FlowPrefill:LLMサービングのプリフィルで起きる先頭行(HoL)ブロッキングを、プリエンプションとスケジューリング粒度の分離で抑える
多様なSLOが混在する同時リクエスト環境では、計算集約的なプリフィルで長い入力がGPUを占有し、短く高優先度の要求まで詰まらせてTTFTのSLO違反を連鎖させやすいため、プリフィル起因のHoLブロッキング対策がサービス品質を左右します。
TL;DR(結論)
- 多様なSLOが混在する同時リクエスト環境では、計算集約的なプリフィルで長い入力がGPUを占有し、短く高優先度の要求まで詰まらせてTTFTのSLO違反を連鎖させやすいため、プリフィル起因のHoLブロッキング対策がサービス品質を左右します。
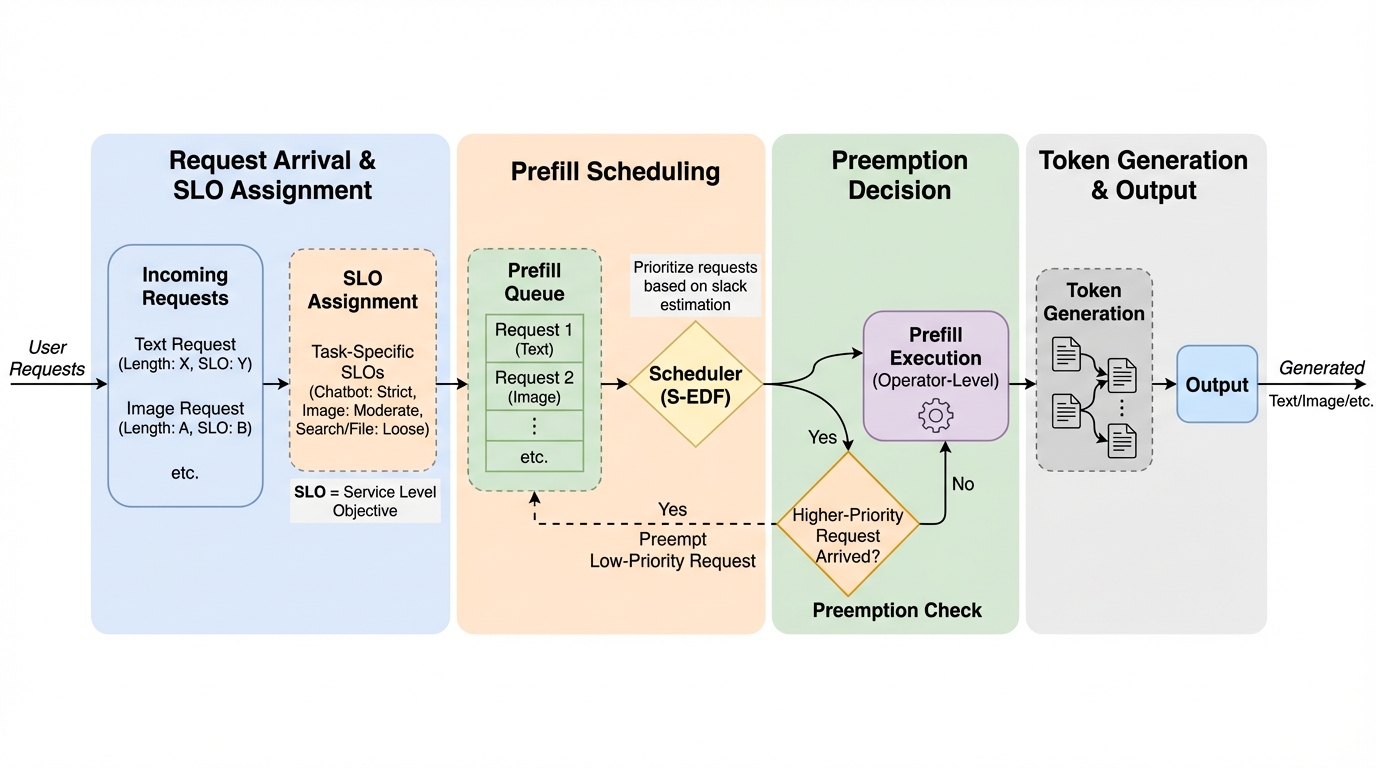
- FlowPrefillは、固定チャンクのように粒度を先に決め打ちせず、オペレータ境界で細粒度に割り込めるプリエンプションと、到着・完了イベント時だけ判断するイベント駆動スケジューリングを組み合わせ、応答性とスループットの衝突をほどきます。
- 実運用由来のプロダクショントレースで、異種SLOを満たしつつ最大goodputを最大5.6倍まで高め、さらにより厳しいSLOにも対応できることが示されており、PD disaggregationで集中しがちなプリフィル競合を抑える設計指針が得られます。
なぜこの問題か
大規模言語モデル(LLM)の利用が広がるにつれ、サービング側は多数の同時リクエストをさばきながら、ユーザーやタスクごとに異なるサービスレベル目標(SLO)を満たす必要があります。特に、最初のトークンが返るまでの時間であるTTFTは、対話の体感速度を決める指標として重視されています。推論は大きくプリフィルとデコードに分かれ、プリフィルは入力プロンプト全体を並列に処理してKV cacheを初期化し、デコードは自己回帰的にトークンを逐次生成します。計算特性も異なり、プリフィルは行列積(GEMM)が中心で計算律速になりやすい一方、デコードは行列ベクトル積(GEMV)が中心でメモリ帯域の影響を受けやすいと説明されています。 この非対称性を受け、プリフィルとデコードを別ハードウェアに分けるPD disaggregationが用いられ、デコードの遅延をプリフィルのバーストから守る狙いがあります。しかし分離により、すべてのリクエストのプリフィルが同じプリフィル側に集約されるため、長い入力のプリフィルが資源を長時間占有し、後続を待たせる先頭行(HoL)ブロッキングが悪化し得ます。…
核心:何を提案したのか
本論文が提案するFlowPrefillは、オンラインLLMサービングにおいてTTFTに関するgoodputを最大化することを目的としたサービングシステムです。ここでのgoodputは、SLO達成目標(例として90%が挙げられています)を満たしながら持続できる最大のリクエスト到着率として定義されています。問題の中心は、プリフィルのHoLブロッキングを抑えるには割り込み可能性が必要である一方、固定サイズのチャンク化などで粒度を小さくし過ぎると計算効率が落ち、逆に粒度を大きくし過ぎるとブロッキングが解消されないという、応答性とスループットのトレードオフにあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related