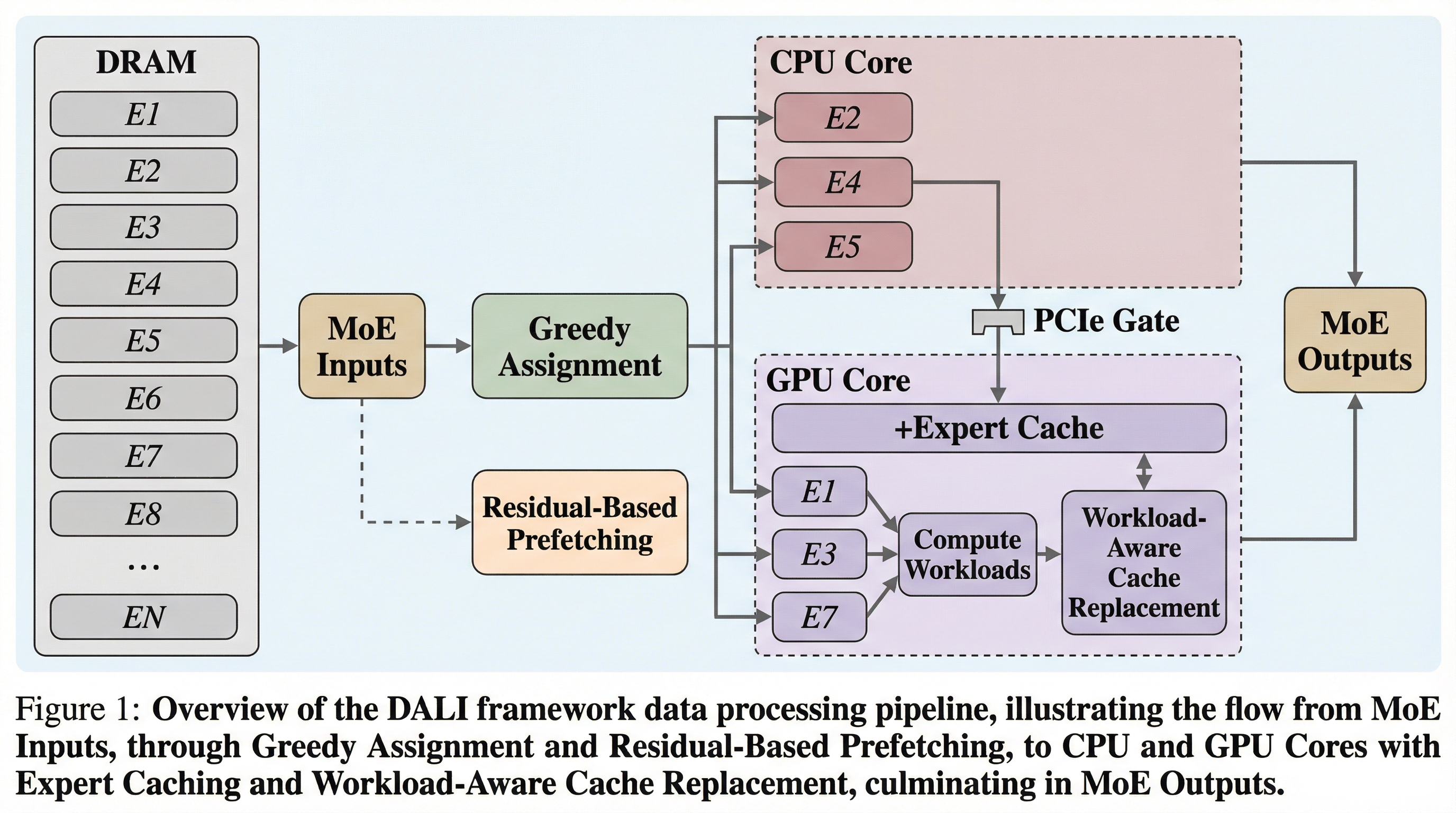
核心:何を提案したのか
本論文では、ローカルPC上での効率的なMoE推論を実現するために、ワークロード認識型のオフローディングフレームワークである「DALI」を提案しています。DALIの核心は、MoEの専門家が持つ「ワークロード(負荷)」の動的な変化を、計算の割り当て、データの事前転送、およびキャッシュ管理のすべての階層で考慮に入れた点にあります。 具体的には、まずCPUとGPUの異種計算資源を最大限に活用するために、専門家の割り当て問題を「0-1整数最適化問題」として定式化しました。これにより、実行時のオーバーヘッドを最小限に抑えつつ、システムの並列性を引き出す最適なスケジュールを導き出します。次に、プリフェッチの精度を向上させるために、層間の「残差(Residual)」情報を利用した新しい予測手法を導入しました。これにより、次にどの専門家が高い負荷を持つかをより正確に特定できるようになります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related