AIフィードバックによる強化学習を用いた音声対話システムにおける会話品質の最適化
従来の音声対話システムにおける強化学習は、主に発話レベルの単一な意味的報酬に限定されており、音声の自然さや感情の一貫性といった多面的な品質を十分に最適化できていませんでした。本研究では、意味的な整合性に加えて、音声品質(UTMOS)、明瞭性(WER)、感情の一貫性という複数の報酬を統合した、音声入出力対話システムのための新しいマルチ報酬RLAIFフレームワークを提案しています。この手法は、逐次的に応答を生成するデュプレックス(全二重)モデルにも対応しており、複数の評価指標において一貫した品質向上を実現するとともに、研究の再現性を支援するための大規模なデータセットも公開されます。
TL;DR(結論)
従来の音声対話システムにおける強化学習は、主に発話レベルの単一な意味的報酬に限定されており、音声の自然さや感情の一貫性といった多面的な品質を十分に最適化できていませんでした。本研究では、意味的な整合性に加えて、音声品質(UTMOS)、明瞭性(WER)、感情の一貫性という複数の報酬を統合した、音声入出力対話システムのための新しいマルチ報酬RLAIFフレームワークを提案しています。この手法は、逐次的に応答を生成するデュプレックス(全二重)モデルにも対応しており、複数の評価指標において一貫した品質向上を実現するとともに、研究の再現性を支援するための大規模なデータセットも公開されます。
なぜこの問題か
音声対話システム(SDS)は、従来のターン制の音声アシスタントから、聞きながら話すことが可能なリアルタイムの全二重(デュプレックス)対話エージェントへと急速に進化しています。エンドツーエンドのアーキテクチャや音声基盤モデル、そしてデュプレックスデコーディングの進歩により、より自然な相互作用や低遅延の会話フローが可能になりました。しかし、これらのモデル構造の進歩にもかかわらず、人間が好むような会話行動、すなわち意味的な一貫性、自然な韻律、感情的に整合した表現、そして応答性の高いターン交代を実現することは依然として大きな課題として残されています。システムが高度化するにつれて、タイミングや韻律、あるいは意味的な逸脱といった小さなエラーがターンの経過とともに蓄積され、ユーザー体験を直接的に低下させる要因となります。 これまで、テキストベースの対話モデルやカスケード型のシステムにおいて、人間やAIのフィードバックによる強化学習(RLHF/RLAIF)を事後学習として適用する試みは行われてきました。しかし、エンドツーエンドの音声対話システムに対する系統的な嗜好学習の研究は不足しています。…
核心:何を提案したのか
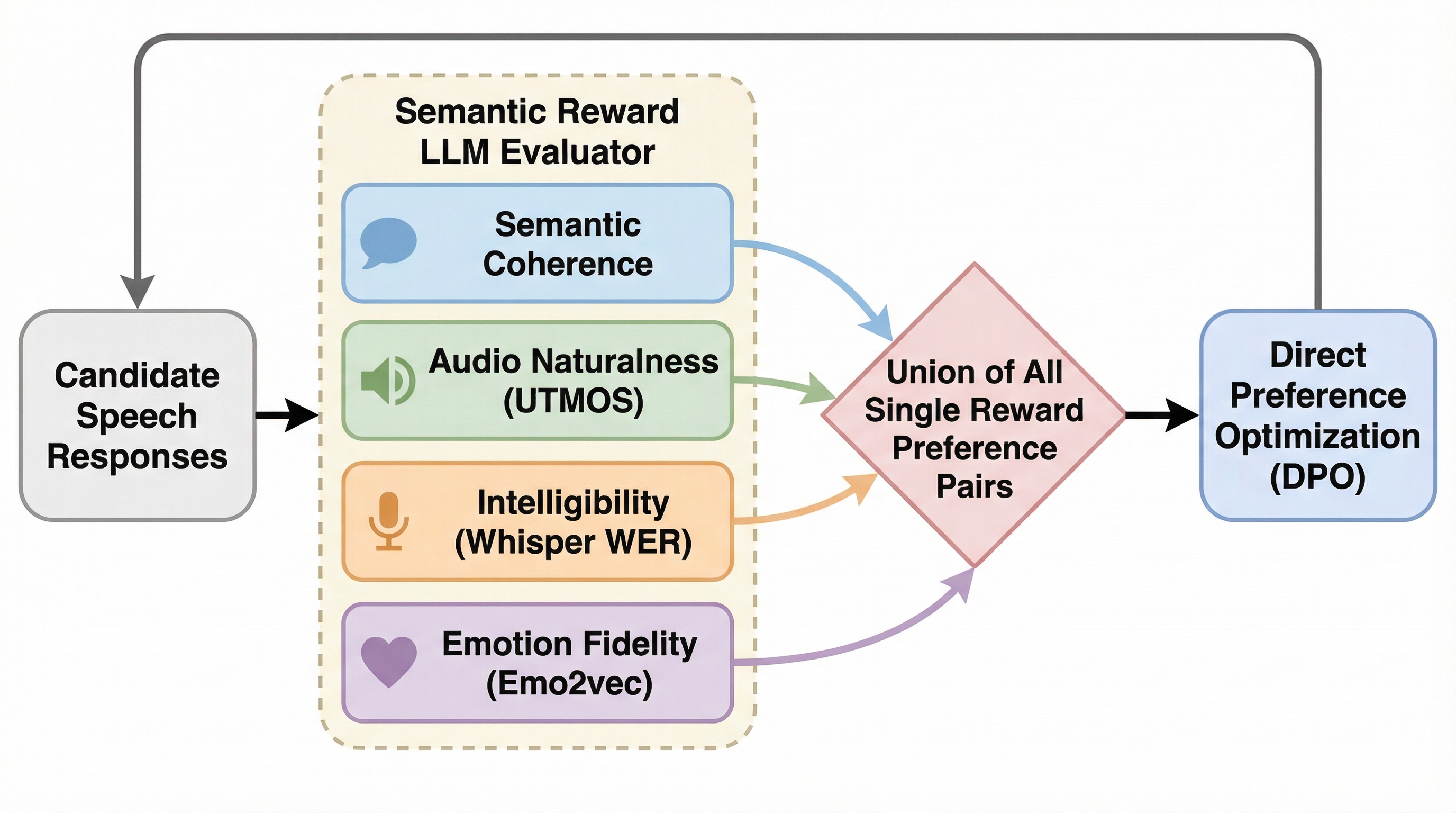
本研究では、音声入出力対話システムのために、意味的な品質、音声の自然さ(UTMOS)、明瞭性、および感情の忠実度を単一の嗜好学習パイプライン内で共同で最適化する、初のマルチ報酬RLAIFフレームワークを提案しています。このフレームワークは、従来のターン制の対話モデルだけでなく、ストリーミング形式で応答を生成するデュプレックスモデルにも適用可能な汎用性の高い設計となっています。具体的には、意味的な整合性を評価するLLMベースの報酬、音声の自然さを推定するUTMOS、音声の明瞭さを測定する単語誤り率(WER)、そして人間の参照音声との感情的な類似性を評価する感情報酬という、独立した四つの嗜好データセットを構築しました。 これらのデータセットを直接嗜好最適化(DPO)のプロセスで共同でサンプリングすることにより、モデルは複数の相補的な目的を同時に学習することが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related