ChipBench: AIチップ設計におけるLLM性能を評価する次世代ベンチマーク
従来のVerilog評価ベンチマークが飽和し、最新のLLMが95%以上の合格率を達成する中で、産業レベルの複雑なチップ設計に対応するため、Verilog生成、デバッグ、リファレンスモデル生成の3つの重要タスクを網羅した「ChipBench」が提案されました。 本ベンチマークは、従来の3.8倍のコード長と13.
TL;DR(結論)
従来のVerilog評価ベンチマークが飽和し、最新のLLMが95%以上の合格率を達成する中で、産業レベルの複雑なチップ設計に対応するため、Verilog生成、デバッグ、リファレンスモデル生成の3つの重要タスクを網羅した「ChipBench」が提案されました。 本ベンチマークは、従来の3.8倍のコード長と13.9倍のセル数を持つ44の複雑なモジュール、89のデバッグ事例、132のリファレンスモデル用サンプルを含み、階層構造やCPU IPなどの現実的な設計課題をLLMに突きつけることで、モデル間の性能差を厳格に評価します。 検証の結果、最新のClaude-4.5-opusでもVerilog生成で30.74%、Pythonリファレンスモデル生成で13.33%という低い合格率に留まり、産業応用におけるLLMの大きな課題と、自動化ツールによる研究促進の可能性が示されました。
なぜこの問題か
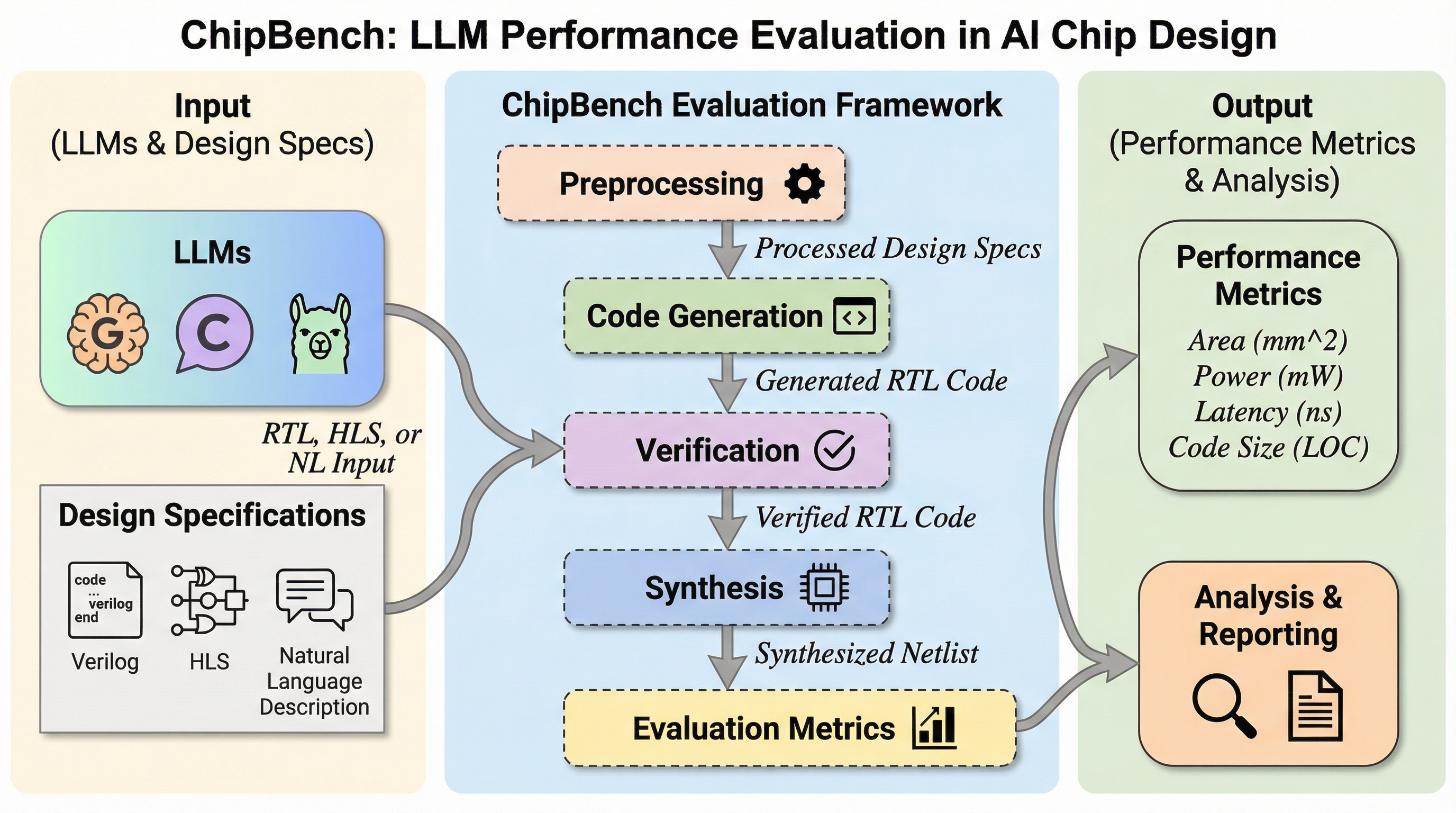
現在、大規模言語モデル(LLM)はハードウェア工学の分野で大きな可能性を示していますが、既存の評価指標には深刻な限界が存在します。VerilogEvalやRTLLMといった従来のベンチマークは、モデルの急速な進歩によって既に飽和状態にあり、最新の生成システムが95%以上の合格率を記録するなど、性能を正確に測定する機能を失いつつあります。これらの既存データセットに含まれるモジュールは、わずか10行から76行程度の極めて単純な機能に限定されており、他のサブモジュールを呼び出すことのない自己完結型の設計が中心となっています。しかし、実際の半導体産業における設計現場では、Verilogモジュールは1万行を超えることも珍しくなく、複数のサブモジュールを組み合わせて再利用する複雑な階層構造が一般的です。既存のベンチマークの多くは競技プログラミング形式の課題から派生したものであり、実際の産業プロジェクトで求められる機能やコーディングスタイルとは大きな乖離があるという問題も指摘されています。…
核心:何を提案したのか
本研究では、学術的なデータセットと産業界の複雑な要求との間の溝を埋めるために、包括的なベンチマークである「ChipBench」を提案しています。ChipBenchは、単なるコード生成能力の測定を超えて、チップ設計のワークフロー全体をカバーする3つの主要なタスクで構成されている点が特徴です。第一のタスクはVerilogコードの生成であり、オープンソースのCPU IPや競技プラットフォームから厳選された44のモジュールを使用し、自己完結型、非自己完結型、および実際のCPUサブモジュールの3つのカテゴリに分類して評価を行います。第二のタスクはVerilogのデバッグであり、タイミング、算術、代入、状態遷移の4つの主要なエラータイプを含む89のテストケースを通じて、LLMの修正能力を体系的に測定します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related