GEMM中心のNPUを超えて:拡散LLMサンプリングの効率化を実現するアーキテクチャ
拡散型大規模言語モデル(dLLM)は並列的なトークン生成を可能にするが、語彙全体にわたるロジット処理やトークン選択を行うサンプリング工程が、推論全体の遅延の最大71%を占める深刻なボトルネックとなっている。
TL;DR(結論)
拡散型大規模言語モデル(dLLM)は並列的なトークン生成を可能にするが、語彙全体にわたるロジット処理やトークン選択を行うサンプリング工程が、推論全体の遅延の最大71%を占める深刻なボトルネックとなっている。本研究が提案する「d-PLENA」は、従来の行列演算(GEMM)に特化したNPUの限界を打破するため、非GEMM型のベクトル演算プリミティブと、浮動小数点および整数ドメインを分離した混合精度メモリ階層を導入している。このアーキテクチャ最適化により、NVIDIA RTX A6000 GPUと比較して最大2.53倍の高速化を達成し、サイクル精度のシミュレーションとRTL検証を通じて、既存のPyTorch実装との機能的な等価性と高い実行効率が確認された。
なぜこの問題か
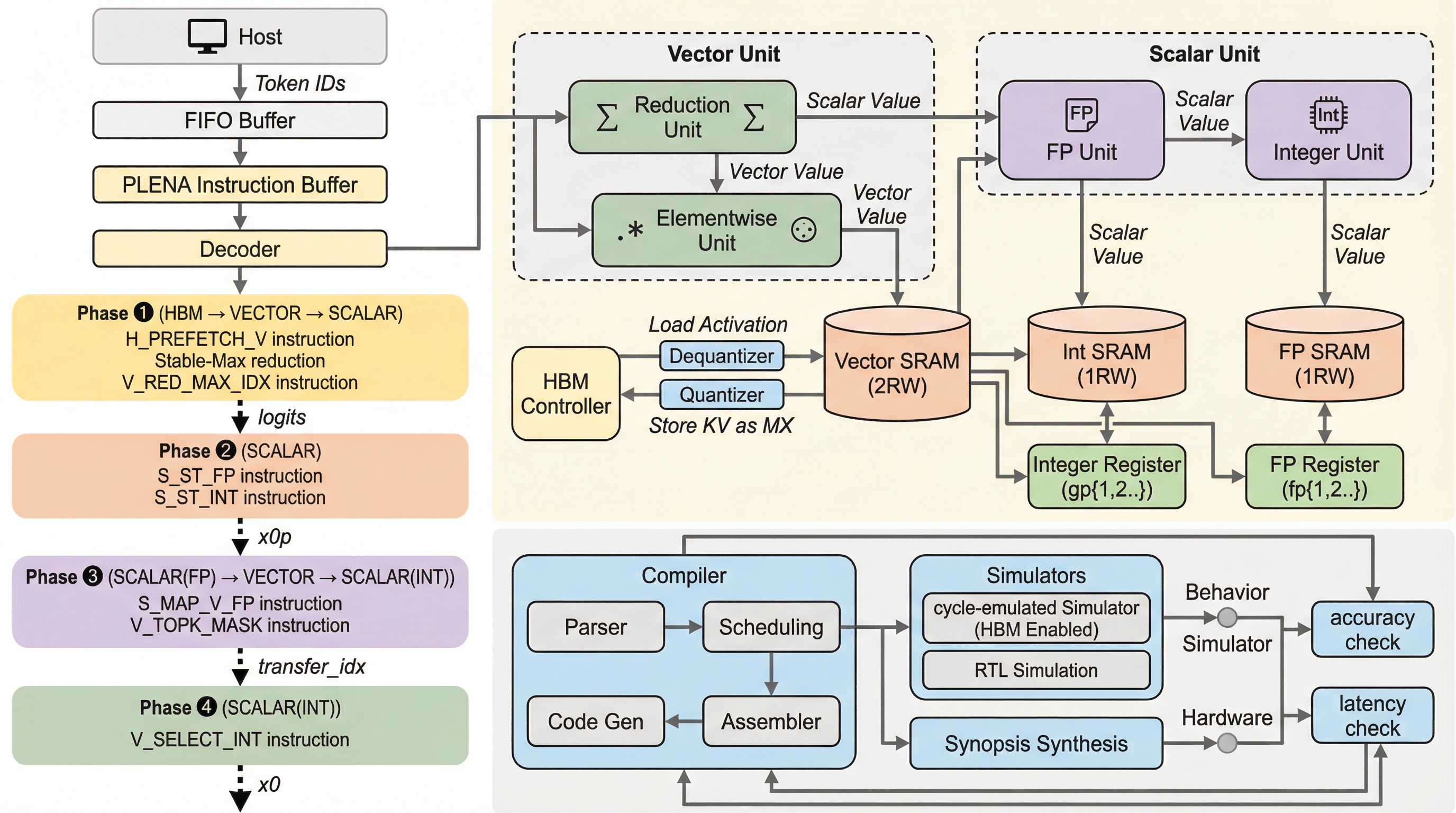
自己回帰型(AR)の大規模言語モデルは、トークンを一つずつ順番に生成する性質上、デコード処理においてメモリ帯域幅がボトルネックとなる課題を抱えている。これに対し、拡散型大規模言語モデル(dLLM)は、反復的なノイズ除去プロセスを通じて複数のトークンを並列に生成する手法を採用しており、計算密度を高めることでメモリ帯域の制約を緩和する期待が寄せられている。しかし、この新しい生成パラダイムは、システムレベルで新たな非効率性を生み出していることが判明した。最新のGPUを用いたプロファイリング調査によると、トランスフォーマー層の計算自体は浮動小数点演算の大部分を占めるものの、その後のサンプリング工程が推論全体の遅延において不釣り合いなほど大きな割合を占めている。具体的には、LLaDA-8B-InstructやLLaDA-MoE-7B-A1Bといった代表的なモデルにおいて、サンプリング工程の遅延は全体の最大71%に達している。 このサンプリング工程では、語彙全体にわたるロジットの処理、リダクションに基づくトークン選択、および不規則なメモリアクセスが発生する。…
核心:何を提案したのか
本研究は、dLLMのサンプリングを効率化するためのアーキテクチャ拡張として「d-PLENA」を提案している。これは、従来のGEMM中心の設計から脱却し、ベクトルおよびスカラー演算を最適化する命令セット(ISA)とメモリ構造を備えたものである。主な提案内容は、ハードウェアに適した実行フローの再構築、軽量な非GEMM命令プリミティブの導入、そしてデータ型ごとに分離された混合精度メモリ階層の3点に集約される。まず、数学的な等価性を維持しつつ、インプレース計算と段階的なメモリ再利用を可能にする「Stable-Max」定式化を導入した。これにより、従来のソフトマックス関数が必要としていた複数のメモリパスとグローバルな正規化処理を、ハードウェアモジュールに直接マッピング可能な原子的な操作に分解している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related