ユーザー編集からのLLMの原理に基づいたファインチューニング:選好、教師あり、報酬のメドレー
大規模言語モデル(LLM)のデプロイ後に得られる「ユーザーによる応答の編集」を、教師あり学習、選好学習、強化学習という3つの異なるフィードバック源として統合的に活用する新しい学習枠組みを提案しています。
TL;DR(結論)
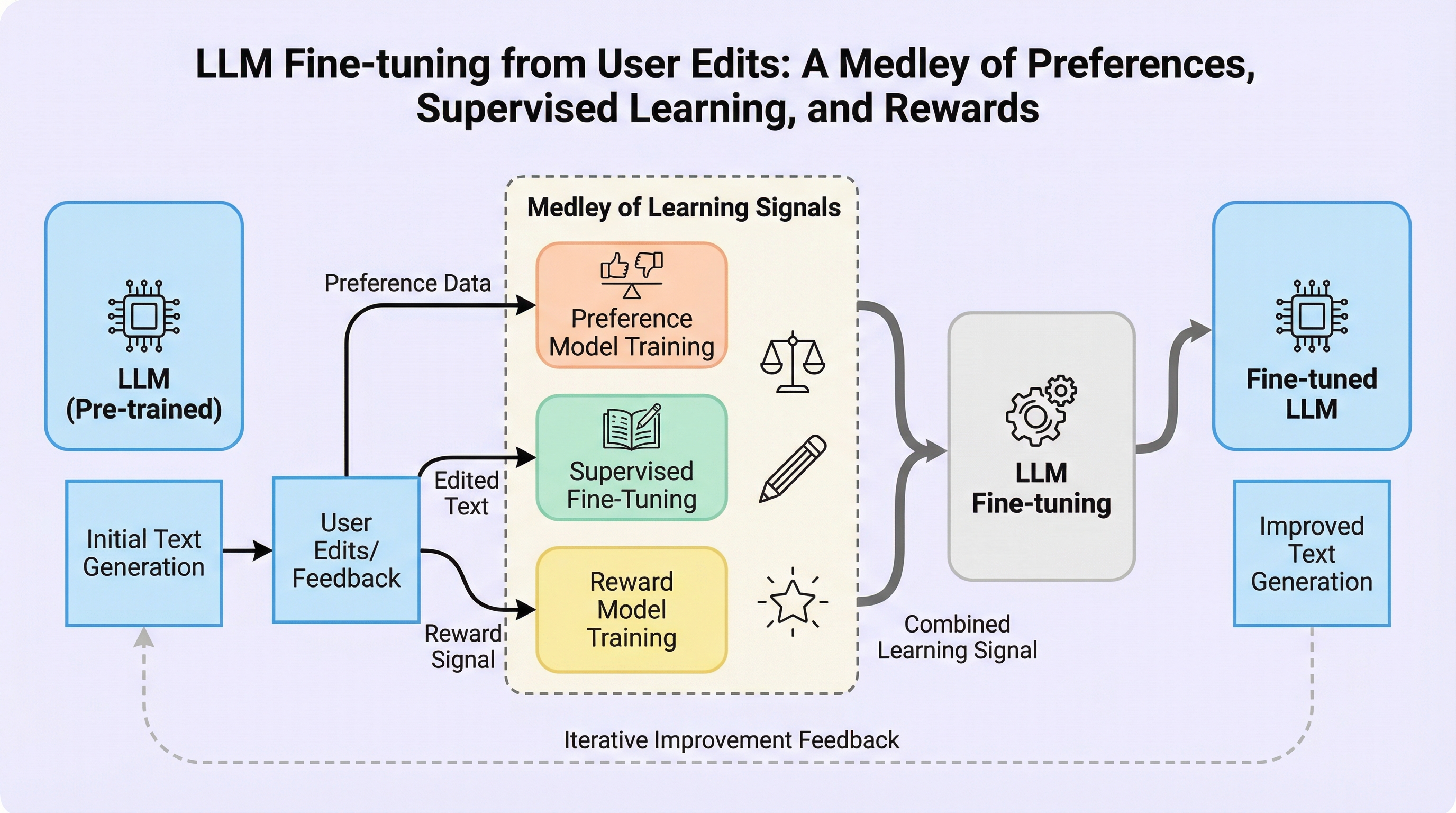
大規模言語モデル(LLM)のデプロイ後に得られる「ユーザーによる応答の編集」を、教師あり学習、選好学習、強化学習という3つの異なるフィードバック源として統合的に活用する新しい学習枠組みを提案しています。これは、ライティングアシスタントなどの実用的なアプリケーションで自然に発生する編集ログを、高コストな人間による注釈の代替として利用する画期的なアプローチです。 オフライン学習で各フィードバックから複数のモデルを構築し、オンライン評価時にバンディットアルゴリズム(UCB)を用いて最適なモデルを動的に選択する「レイト・アンサンブル」手法を導入しました。これにより、単一の学習手法では対応が困難な未知のユーザー分布や好みの変化に対しても、モデルが対話を通じて柔軟に適応し、編集コストを最小化することが可能になりました。 理論的解析を通じて、ユーザーの編集行動が特定の確率的バランスに従う場合に各手法が持つトレードオフを数学的に解明し、編集距離をコストとするオンライン学習において累積コストを最小化するための原理的な指針を提示しました。実験では、提案するアンサンブル手法が単一のフィードバックを用いた手法を凌駕し、分布のシフトに対しても極めて高い頑健性を示すことを実証しています。
なぜこの問題か
LLMを特定のタスクや個々のユーザーの好みに適応させる事後学習(Post-training)のプロセスにおいて、高品質なデータの確保は極めて重要な課題となっています。現在の主流な手法では、人間が作成した正解応答や、複数の応答から優れた方を選択する選好ラベルを収集するために、専門の注釈者を雇用する必要があります。しかし、このプロセスは非常に高コストであり、大規模なデータ収集を継続的に行うことは困難です。一方で、ライティングアシスタントやコーディング支援エージェントといった実際のアプリケーション運用中には、ユーザーがエージェントの不十分な応答を自ら修正する「ユーザー編集」という現象が日常的に発生しています。この編集データは、ユーザーが自身の問題を解決するために自発的に行うものであるため、追加のコストをかけずに自然に生成される極めて貴重なフィードバック源となります。 しかし、既存のLLMはあらかじめ全てのユーザーの潜在的な好みや特定のタスク要件に適応しているわけではありません。…
核心:何を提案したのか
本論文の核心的な提案は、ユーザーによる編集データを「教師あり学習(SFT)」「選好学習(DPO)」「強化学習(RL)」という、従来は個別に研究されてきた3つの異なるフィードバック形式が統合されたものとして定義し、それらを効果的に組み合わせる新しい学習プロトコルを導入した点にあります。具体的には、オフライン学習フェーズとオンライン学習フェーズの2段階から構成される「Protocol 1」を提案しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related