費用対効果の向上:Reset and Discard (ReD) を用いた固定予算下での大規模言語モデルの推論の改善
大規模言語モデル(LLM)の推論において、従来は1回でも正解する確率を示すpass@kが重視されてきましたが、実運用では限られた予算内でいくつの異なる問題を解決できるかというcoverage@costがより重要な指標となります。
TL;DR(結論)
大規模言語モデル(LLM)の推論において、従来は1回でも正解する確率を示すpass@kが重視されてきましたが、実運用では限られた予算内でいくつの異なる問題を解決できるかというcoverage@costがより重要な指標となります。本研究では、多くのタスクで観察されるべき乗則的な難易度分布が、従来の「正解するまで試行を繰り返す」手法において予算投入に対する成果の伸びを鈍化させ、非効率なリソース消費を招いていることを理論的に明らかにしました。 この課題を解決するために提案されたReset and Discard(ReD)は、各問題への試行を一定回数で打ち切って次の問題へ移り、解決した問題は即座に破棄するという戦略をとることで、あらゆる予算水準において解決数を最大化し、計算資源の配分を最適化する手法です。理論的な証明により、1回の試行ごとに問題を切り替える設定が最も効率的であることが示されており、これにより従来の非線形な成果の伸びを線形へと劇的に改善し、同じ解決数を得るために必要なコストを大幅に削減することが可能になります。 HumanEvalを用いた複数の大規模言語モデルでの実験では、ReDが試行回数、トークン数、および金銭的コストのすべてにおいて顕著な節約を実現し、さらにモデルの推論におけるべき乗則の指数を効率的に推定する手段としても機能することが実証されました。
なぜこの問題か
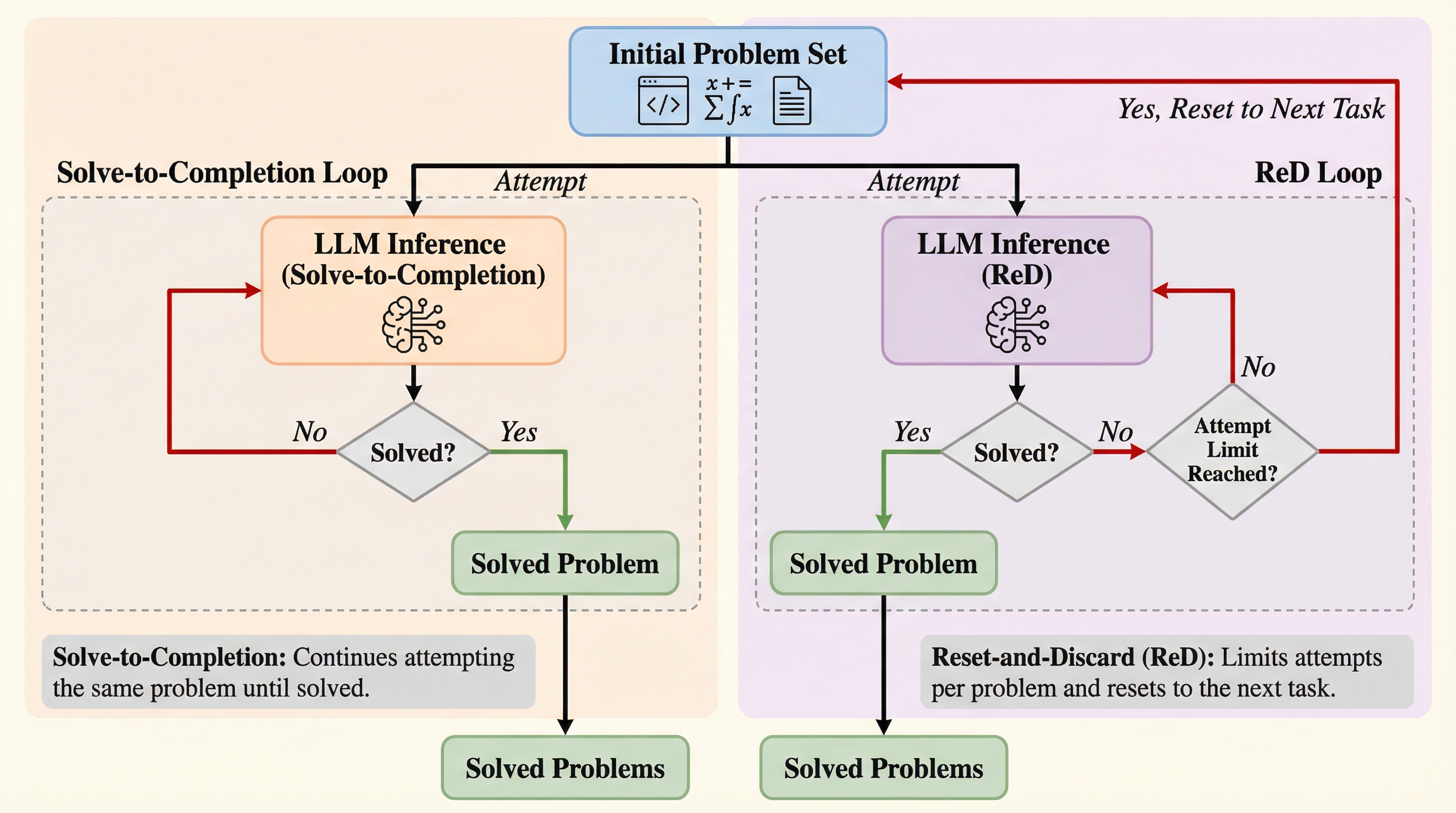
大規模言語モデルがコーディングや数学、論理的証明といった検証可能なタスクを実行する際、複数の回答候補を生成して自動検証を行う手法が一般的になっていますが、これには膨大な計算コストが伴います。これまでの研究では、k回の試行のうち少なくとも1回正解する確率であるpass@kという指標が主に用いられてきましたが、この指標は個別の問題に対する性能を測るものであり、システム全体のスループットを最適化する視点が欠けていました。実際の運用環境では、トークン数や予算、あるいはレイテンシといった固定された総予算の範囲内で、どれだけ多くのユニークな問題を解決できるかというcoverage@costこそが、ビジネスや研究の現場で真に求められる評価軸となります。 しかし、従来の一般的な手法である「問題が解決するまでサンプリングを繰り返し、解決したら次の問題に移る」という戦略(solve-to-completion)には、重大な効率上の欠陥があることが判明しました。…
核心:何を提案したのか
本研究が提案するReset and Discard(ReD)は、固定された予算内でLLMの推論効率を最大化するための、シンプルながらも理論的に裏付けられた新しいクエリ戦略です。この手法の核心は、一つの問題に固執して深掘りするのではなく、多くの問題に対して浅く広く試行を繰り返す「横断的(Breadth-first)」なアプローチを採用することにあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related