良いプレフィックスを救え:LLMの推論能力向上のためのプロセス監視強化学習による精密なエラーペナルティ
大規模言語モデル(LLM)の推論学習において、最終回答の正誤のみを報酬とする従来の強化学習では、誤答に含まれる「途中までの正しい思考(グッド・プレフィックス)」が不当に否定される課題がありました。
TL;DR(結論)
大規模言語モデル(LLM)の推論学習において、最終回答の正誤のみを報酬とする従来の強化学習では、誤答に含まれる「途中までの正しい思考(グッド・プレフィックス)」が不当に否定される課題がありました。本研究が提案する「Verifiable Prefix Policy Optimization (VPPO)」は、プロセス報酬モデル(PRM)を最初の誤り地点の特定にのみ利用し、正しい思考の断片に対してピンポイントで報酬を与えることで、学習の効率と推論の正確性を劇的に向上させます。複数の数学推論ベンチマークにおいて、VPPOは従来の強化学習手法や既存のプロセス報酬活用法を一貫して上回り、特に正解に到達するのが困難な難問において、サンプル複雑性を指数関数的なレベルから多項式レベルへと改善することに成功しました。
なぜこの問題か
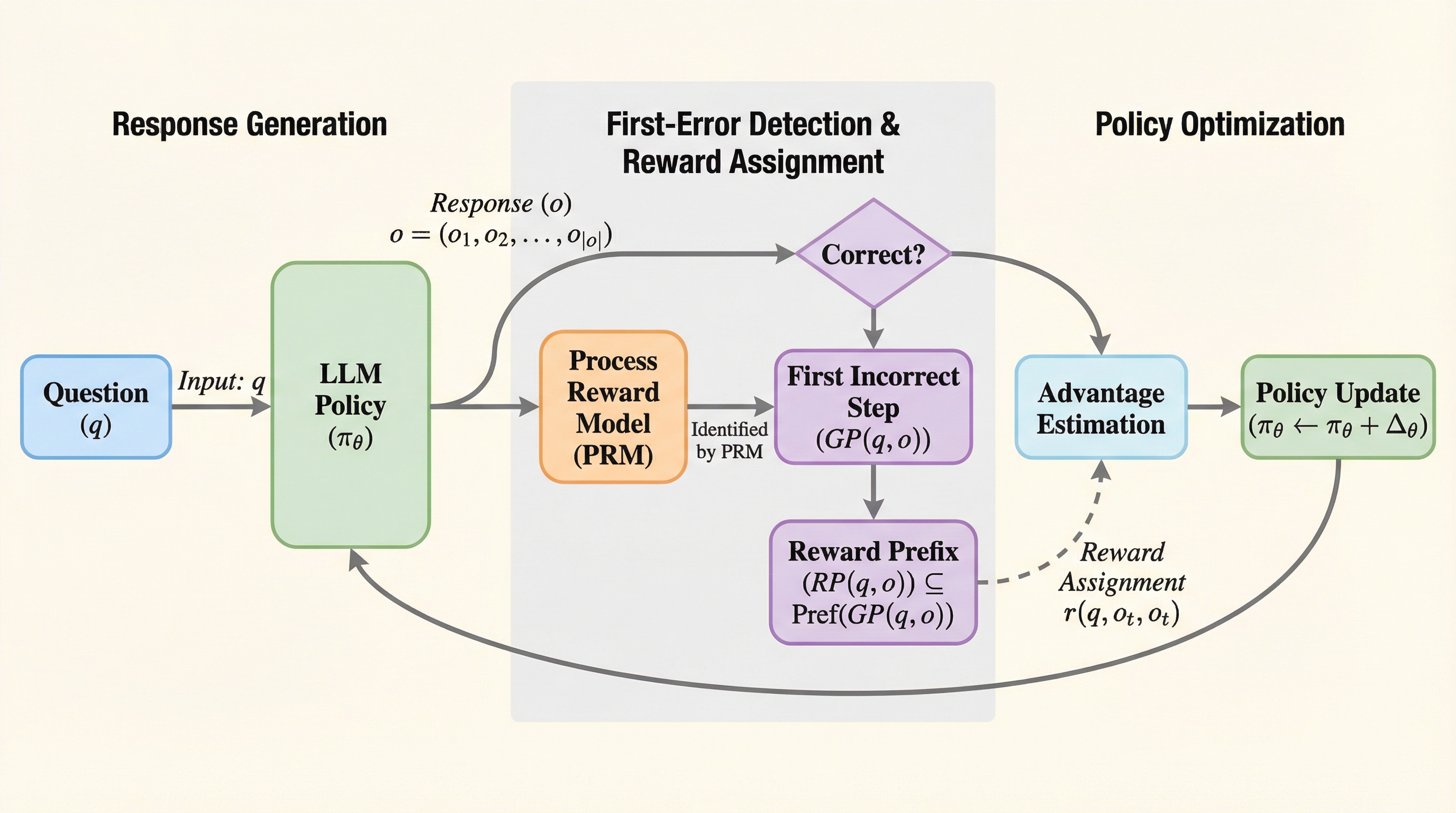
大規模言語モデルに複雑な多段階の推論を行わせる際、現在の強化学習手法(例えばGRPOなど)は、最終的な回答が正しいか否かという「疎な報酬」に過度に依存しています。このアプローチには深刻な「クレジット割り当て」の問題が伴います。具体的には、モデルが推論の大部分を正しく進めていたとしても、最後の最後で計算ミスなどの小さな誤りを犯して回答が不正解になった場合、その過程に含まれるすべての正しい推論ステップまでが否定的な学習信号を受けてしまいます。これにより、モデルは「何が正しかったのか」を正確に学習できず、学習の効率が著しく低下します。 プロセス報酬モデル(PRM)は、各中間ステップを評価することでこの問題を解決するために導入されましたが、PRMを強化学習に直接組み込むことには別の困難が伴います。既存の多くの手法は、PRMが出力するスコアをそのままステップごとの報酬として扱い、その累積値を最大化しようとしますが、PRMのスコア自体にはノイズが多く、バイアスがかかりやすいという性質があります。また、何をもって「良いステップ」とするかの客観的な基準が不明確であるため、学習信号が不安定になりがちです。…
核心:何を提案したのか
本研究では、PRMを「各ステップのスコア算出器」としてではなく、「最初の誤り検出器」としてのみ再定義し、新しい強化学習フレームワークである「Verifiable Prefix Policy Optimization (VPPO)」を提案しました。VPPOの核心的なアイデアは、誤った回答を「検証済みの正しいプレフィックス(グッド・プレフィックス)」と「誤ったサフィックス(後続部分)」に明確に分割し、正しい部分の末尾に対してのみ適切な報酬を与えるという、非常にシンプルかつ精密な設計にあります。 具体的には、PRMを用いて回答内の最初の誤りステップを特定します。そして、その誤りが発生する直前のステップの最後のトークンに対して、追加の報酬(ハイパーパラメータαで制御)を付与します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related