FROST:効率的な推論のためのアテンションを用いた推論外れ値のフィルタリング
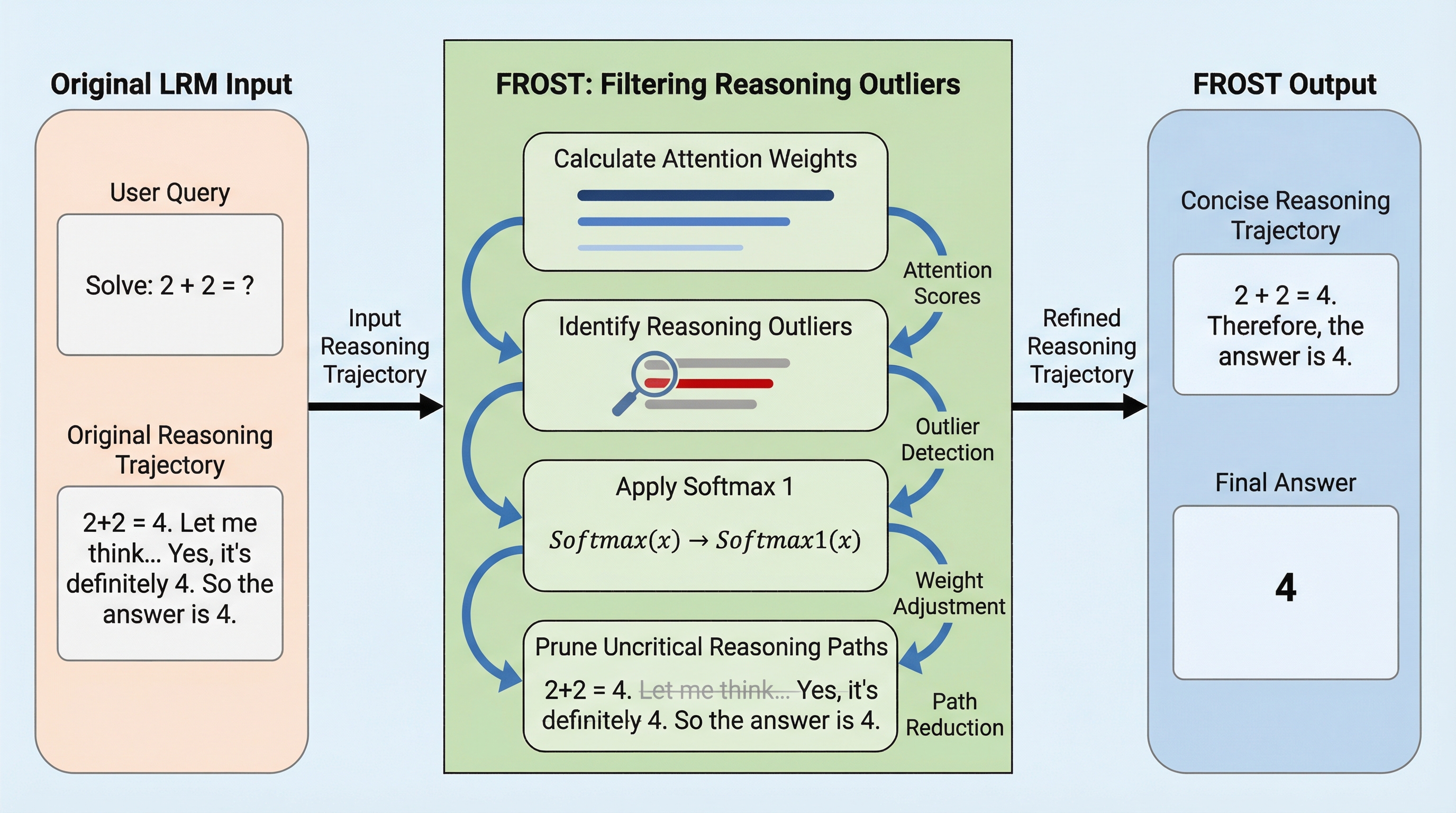
大規模推論モデル(LRM)が生成する冗長で無関係な推論ステップを「推論外れ値」と定義し、アテンション重みに基づいてこれらを動的に除去する新手法「FROST」を提案した。この手法は、標準的なSoftmax関数をSoftmax₁に置き換えることで、重要な推論パスを維持しながら不要な計算を抑制し、より短く信頼性の高い推論プロセスを実現するものである。 数学的な証明と実験的な検証の両面からアプローチしており、ベースモデルと比較してトークン使用量を平均69.68%削減しつつ、精度を26.70%向上させるという顕著な成果を達成した。また、推論時間を28.6%以上、学習時間を42.2%短縮することに成功しており、計算資源の制約がある環境下でも高度な推論能力を効率的に発揮できることを実証した。 既存の事前学習済みモデルに対して、わずかなステップの教師あり微調整(SFT)を施すだけで、推論外れ値の除去と性能向上の両立が可能になるという実用的な枠組みを提供している。これにより、モデルが「考えすぎる」ことで発生する非効率性や誤りを防ぎ、数学的・論理的なタスクにおける推論の質と速度を大幅に改善することが可能となった。
TL;DR(結論)
大規模推論モデル(LRM)が生成する冗長で無関係な推論ステップを「推論外れ値」と定義し、アテンション重みに基づいてこれらを動的に除去する新手法「FROST」を提案した。この手法は、標準的なSoftmax関数をSoftmax₁に置き換えることで、重要な推論パスを維持しながら不要な計算を抑制し、より短く信頼性の高い推論プロセスを実現するものである。 数学的な証明と実験的な検証の両面からアプローチしており、ベースモデルと比較してトークン使用量を平均69.68%削減しつつ、精度を26.70%向上させるという顕著な成果を達成した。また、推論時間を28.6%以上、学習時間を42.2%短縮することに成功しており、計算資源の制約がある環境下でも高度な推論能力を効率的に発揮できることを実証した。 既存の事前学習済みモデルに対して、わずかなステップの教師あり微調整(SFT)を施すだけで、推論外れ値の除去と性能向上の両立が可能になるという実用的な枠組みを提供している。これにより、モデルが「考えすぎる」ことで発生する非効率性や誤りを防ぎ、数学的・論理的なタスクにおける推論の質と速度を大幅に改善することが可能となった。
なぜこの問題か
近年、DeepSeek-R1やOpenAI o1、Gemini 2.0 Proといった大規模推論モデル(LRM)は、数学、コーディング、科学的な質問回答などの複雑なタスクにおいて非常に高い性能を示している。これらのモデルは、思考の連鎖(Chain-of-Thought)を用いることで、中間的な推論ステップを生成し、論理的な結論を導き出す能力に長けている。しかし、モデルのパラメータサイズが比較的小さい場合や、特定の学習条件下では、モデルが過度に詳細な推論チェーンを生成してしまう「考えすぎ(Overthinking)」の問題が発生することが指摘されている。この現象により、不必要なトレースバックや冗長な代替パス、過剰な自己検証が生成され、推論の効率が著しく低下するだけでなく、最終的な回答の品質や安全性に悪影響を及ぼす可能性がある。 既存の効率化手法には、トークンレベルでの予算制限を設ける手法や、強化学習を用いて短い推論パスに報酬を与える手法などが存在する。しかし、トークンレベルの削減手法は、推論の文脈において不可欠なステップまで削除してしまうリスクがあり、一方で文レベルの精緻化手法は計算コストや遅延が増大する傾向にある。…
核心:何を提案したのか
本論文では、アテンションを考慮した効率的な推論手法である「FROST(Filtering Reasoning Outliers with Attention for Efficient Reasoning)」を提案している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related