長い文脈ほど焦点がぼけるのか:プライバシーと個人最適化で見えるLLMの「スケーリング・ギャップ」とPAPerBench
長い文脈を与えれば個人最適化が自然に良くなり、同時にプライバシーも堅牢になると期待しがちですが、本研究の評価では文脈長が伸びるほど個人最適化とプライバシーの両方で性能低下が一貫して観測されています。
TL;DR(結論)
- 長い文脈を与えれば個人最適化が自然に良くなり、同時にプライバシーも堅牢になると期待しがちですが、本研究の評価では文脈長が伸びるほど個人最適化とプライバシーの両方で性能低下が一貫して観測されています。
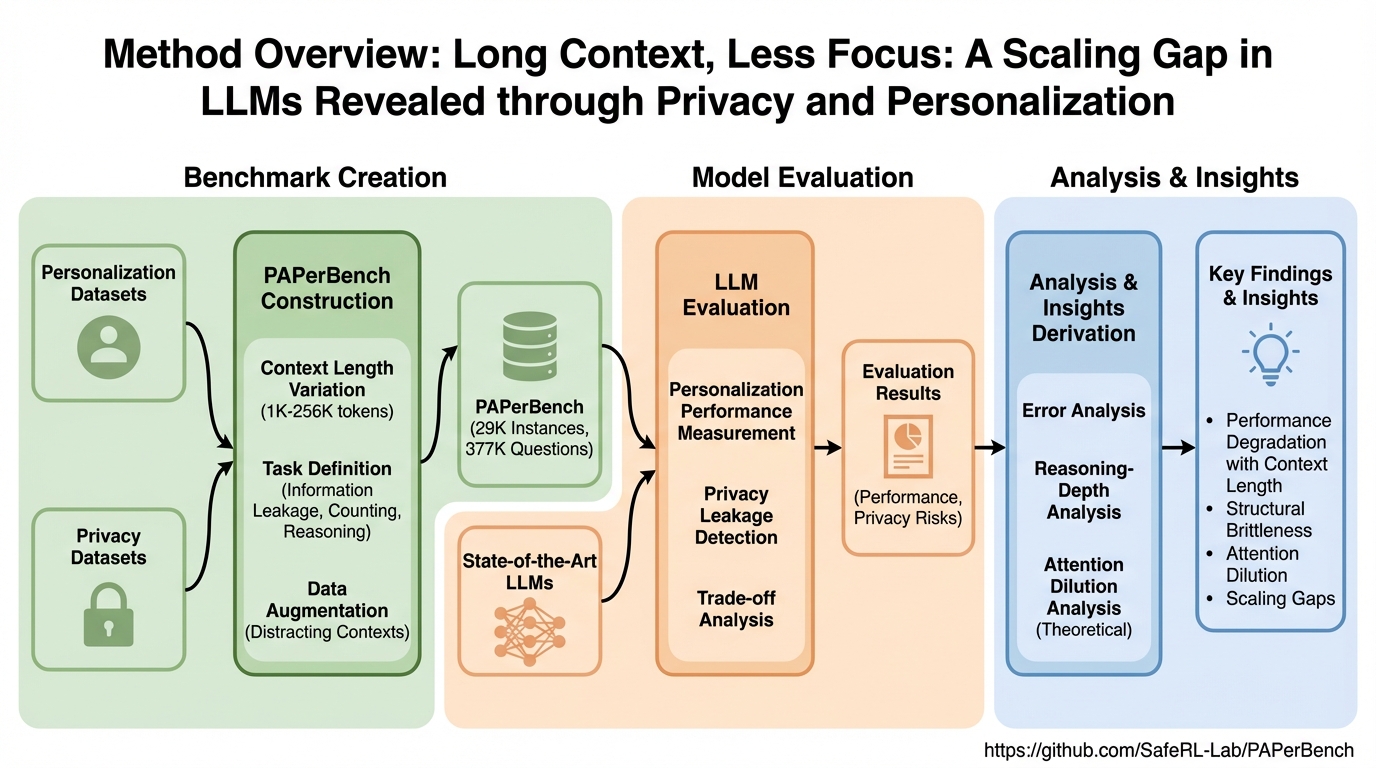
- その確認のために、文脈長を1K〜256Kトークンまで段階的に変えながら、個人最適化の正確さと機微情報に関する推論を同じ枠組みで多肢選択評価できる大規模ベンチマークPAPerBench(約29,000インスタンス、計377K問)が構築されています。
- さらに、固定容量のTransformerでソフトマックス注意を使うと文脈拡大により重要トークンの寄与が薄れる「注意の希釈」が起きうるという理論分析が示され、現状モデルには「Long Context, Less Focus」という一般的なギャップがある可能性が示唆されています。
なぜこの問題か
大規模言語モデルは理解や生成だけでなく、アシスタント、エージェント、個人最適化システムのような実運用で、長い文脈入力を前提に使われる場面が増えています。個人最適化では、利用者の嗜好、習慣、制約、過去のやり取りといった情報が時間とともに増え、その蓄積を手がかりに振る舞いを調整する必要があります。一方で、その文脈には電話番号や住所、識別子などの機微情報が含まれ得るため、個人最適化はプライバシー上の配慮と常に隣り合わせになります。本文抜粋では、プライバシー、規制、遅延といった理由から、機微なユーザー情報をクラウド型のAPIに自由に送れない状況にも触れています。結果として、プロンプト工夫、固定的なユーザープロフィール、あるいは高コストで更新が難しい微調整などに頼る方法が多く、文脈長が伸びたときに個人最適化の質とプライバシーの挙動がどう変化するかを十分に説明できていないとされています。さらに、既存ベンチマークは個人最適化のみ、またはプライバシーのみを別々に測るものが多く、両者の相互作用を文脈長の変化と結びつけて検証しづらい点が問題として挙げられています。…
核心:何を提案したのか
本研究の提案の中心は、長文脈入力におけるプライバシーと個人最適化を同時に測るための統一ベンチマークPAPerBenchの導入です。PAPerBenchは、文脈長を1Kから256Kトークンまで段階的に変化させ、文脈が長くなるほど関連情報が疎になり、無関係な内容に紛れやすい状況を再現しながら、モデルのふるまいを比較できるように設計されています。規模として、約29,000のインスタンスからなり、評価質問は総計377K問とされています。各インスタンスに対して、個人最適化を問う設問と、機微情報に関するプライバシー設問を複数含めることで、片方だけを測るのではなく、同一の背景文脈のもとで両面を点検できる点が狙いです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related