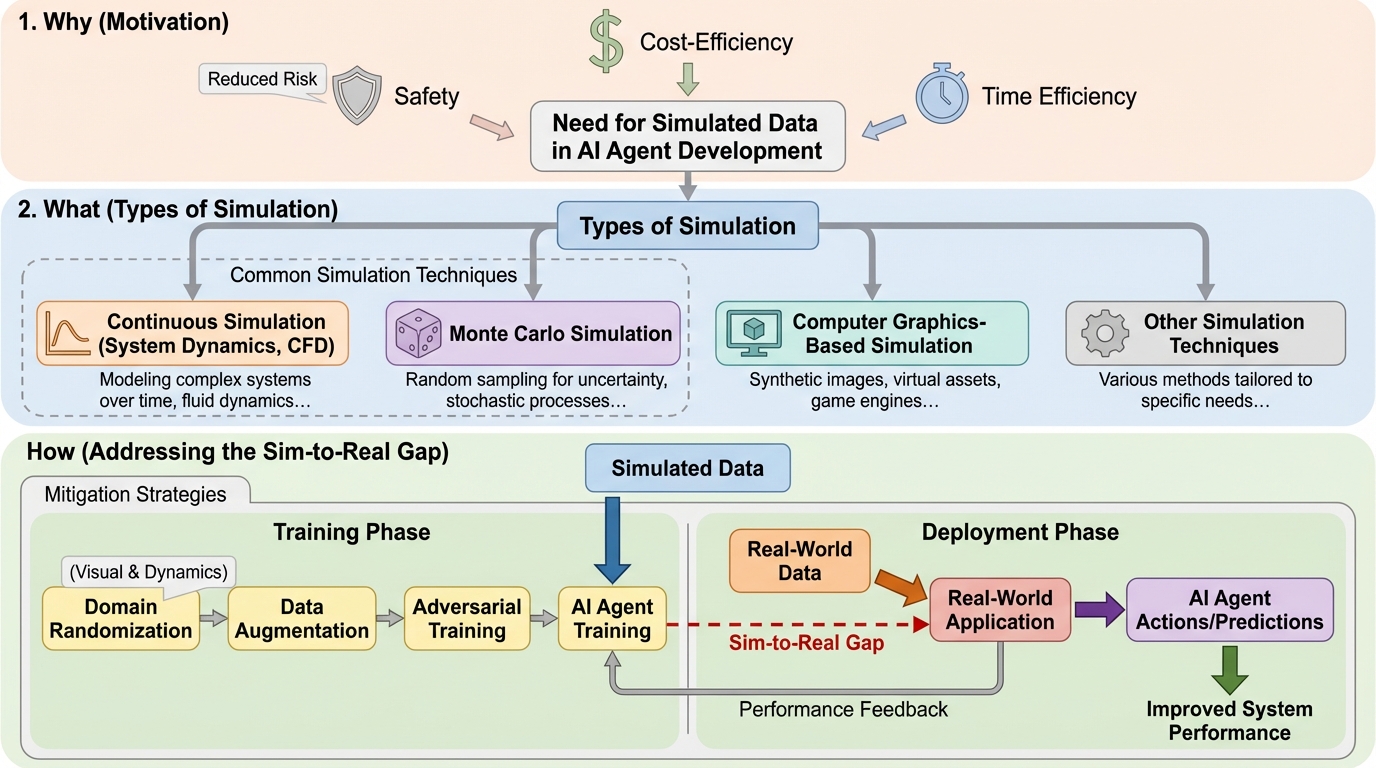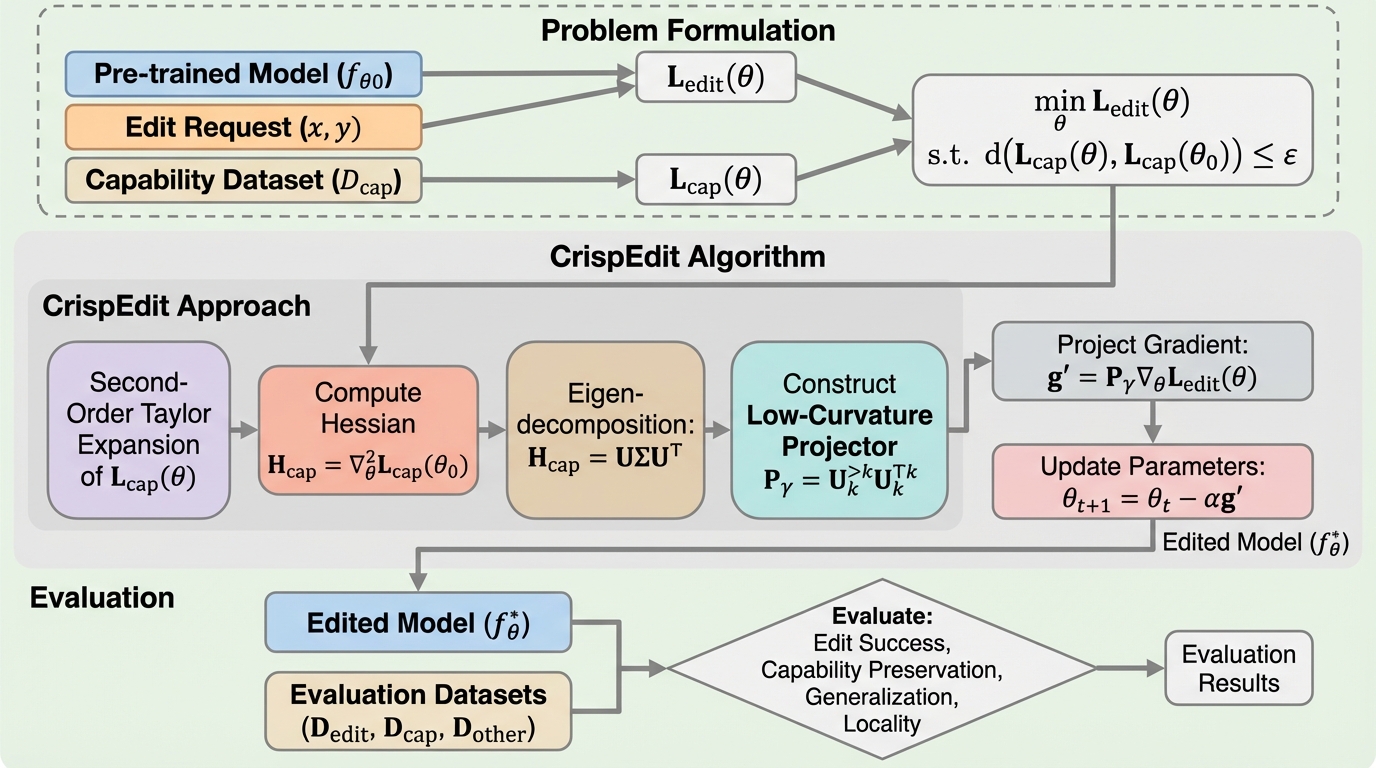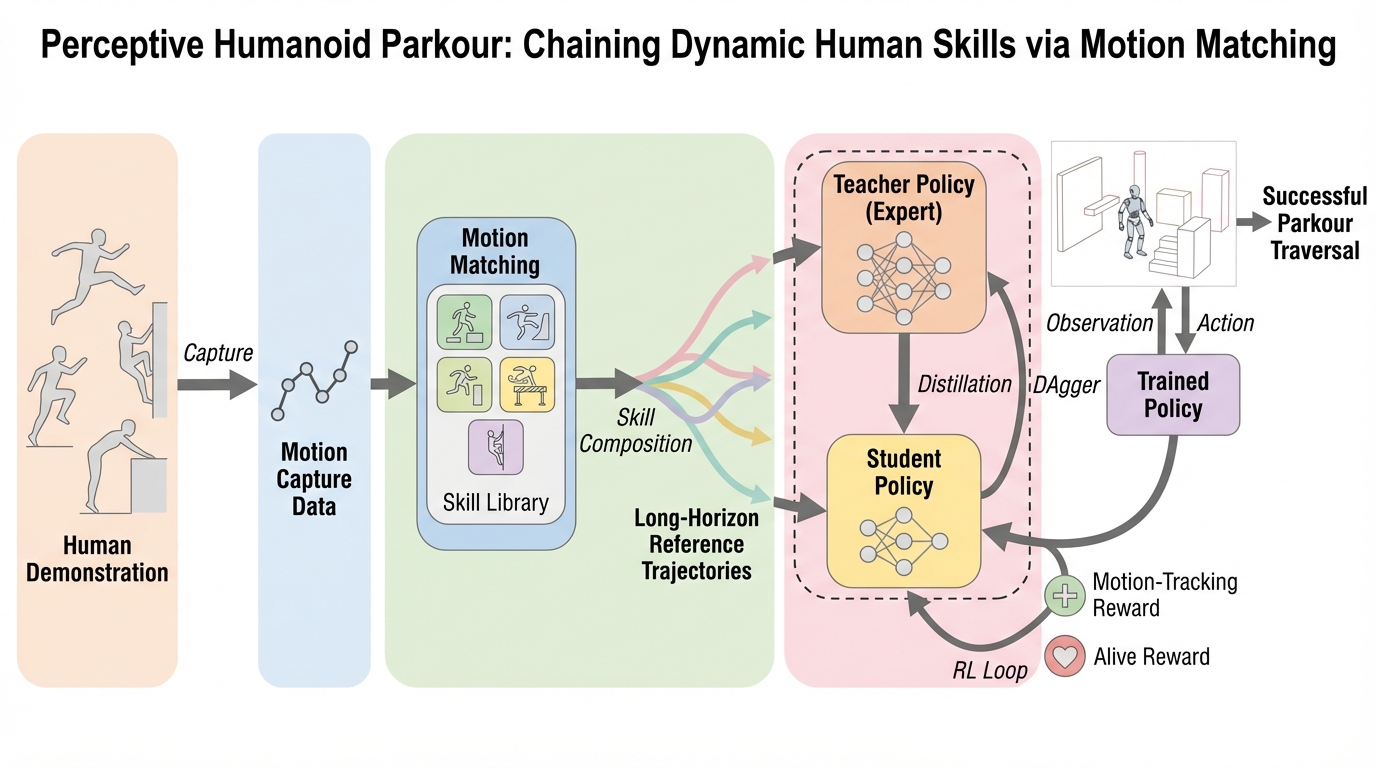