Avey-B:注意機構を使わないAveyを双方向エンコーダとして再定式化し、長文脈へ効率よくスケールさせる設計です。
Avey-Bは、計算資源とメモリの制約が厳しい状況でも使われやすい双方向エンコーダを、自己注意の二乗コストに依存せず長い文脈へ拡張しやすくするための注意機構なしアーキテクチャです。 / 入力列を分割して関連分割だけをランキングで取得しつつ、層ごとに「静的な線形変換」と「コサイン類似度にもとづく動的な文脈化」を分離し、類似度の安定化のための正規化と、取得文脈を一定トークン予算へ圧縮する仕組みを組み込みます。 / 標準的なトークン分類と情報検索ベンチマークでTransformer系の双方向エンコーダ4種と比較して一貫して良好に振る舞い、128〜96Kトークンでは系列が長いほど遅延面の優位が広がり、96KでModernBERT比3.38倍、NeoBERT比11.63倍の高速化が報告されています。
TL;DR(結論)
- Avey-Bは、計算資源とメモリの制約が厳しい状況でも使われやすい双方向エンコーダを、自己注意の二乗コストに依存せず長い文脈へ拡張しやすくするための注意機構なしアーキテクチャです。
- 入力列を分割して関連分割だけをランキングで取得しつつ、層ごとに「静的な線形変換」と「コサイン類似度にもとづく動的な文脈化」を分離し、類似度の安定化のための正規化と、取得文脈を一定トークン予算へ圧縮する仕組みを組み込みます。
- 標準的なトークン分類と情報検索ベンチマークでTransformer系の双方向エンコーダ4種と比較して一貫して良好に振る舞い、128〜96Kトークンでは系列が長いほど遅延面の優位が広がり、96KでModernBERT比3.38倍、NeoBERT比11.63倍の高速化が報告されています。
なぜこの問題か
事前学習済みの双方向エンコーダは、産業用途の自然言語処理で長く基盤になってきたと説明されています。理由の一つは、双方向エンコーダが各トークンを左右両側の文脈に条件づけられるため、曖昧性の解消に有利な表現を作りやすい点です。本文でも、分類や検索、抽出的な質問応答のような識別系タスクで有利になりやすいことが例として挙げられています。もう一つの理由は、BERT系で一般化した自己注意が、双方向の文脈化を実現しながら系列レベルの並列性を保ちやすい点です。 一方で、完全な自己注意は時間とメモリのコストが系列長に対して二乗で増えるため、文脈窓を現実的なコストで延ばす際の中心的なボトルネックになると述べられています。これを緩和するために線形注意やRNNに着想を得た設計などが研究されてきたものの、双方向・エンコーダ専用という枠組みに十分適応されたものは多くない、という問題意識が示されています。また、FlashAttention、SwiGLU、RoPEなどを取り入れてBERT系が「現代化」されてきた流れがある一方で、二乗コストそのものは残り続ける点も重要です。…
核心:何を提案したのか
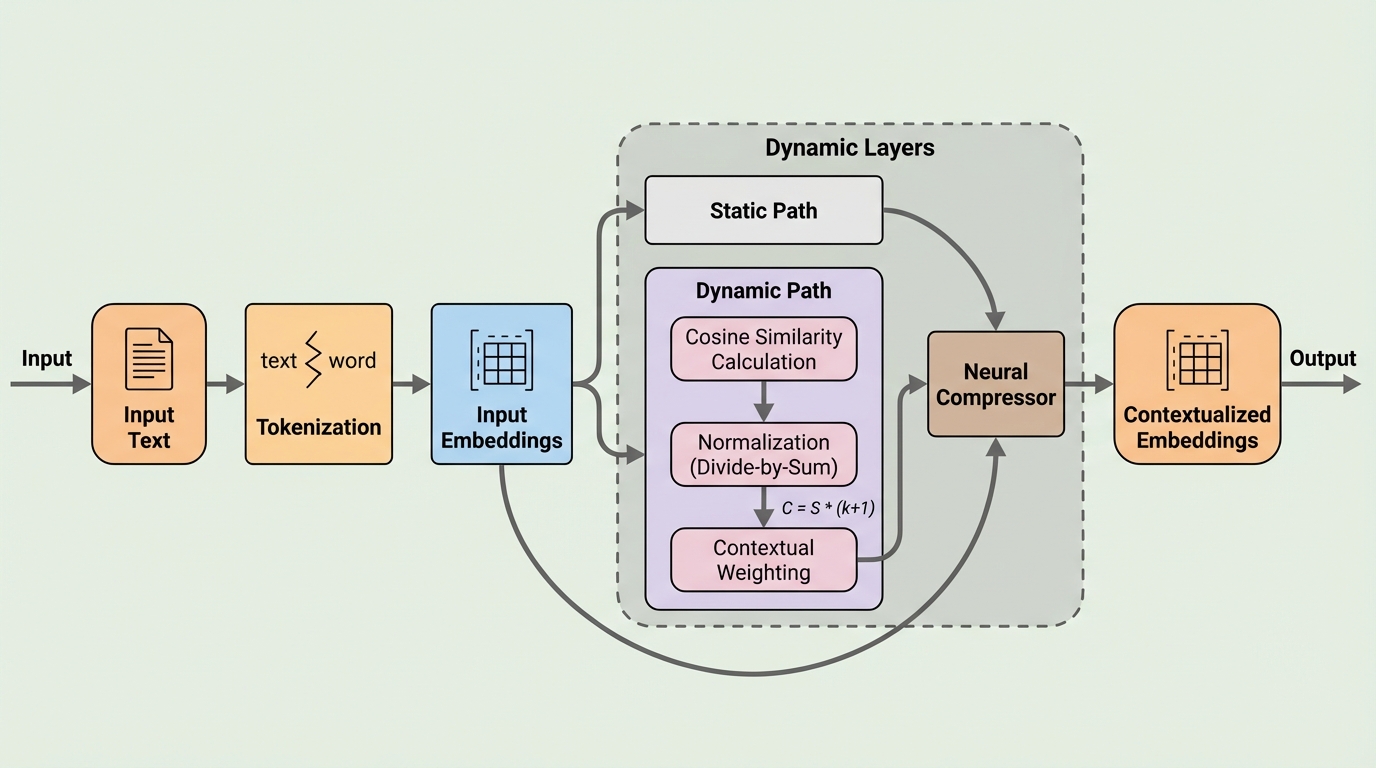
本論文の提案は、Aveyをエンコーダ専用(encoder-only)の枠組みに再定式化した双方向モデルAvey-Bです。Aveyは元々、自己回帰(因果)目的を想定した注意機構なしの設計ですが、コサイン類似度にもとづく選択性や、埋め込み間の学習済み線形変換を含むため、双方向化に自然に適合しうると説明されています。Avey-Bはこの性質を利用し、因果マスクに依存しない形でトークン表現を左右両側の文脈に条件づけるように作り替えます。 さらにAvey-Bでは、アーキテクチャ上の工夫として少なくとも三つの改良を加えています。第一に、静的パラメータ(学習済みの線形変換)と動的パラメータ(入力に依存して計算される類似度)を同じ層で乗算的に結合するのではなく、層の深さ方向に分離して交互に用いる「分離された静的・動的パラメータ化」を導入します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related