さらなる賭け:協力ジレンマにおける利得と言語がいかにLLMエージェントの戦略を形成するか
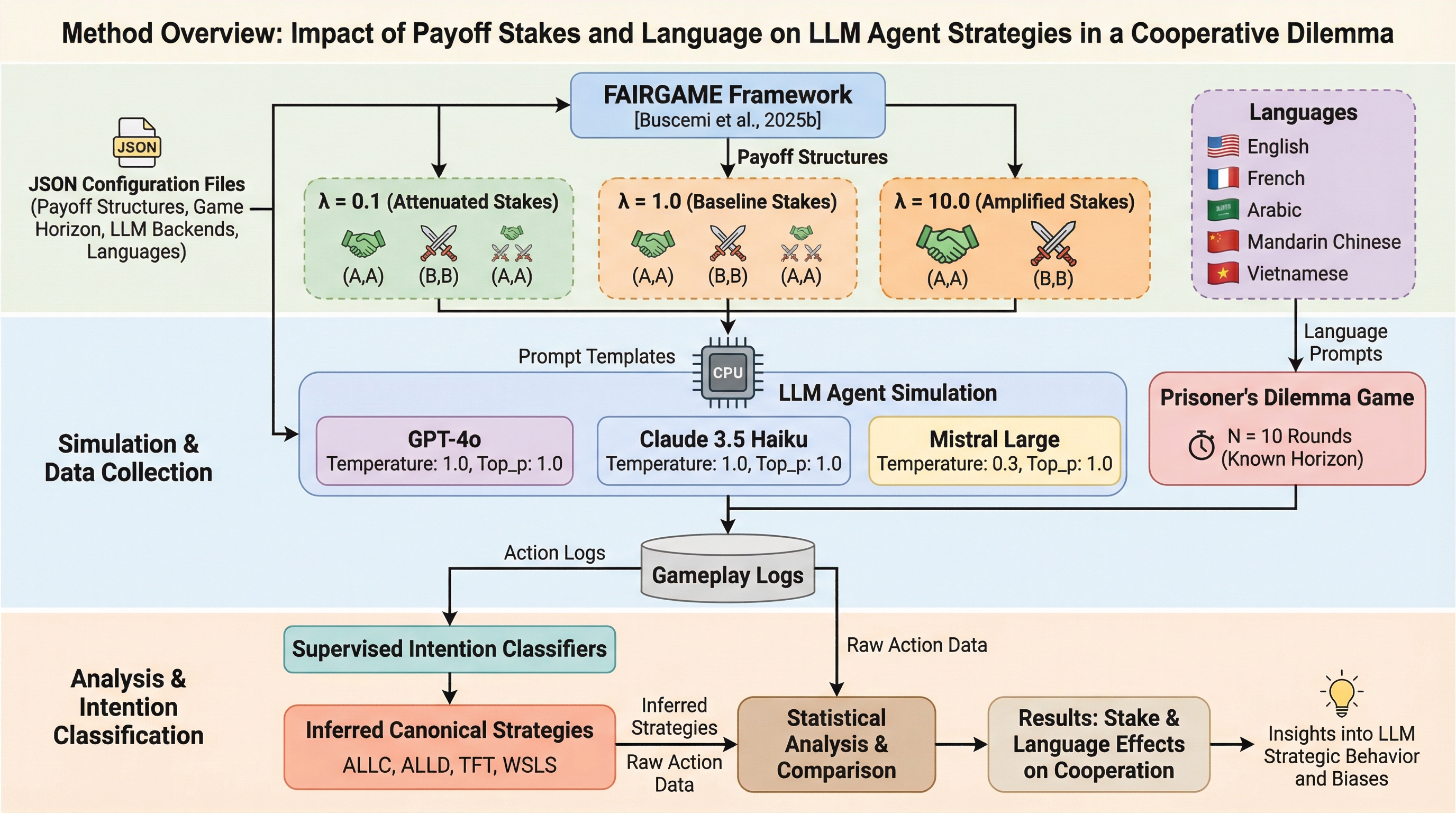
本研究は、大規模言語モデル(LLM)エージェントが繰り返される囚人のジレンマにおいて、利得の絶対的な大きさと提示される言語が戦略的行動にどのような影響を与えるかを、FAIRGAMEフレームワークを用いて詳細に分析した。
TL;DR(結論)
本研究は、大規模言語モデル(LLM)エージェントが繰り返される囚人のジレンマにおいて、利得の絶対的な大きさと提示される言語が戦略的行動にどのような影響を与えるかを、FAIRGAMEフレームワークを用いて詳細に分析した。 利得の規模を変動させた実験では、利得が小さい設定では裏切りが頻発する一方で、利得が大きくなると「しっぺ返し(TFT)」や「勝てば維持、負ければ変更(WSLS)」といった洗練された条件付き戦略が増加する傾向が示された。 言語の影響も顕著であり、英語とベトナム語で協力率が逆転する現象や、アラビア語や中国語で特定のモデルが裏切りやすくなるなど、言語的な文脈がモデルの設計と同等かそれ以上の影響を意思決定に及ぼすことが判明した。
なぜこの問題か
大規模言語モデル(LLM)は、推薦システムや交渉ツール、マルチエージェント型のアシスタントとして、自律的なエージェントとしての役割を急速に広げている。このような環境において、LLMは単独での出力ではなく、他者との相互作用から生じる戦略的な行動を求められる協力のジレンマに直面することが多い。AIが主導する社会システムや経済システムにおいて、これらのエージェントがどのように振る舞うかを理解することは、システムの安全性や調整、ガバナンスの観点から極めて重要である。これまでの研究では、トレーニングやプロンプト、役割の割り当て、言語的なフレーミングがLLMの行動を形成することが示されてきたが、現実世界の多様なシナリオにおいて、利得の大きさ、すなわち「賭け金」の変化に対してAIがどのように適応するかについては十分に解明されていない。既存の評価手法の多くは、協力率や利得の分布といった表面的な結果に焦点を当てており、その背後にある行動の意図や意思決定のルールを直接モデル化できていないという課題がある。ガバナンスやアライメントのために戦略的行動を評価するには、表面的な出力を超えた分析手法が必要とされている。…
核心:何を提案したのか
本研究では、LLMエージェントの戦略的行動を監査するための統一的なフレームワークを提案し、利得の大きさと多言語性が戦略に与える影響を調査した。具体的には、囚人のジレンマという古典的なゲームの構造を維持したまま、利得の数値のみをスカラーパラメータによって倍増または縮小させる「利得スケール型囚人のジレンマ」を導入した。これにより、戦略的な構造や最適応答を変化させることなく、相互作用の「重み」だけを変化させ、LLMがインセンティブの強さにどれほど敏感であるかを分離して測定することが可能となった。さらに、観察された行動の背後にある意図を解釈するために、教師あり学習を用いた戦略分類器を導入した。これは、過去の相互作用の履歴からエージェントが採用している決定ルールを推測する手法である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related