AttentionRetriever:大規模言語モデルのアテンション層に隠された長文検索能力の解明
長文RAGの弱点は、文脈をまたぐ依存関係や背景説明の拾い漏れを、短文向けの検索器がうまく扱えない点にあります。 / AttentionRetrieverは、事前学習済みLLMのattention mapを検索信号として使い、さらにエンティティグラフで検索範囲を広げることで、学習なしで長文検索を強化します。 / 単一文書検索では既存ベースラインを大きく上回り、QAでも入力トークンを大きく減らしながら直接生成に近い性能を示しており、長文RAGでは検索器そのものの前提を見直す必要があると分かります。
TL;DR(結論)
- 長文RAGの弱点は、文脈をまたぐ依存関係や背景説明の拾い漏れを、短文向けの検索器がうまく扱えない点にあります。
- AttentionRetrieverは、事前学習済みLLMのattention mapを検索信号として使い、さらにエンティティグラフで検索範囲を広げることで、学習なしで長文検索を強化します。
- 単一文書検索では既存ベースラインを大きく上回り、QAでも入力トークンを大きく減らしながら直接生成に近い性能を示しており、長文RAGでは検索器そのものの前提を見直す必要があると分かります。
なぜこの問題か
長いレポート、法文書、学術論文、財務資料のような文書を相手にRAGを使うとき、生成モデル以上に苦しくなりやすいのが検索の段階です。短い文書や独立した段落を前提に作られた検索器は、問いに関係する一文だけを拾う場面ではある程度強いのですが、長文では事情が変わります。前段で拾うべき情報は、今見ている段落だけでなく、その前に置かれた背景説明や、後段の推論に必要な前提、複数箇所に散らばった比較対象まで含むことが多いです。長い文書ほど、関係ある部分が一か所にまとまっているとは限りませんし、その関連は単純な語彙一致ではなく、文脈の流れや因果的なつながりに依存します。
核心:何を提案したのか
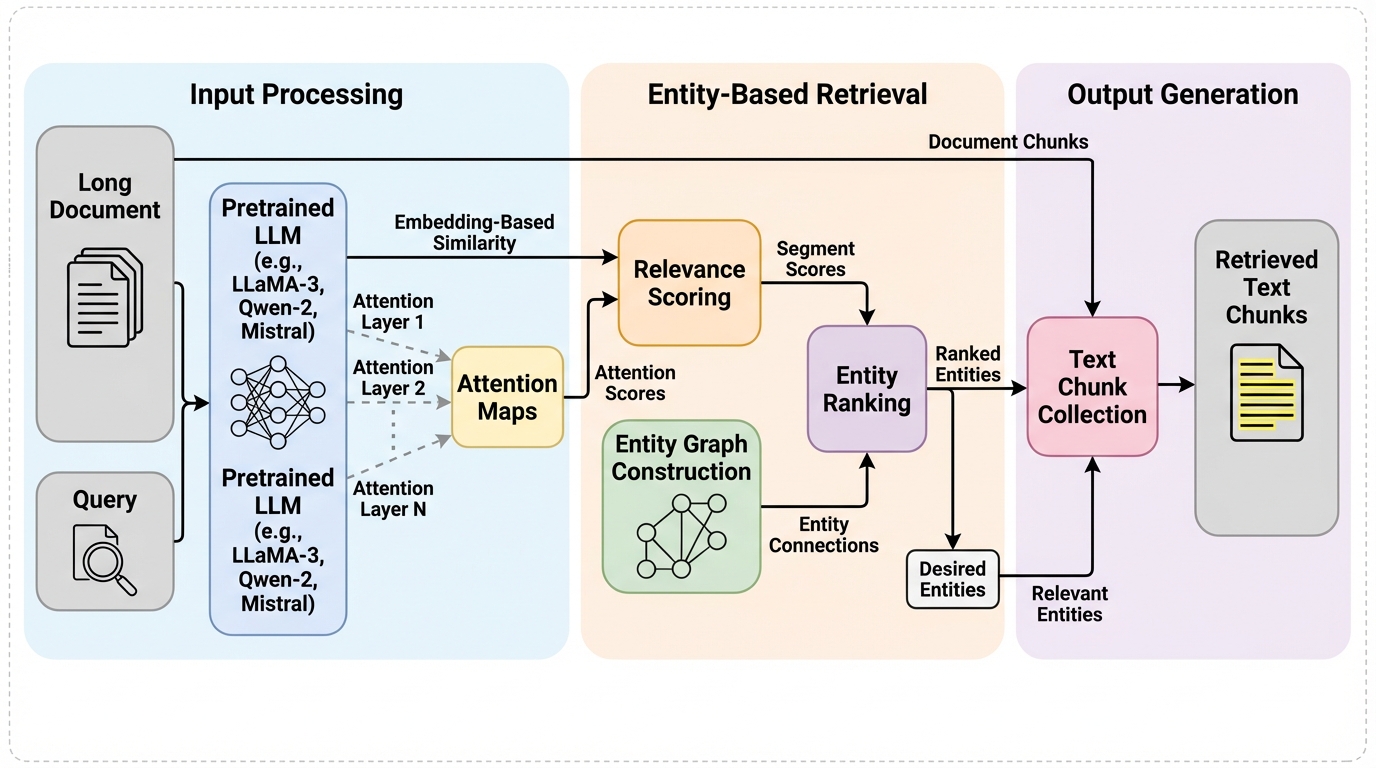
提案の中心はAttentionRetrieverです。狙いは明快で、長文検索に必要な「文脈を踏まえた関連度推定」と「検索範囲の決定」を、既存の事前学習済みLLMから引き出せる形にすることです。キーワード一致や固定ベクトルの類似度だけでは見えにくい依存関係を、attention mapの中から直接読み取り、そこにエンティティベースの探索を重ねます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related