
言語の共起統計にある「平行移動対称性」が、モデル表現の幾何を形づくる
大規模言語モデルの内部表現で、月が円環状に並ぶ、年が滑らかな一次元のまとまりになる、都市の緯度経度が線形な読み出しで復号できるといった幾何学的構造が現れる理由を、学習データ側の二語共起統計から説明する枠組みが示されています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルの内部表現で、月が円環状に並ぶ、年が滑らかな一次元のまとまりになる、都市の緯度経度が線形な読み出しで復号できるといった幾何学的構造が現れる理由を、学習データ側の二語共起統計から説明する枠組みが示されています。
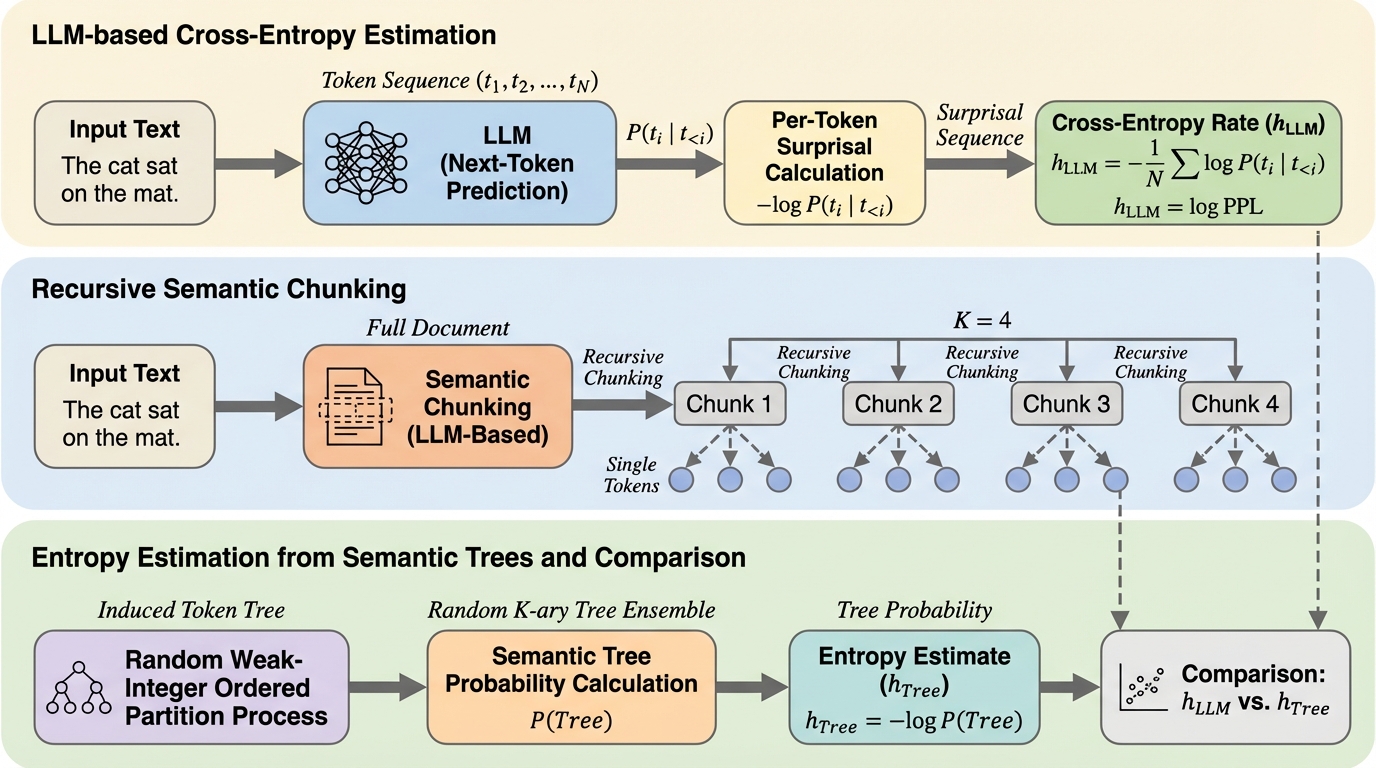
印刷された英語のエントロピー率が「約1ビット/文字」と推定されるほど小さいことは、ランダムなテキストに期待される「約5ビット/文字」と比べて大きな冗長性を含むことを意味し、その理由を意味の階層構造から説明しようとしています。 / 大規模言語モデルを使って文書を意味的に一貫した塊へ再帰的に分割し、トークンを葉にもつ「意味木」を作ったうえで、最大分岐数Kだけで定まるランダムなK分木アンサンブルにより、その木が現れる確率を計算できる形にします。 / 意味木の確率から得た理論的なエントロピー率の推定は、次トークン確率から得るクロスエントロピー推定と多様なコーパスで近くなり、さらにエントロピー率は固定ではなくコーパスの意味的複雑さに応じて系統的に増えるという見通しを示します。
