費用対効果の向上:Reset and Discard (ReD) を用いた固定予算における大規模言語モデルの推論の向上
大規模言語モデル(LLM)の性能評価を、従来の1問あたりの成功率(pass@k)から、限られた総予算内で解決できるユニークな問題数(coverage@cost)へと転換することを提案しています。
TL;DR(結論)
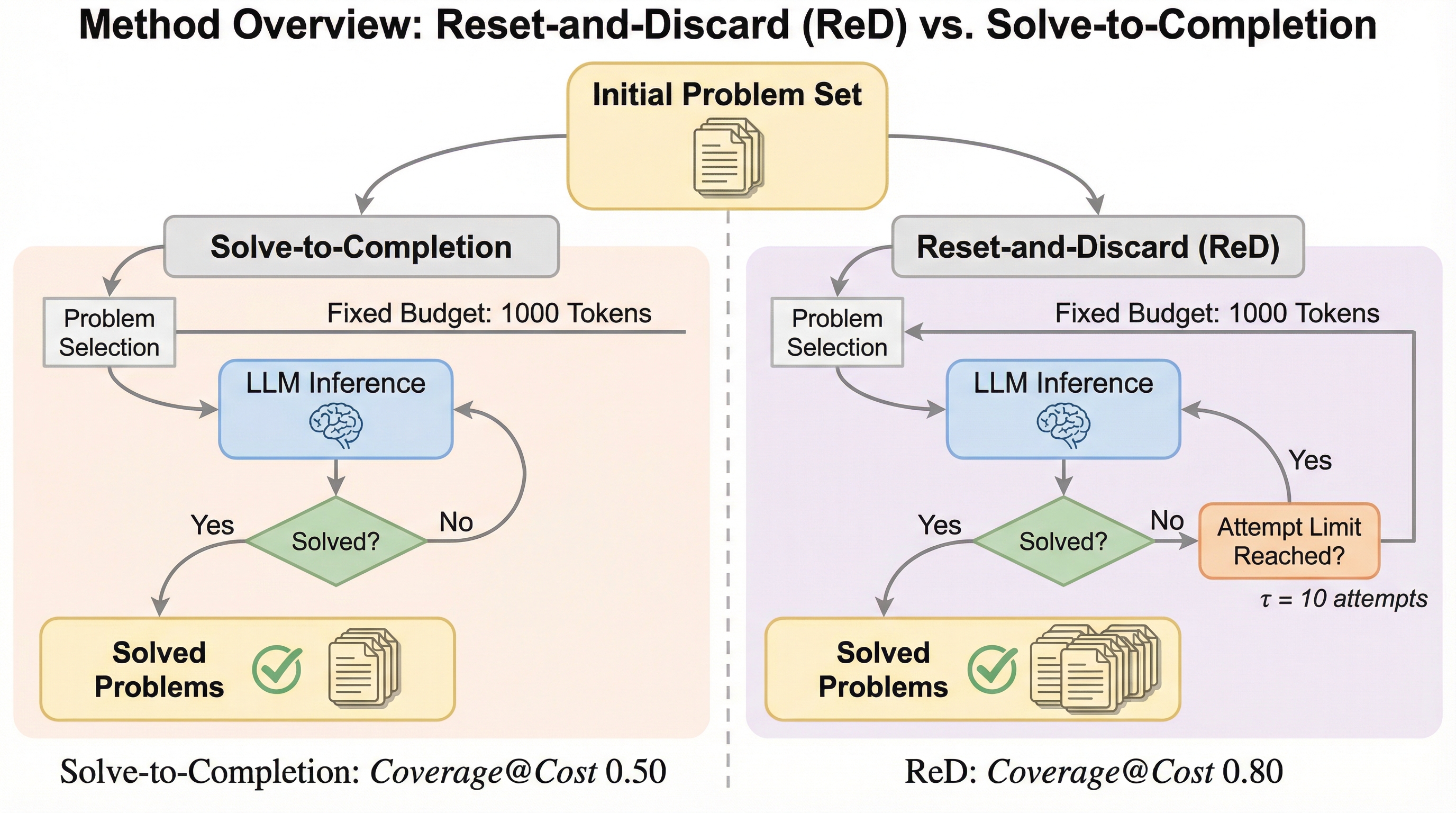
大規模言語モデル(LLM)の性能評価を、従来の1問あたりの成功率(pass@k)から、限られた総予算内で解決できるユニークな問題数(coverage@cost)へと転換することを提案しています。 従来の「解けるまで繰り返す」手法は、困難な問題に計算資源を浪費して全体の効率を下げますが、新手法「Reset and Discard (ReD)」は一定回数で試行を切り替えることで、予算に対する解決数の伸びを劣線形から線形へと劇的に改善します。 理論と実験の両面で、ReDが試行回数、トークン数、費用を大幅に削減することを証明し、さらに推論のスケーリング則を規定する指数を少ない試行で効率的に推定できる評価枠組みとしての有効性も示しました。
なぜこの問題か
大規模言語モデル(LLM)がコーディングや数学、論理的推論といった検証可能なタスクを実行する際、その性能は一般的に「pass@k」という指標で測定されてきました。これは、ある特定の1つの問題に対してk回の回答を生成したとき、少なくとも1回は正解が含まれている確率を指します。しかし、この指標には実用上の大きな限界があります。現実の運用シナリオでは、計算資源や予算、時間は有限であり、単一の問題に執着するよりも、限られた総予算の中でいかに多くの異なる問題を解決できるかという「スループット」が重要視されるからです。 従来の一般的なアプローチは、1つの問題が解決されるまでサンプリングを繰り返し、解決したら次の問題に移るという「完了まで解決(solve-to-completion)」という方針を暗黙的に採用していました。しかし、問題にはそれぞれ難易度の差、すなわち難易度分布が存在します。この方針では、非常に困難な問題に遭遇した際、モデルが膨大な試行回数をその1問だけに費やしてしまい、結果としてワークロード全体の処理能力が著しく低下するという問題が生じます。…
核心:何を提案したのか
本研究では、固定予算内での解決問題数を最大化するための新しいクエリ手法として「Reset and Discard (ReD)」を提案しています。この手法の核心は、非常にシンプルかつ強力な2つのルールに集約されます。第一に、特定の試行回数(τ)に達しても問題が解決しない場合は、その問題を一旦諦めて次の問題へと「リセット(Reset)」することです。第二に、問題が解決された瞬間にその問題をプールから「破棄(Discard)」し、二度と計算資源を割かないようにすることです。これにより、モデルは常に「最も正解する可能性が高い」問題にリソースを集中させることが可能になります。 この手法は、直感的には「幅優先」のアプローチと言えます。失敗を繰り返すことは、その問題がモデルにとって困難であるという情報の蓄積を意味します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related