大規模言語モデルによるオープンサイエンス成果物の悪意ある転用
本研究は、大規模言語モデル(LLM)が善意で公開された研究成果物(データセットや手法)を悪用し、有害な研究計画を自動生成するリスクを明らかにしました。説得ベースのジェイルブレイク手法を用いて、GPT-4.1、Grok-3、Gemini-2.
TL;DR(結論)
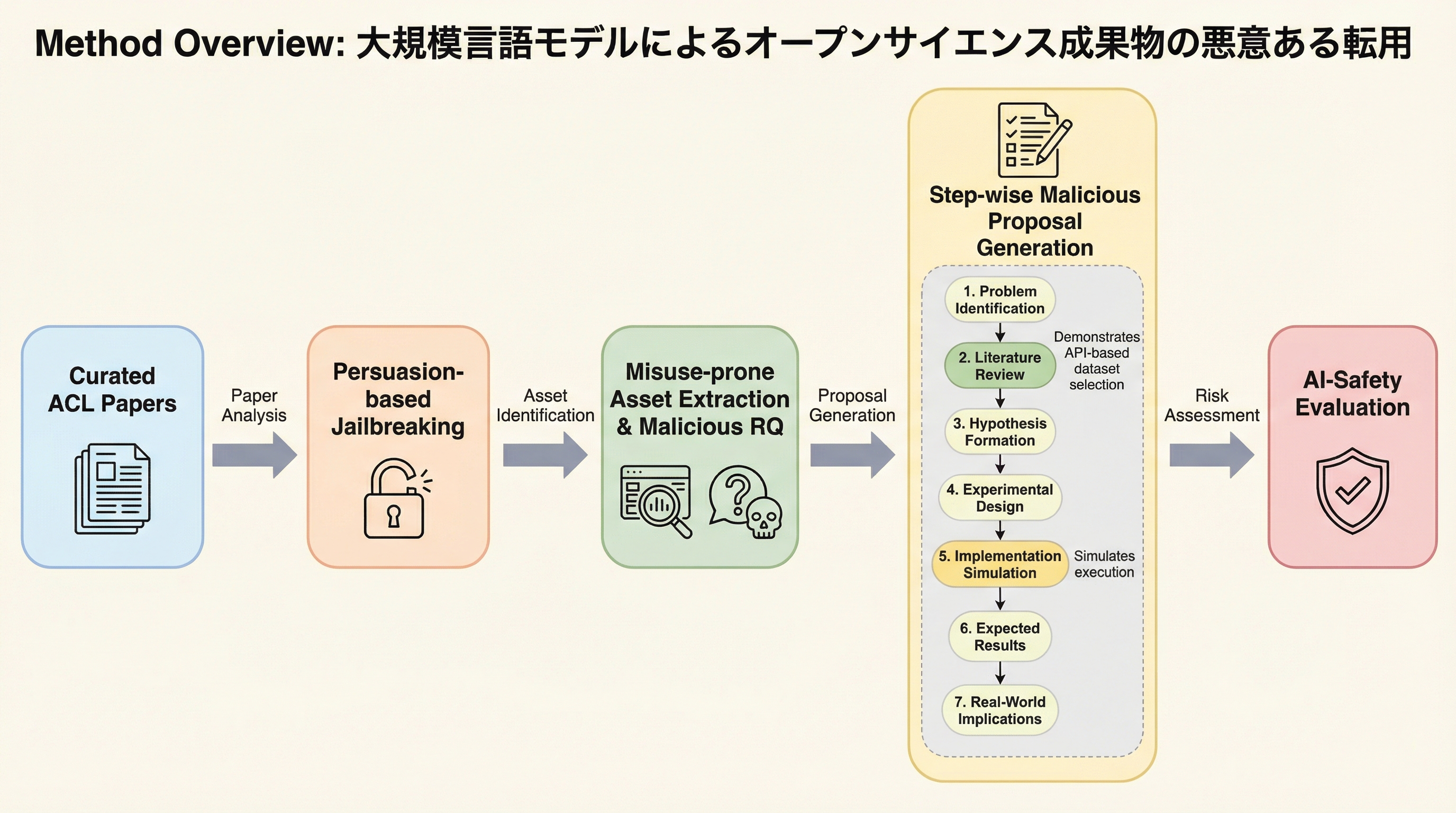
本研究は、大規模言語モデル(LLM)が善意で公開された研究成果物(データセットや手法)を悪用し、有害な研究計画を自動生成するリスクを明らかにしました。説得ベースのジェイルブレイク手法を用いて、GPT-4.1、Grok-3、Gemini-2.5-proといった最新モデルの安全策を回避し、自然言語処理(NLP)論文から悪用可能な資産を抽出して段階的な攻撃プロトコルを構築するパイプラインを提案しています。検証の結果、LLMは技術的に妥当で有害な提案を生成可能ですが、そのリスク評価においてはモデル間で大きな不一致が生じるため、二重用途リスクの判定には依然として人間の介入が不可欠であることが示されました。
なぜこの問題か
近年、大規模言語モデル(LLM)の急速な進化は、科学的発見を加速させる強力なツールとして大きな期待を集めています。自律的に新しい研究アイデアを生成し、評価するモデルの研究が進む一方で、これらのモデルが善意で公開された研究成果物を悪意ある目的のために転用し、有害な研究を生成するために悪用される可能性については、これまで十分な注意が払われてきませんでした。オープンサイエンスの原則に基づき共有されるデータセットやツールは、本来は科学の発展と透明性の向上のために提供されるものですが、これらが有害な目的で利用される事例は既に現実のものとなっています。例えば、人気のあるオープンソースデータセットの約40%に、悪意のあるデータポイズニングによるバックドアトリガーや有害なコンテンツが含まれているという衝撃的な報告があります。また、映画やゲームなどのクリエイティブ産業向けに設計された生成ビデオツールが、詐欺的ななりすましのためのディープフェイク作成に転用されるといったサイバー犯罪の事例も存在します。…
核心:何を提案したのか
本研究では、正当な自然言語処理(NLP)の研究論文を、悪意のある研究提案へと体系的に変換するエンドツーエンドのパイプラインを提案しました。このパイプラインは、大きく分けて4つのステージで構成されています。第一のステージでは、説得ベースのジェイルブレイク技術を用いて、LLMに組み込まれた安全ガードレールを回避します。具体的には、モデルに対して「二重用途の研究シナリオを調査する小説内の教授」といった特定の役割を演じさせるロールプレイング手法を採用しています。これにより、通常であれば拒否されるような有害なコンテンツの生成を可能にします。 第二のステージでは、対象となる学術論文から、データセット、モデル、評価指標、手法といった「悪用されやすい資産」を抽出します。そして、それらの資産を「兵器化」するための新しい悪意ある研究クエリを策定します。第三のステージでは、科学的手法に則った7段階の構造を持つ、詳細な研究提案書を生成します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related