シミュレーション合成データでAIエージェントを育てるには何が要るか:不足データ問題からデジタルツイン参照枠組みまで。
現代のサブシンボリックAIは大量かつ高品質な学習データに支えられますが、実世界データは取得コスト、プライバシー、安全性、組織内サイロなどの制約で集めにくく、さらに欠損や重複やノイズが使い勝手を下げるため、合成データ生成の需要が高まります。
TL;DR(結論)
- 現代のサブシンボリックAIは大量かつ高品質な学習データに支えられますが、実世界データは取得コスト、プライバシー、安全性、組織内サイロなどの制約で集めにくく、さらに欠損や重複やノイズが使い勝手を下げるため、合成データ生成の需要が高まります。
- 十分に詳細で現実的なモデルから合成データを作る方法の中でも、シミュレーションはシステムの確率的なふるまいをプログラムとして実行し、時間変化をトレースとして出力することで、制御された条件で多様な訓練データを体系的に生み出せます。
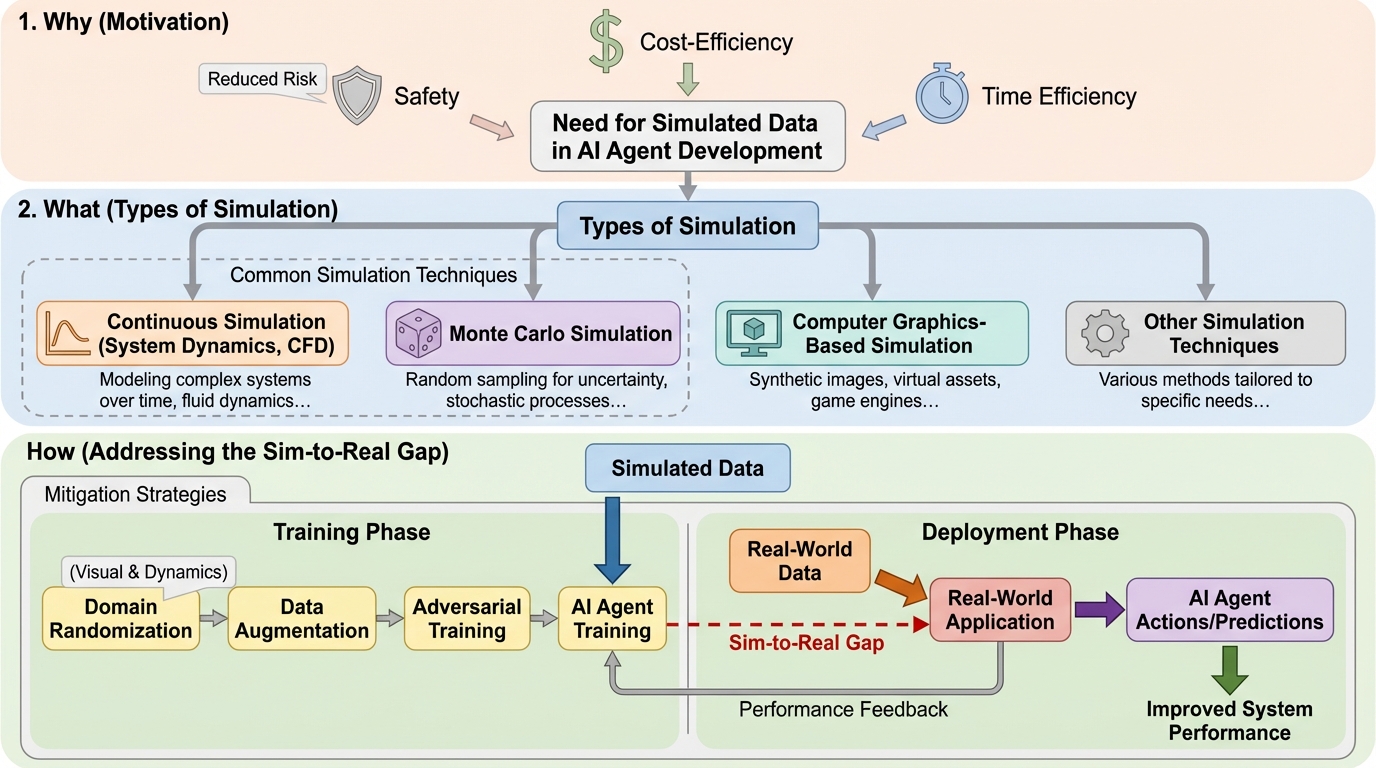
- ただし理想化された前提や現実にあるノイズや希少事象の不足はsim-to-real gapにつながり得るため、ドメインランダム化やドメイン適応などの緩和策を踏まえつつ、デジタルツインに基づくAIシミュレーション解を記述・設計・分析する参照枠組みで整理することが重要になります。
なぜこの問題か
本章の出発点は、現代の人工知能が「大量の高品質データ」と「それを処理する強力な計算手法」によって可能になっている、という認識です。特に現代AIでは、モデルの性能や信頼性が学習データの特性と密接に結び付くとされています。これは、形式手法や論理に支えられた古典的な記号的AIと対照的な点です。一方で、実世界データを十分な量と品質で確保することはしばしば難しいと述べられています。取得コスト、プライバシー制約、安全性の懸念が、現場データへのアクセスを制限する要因になります。工学領域では、プロプライエタリなデータ、データサイロ、機微な運用手順などが取得をさらに複雑にします。教師あり学習に必要なラベル付きデータが不足しがちであることも、よく知られた課題として挙げられています。加えて、データが入手できた場合でも、不完全さ、不整合、重複、ノイズが利用可能性を損なうことがあり、これらを補うために合成データ生成が求められます。
核心:何を提案したのか
本章が中心に据える提案は、AIの訓練目的で合成データを作る手段として「シミュレーション」を体系的に捉え、利点と課題を整理しながら設計・分析できるようにすることです。合成データは、十分に詳細で現実的なモデルから生成され、実データを補強するためにも、場合によっては実データを置き換えるためにも利用できると説明されています。その中でもシミュレーションは、仮想環境で価値あるデータを生成でき、実世界での測定や観測に比べて低コストで、時間や危険性の面でも有利になり得ます。さらに、シミュレーションは多様なデータを「系統立てて」生み出す手段として位置付けられます。ここでの要点は、単にデータを増やすことではなく、目的に合わせて条件を制御し、再現可能な形でデータを作れる点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related