FineInstructions: 合成指示データを事前学習規模まで拡張する手法の提案
大規模言語モデル(LLM)の事前学習において、従来の非構造化テキストによる次単語予測ではなく、実際のユーザーのクエリに基づいた「指示と回答」のペアを10億件以上の規模で合成し、それを用いてゼロから学習を行う手法「FineInstructions」が提案された。
TL;DR(結論)
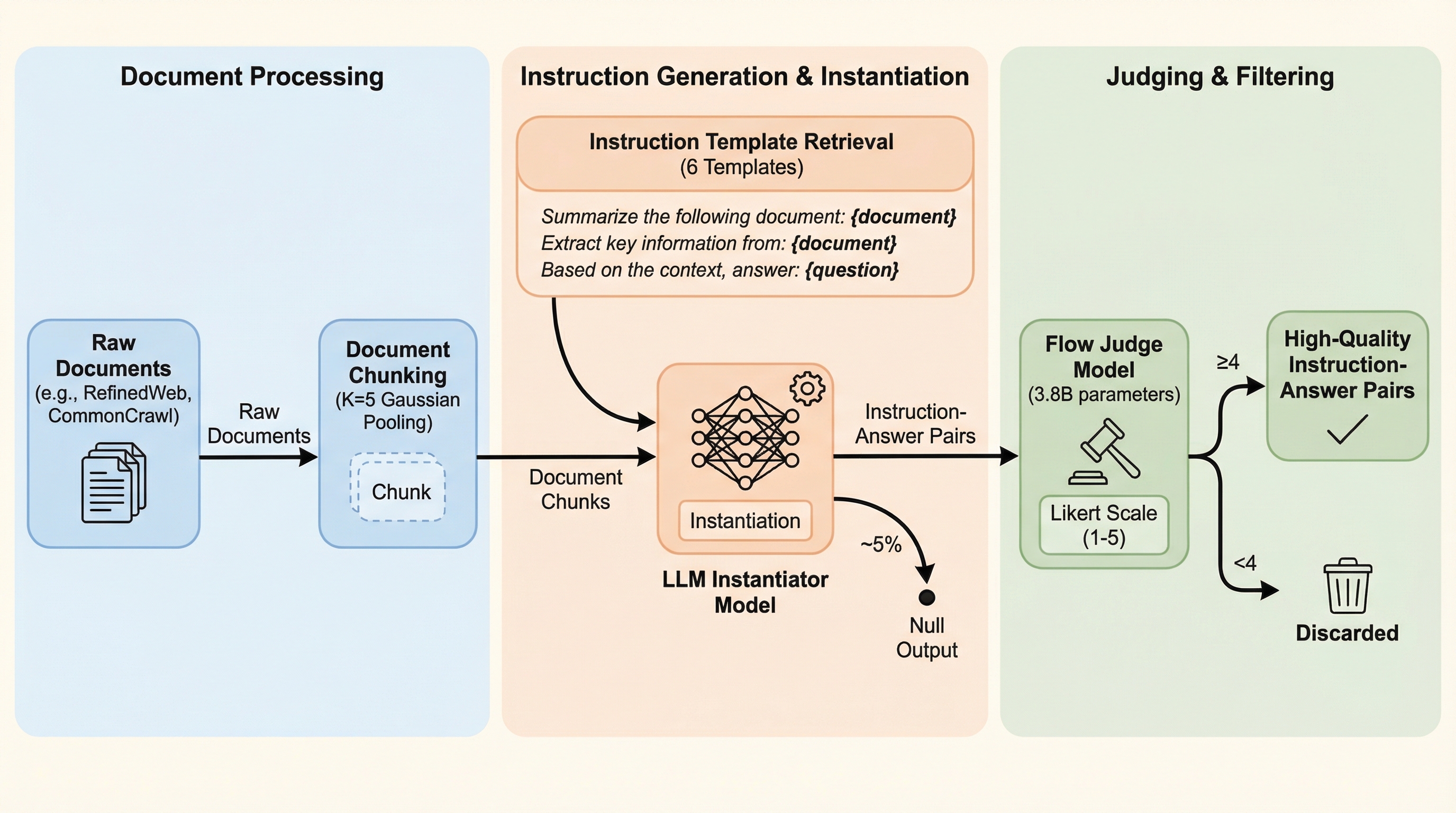
大規模言語モデル(LLM)の事前学習において、従来の非構造化テキストによる次単語予測ではなく、実際のユーザーのクエリに基づいた「指示と回答」のペアを10億件以上の規模で合成し、それを用いてゼロから学習を行う手法「FineInstructions」が提案された。 この手法では、約1800万件のリアルなユーザーの質問を汎用的なテンプレートに変換し、事前学習用の膨大な文書群と照合させることで、文書の内容に根ざした高品質な回答を自動生成し、教師あり学習の形式で事前学習を遂行する。 検証の結果、この「教師あり事前学習」は、従来の自己教師あり学習や他の合成データ手法と比較して、自由形式の回答品質を測定するベンチマークにおいて優れた性能を示し、モデルの知識吸収の効率と下流タスクへの適応性を大幅に向上させることが確認された。
なぜこの問題か
現在の大規模言語モデル(LLM)の学習プロセスは、主に二つの段階に分かれている。第一段階は、膨大な量の非構造化テキストデータを用いて「次の単語を予測する」という自己教師あり学習を行う事前学習フェーズである。第二段階は、比較的少量の「指示と回答」のペアを用いて、モデルをユーザーの意図に沿うように調整する指示チューニング(Instruction-tuning)フェーズである。しかし、この従来の枠組みにはいくつかの重大な課題が存在している。 まず、事前学習で用いられる「次単語予測」という目的関数は、モデルが知識を獲得する上では非常に強力だが、実際にユーザーがモデルを利用する際の「プロンプトに応答する」という形式とは乖離がある。このため、モデルが持つ知識を最大限に引き出すためには、指示チューニングが必要不可欠となる。しかし、高品質な教師ありデータは極めて限られており、既存のデータセットは数千件程度の小規模なものが多い。また、学術的なタスクを無理やり指示形式に変換したような非現実的なデータも多く、多様性や複雑さに欠けるという問題がある。…
核心:何を提案したのか
本研究では、インターネット規模の事前学習用文書を、数十億件規模の多様で現実的な「指示と回答」のペアに変換するパイプライン「FineInstructions」を提案している。この手法の核心は、実際のユーザーが書いた約1800万件ものクエリ(質問や依頼)を基にして、汎用的な「指示テンプレート」を作成し、それを事前学習用の文書と動的に組み合わせる点にある。 具体的には、WildChat、LMSys Chat、Reddit QA、GooAQといった多様なデータセットから収集された膨大なユーザーの問いかけを、特定の固有名詞や状況をプレースホルダー( タグ)に置き換えたテンプレートへと変換する。これにより、一つのテンプレートから、異なる文書の内容に合わせて無数の具体的な指示を生成することが可能になる。例えば、「AとBのどちらがよりCか?…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related