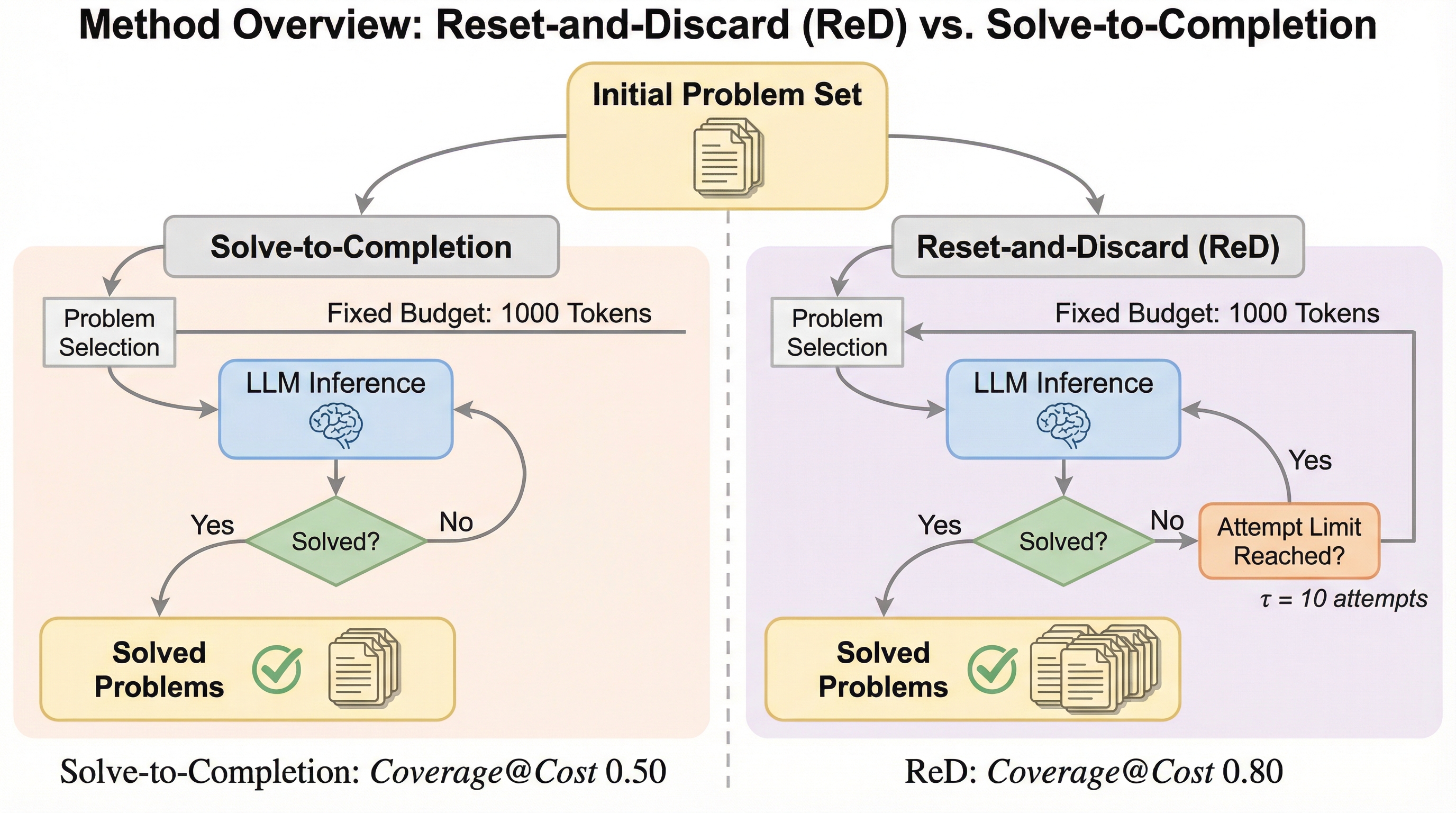
大規模言語モデル(LLM)の性能評価を、従来の1問あたりの成功率(pass@k)から、限られた総予算内で解決できるユニークな問題数(coverage@cost)へと転換することを提案しています。
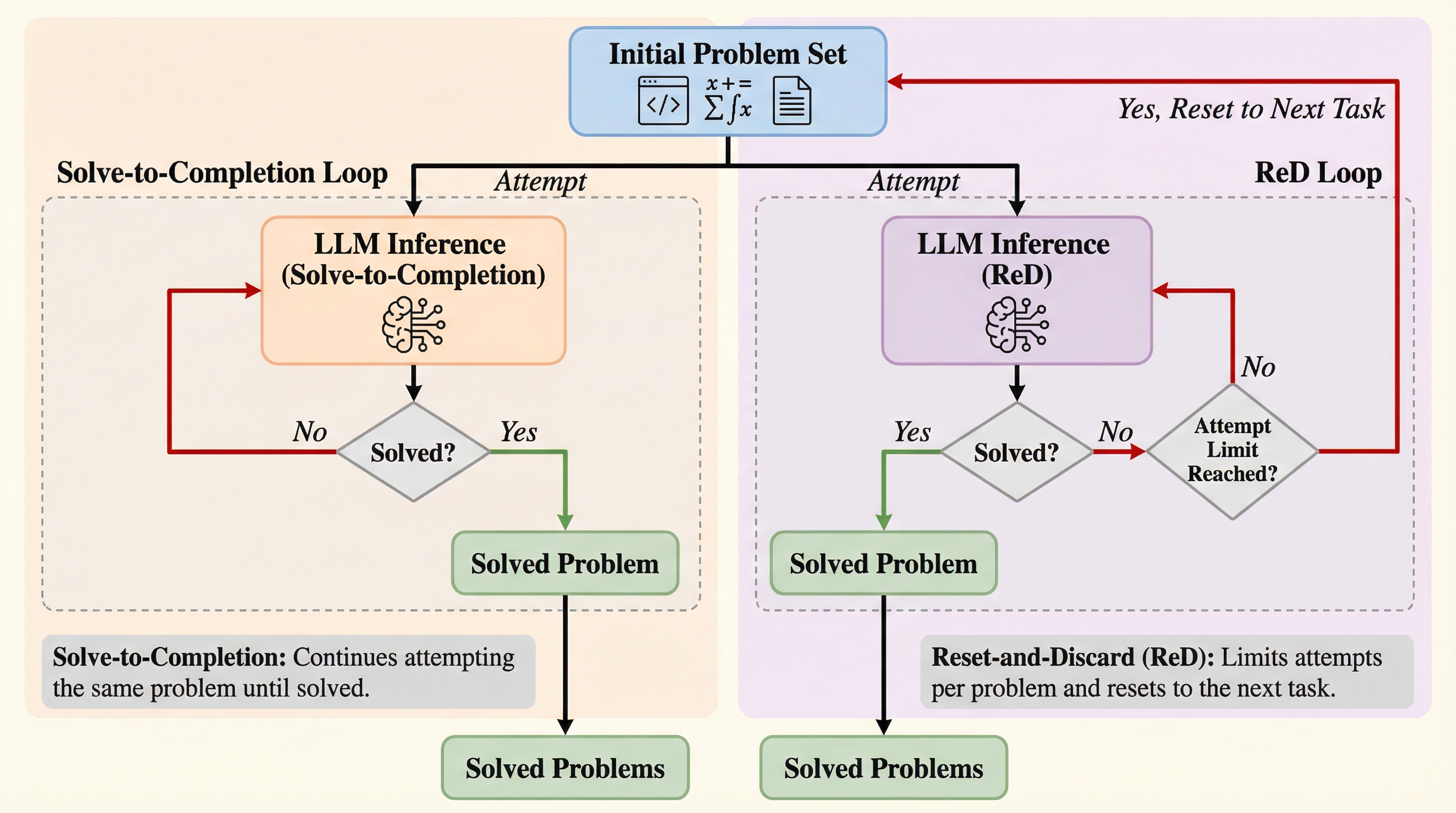
大規模言語モデル(LLM)の推論において、従来は1回でも正解する確率を示すpass@kが重視されてきましたが、実運用では限られた予算内でいくつの異なる問題を解決できるかというcoverage@costがより重要な指標となります。