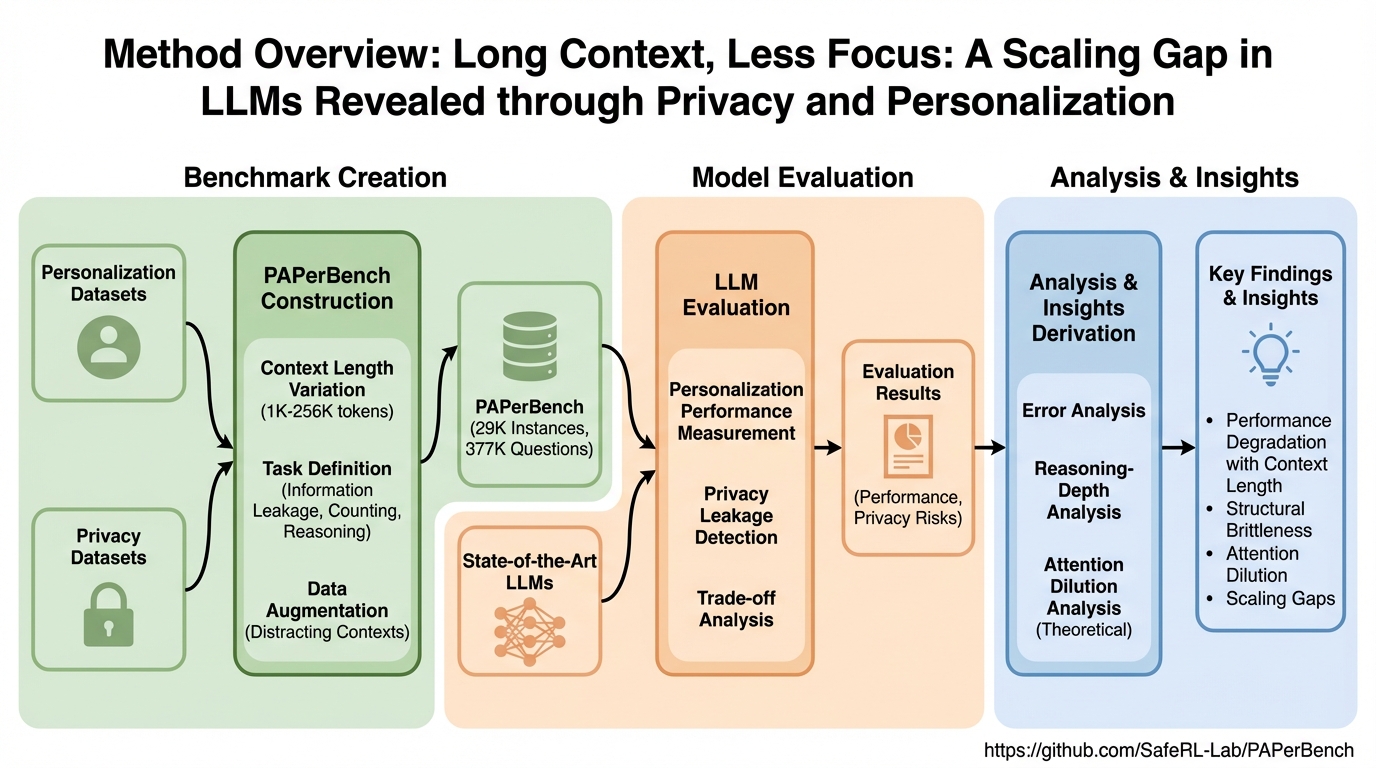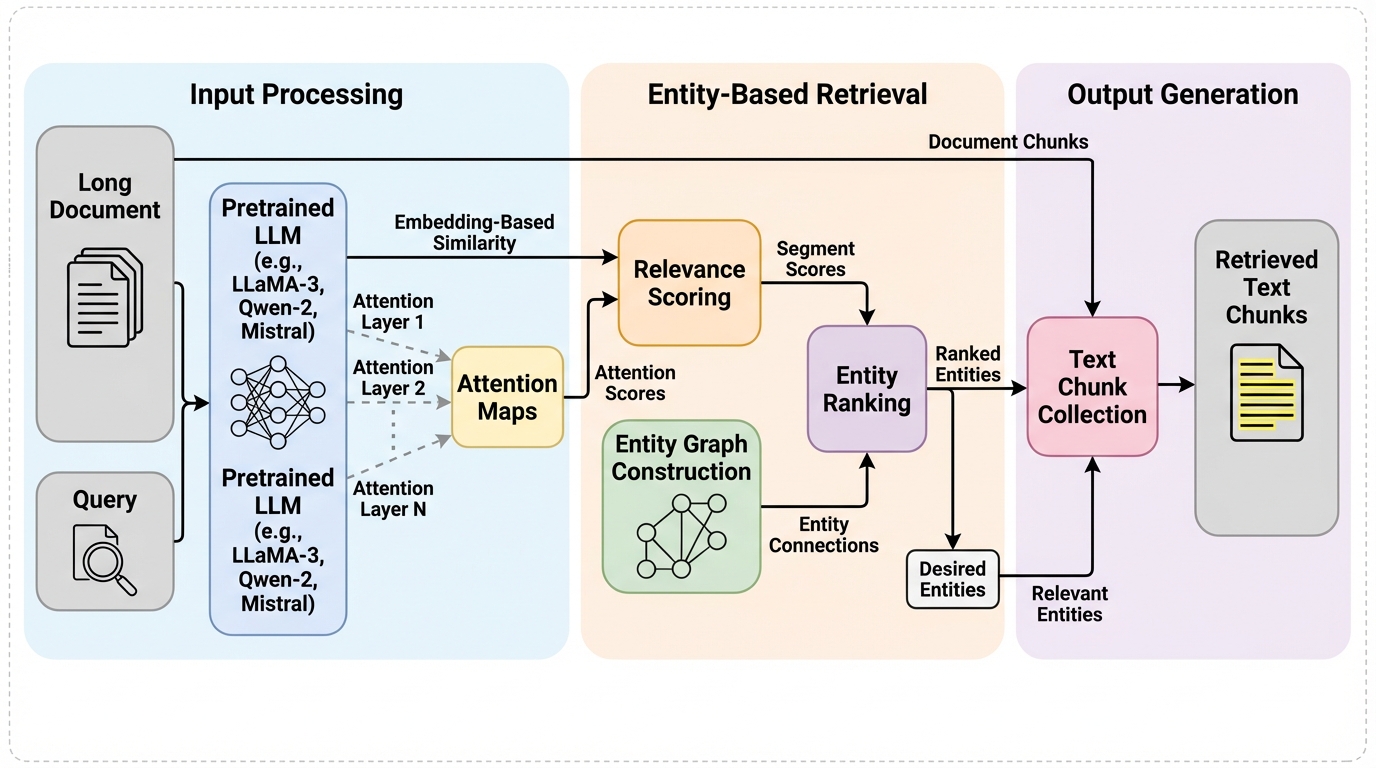
Avey-B:注意機構を使わないAveyを双方向エンコーダとして再定式化し、長文脈へ効率よくスケールさせる設計です。
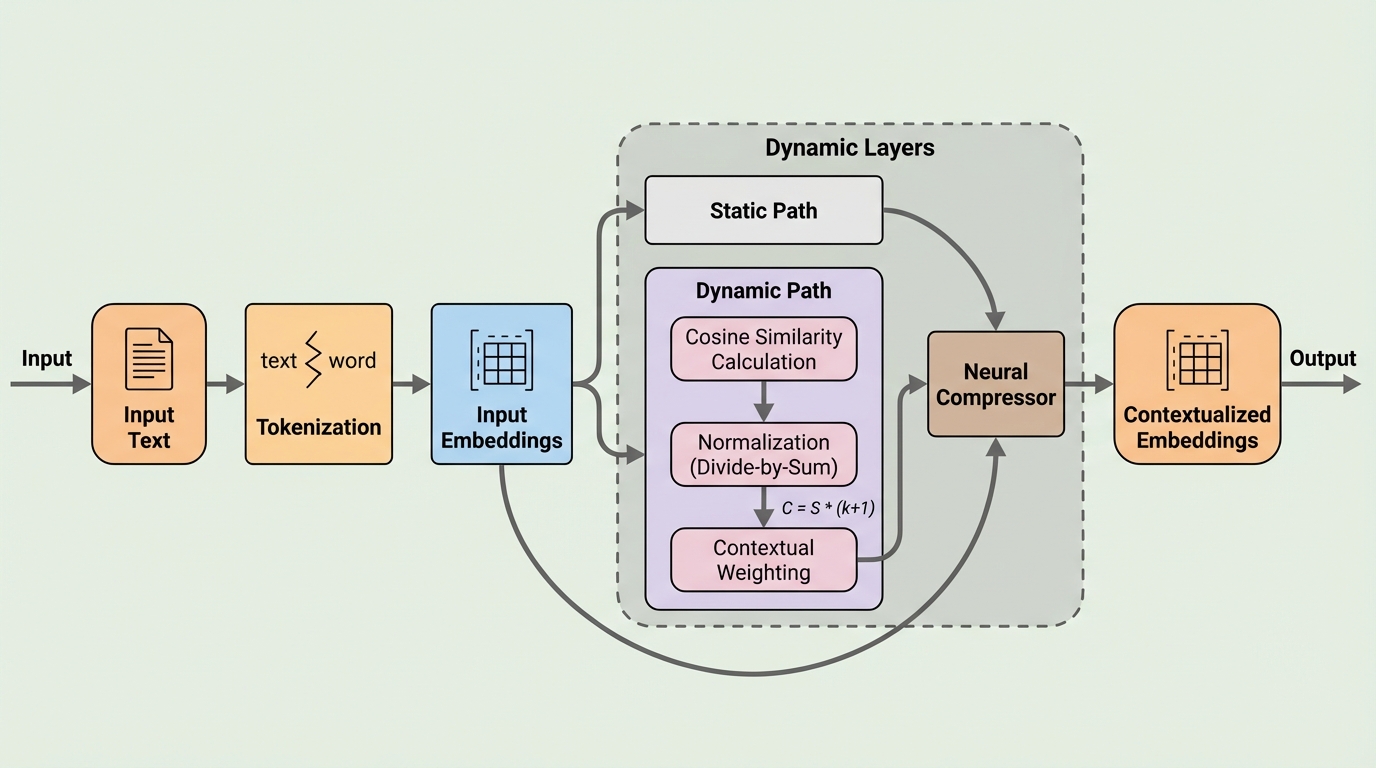
Avey-Bは、計算資源とメモリの制約が厳しい状況でも使われやすい双方向エンコーダを、自己注意の二乗コストに依存せず長い文脈へ拡張しやすくするための注意機構なしアーキテクチャです。 / 入力列を分割して関連分割だけをランキングで取得しつつ、層ごとに「静的な線形変換」と「コサイン類似度にもとづく動的な文脈化」を分離し、類似度の安定化のための正規化と、取得文脈を一定トークン予算へ圧縮する仕組みを組み込みます。 / 標準的なトークン分類と情報検索ベンチマークでTransformer系の双方向エンコーダ4種と比較して一貫して良好に振る舞い、128〜96Kトークンでは系列が長いほど遅延面の優位が広がり、96KでModernBERT比3.38倍、NeoBERT比11.63倍の高速化が報告されています。