CM2:チェックリスト報酬でマルチターン・マルチステップのツール利用エージェントを強化学習する
現実のエージェント学習では「最終回答が正しいか」のように検証可能な報酬を用意しにくく、しかも対話の継続や提案など開放的な振る舞いを最適化したいのに、強化学習を回すための信号設計が難しい問題があります。
TL;DR(結論)
- 現実のエージェント学習では「最終回答が正しいか」のように検証可能な報酬を用意しにくく、しかも対話の継続や提案など開放的な振る舞いを最適化したいのに、強化学習を回すための信号設計が難しい問題があります。
- CM2は各ターンの意図を、証拠に基づく二値のチェック項目と依存関係・重みなどのメタデータに分解し、評価基準は細かくしつつ報酬を与える位置は慎重に選ぶ方針で、長いツール利用対話を強化学習で最適化します。
- 大量ツールの実装負担を避けるために大規模な言語モデルによるツール模擬環境で学習し、8BのBaseモデルを8k例のRLデータセットで学習した実験では、教師あり微調整より複数ベンチマークでスコアが上がることが示されています。
なぜこの問題か
マルチターンのユーザー対話を踏まえて推論し、検索やデータベース、各種API、コンパイラのような外部ツールを呼び出しながら問題解決するエージェントは、単発の質問応答とは異なる難しさを持ちます。まず、現実的な目的は最終出力の正誤だけで表しにくく、確認質問を挟む、役に立つ提案を行う、丁寧な口調を保つといった開放的な行動が評価対象になりやすいです。ところが、強化学習で一般的に使いやすいのは、最終回答のルールベース判定やツール実行トレースの完全一致のような「検証可能な報酬」ですが、こうした信号は開放的な目標には適用しにくいです。次に、マルチターン対話の状態保持と、1ターン内のマルチステップなツール呼び出し連鎖を同時に最適化する強化学習は、十分に掘り下げられていないと位置づけられています。合成データを使った教師あり微調整が多く、強化学習もマルチステップ推論に寄るなど、対話ダイナミクスまで含めて扱う設計が難所になります。さらに、強化学習を大規模に回すには、実行可能なツール環境を作って保守する工学的コストが大きく、ツールの規模や多様性を増やしにくいです。…
核心:何を提案したのか
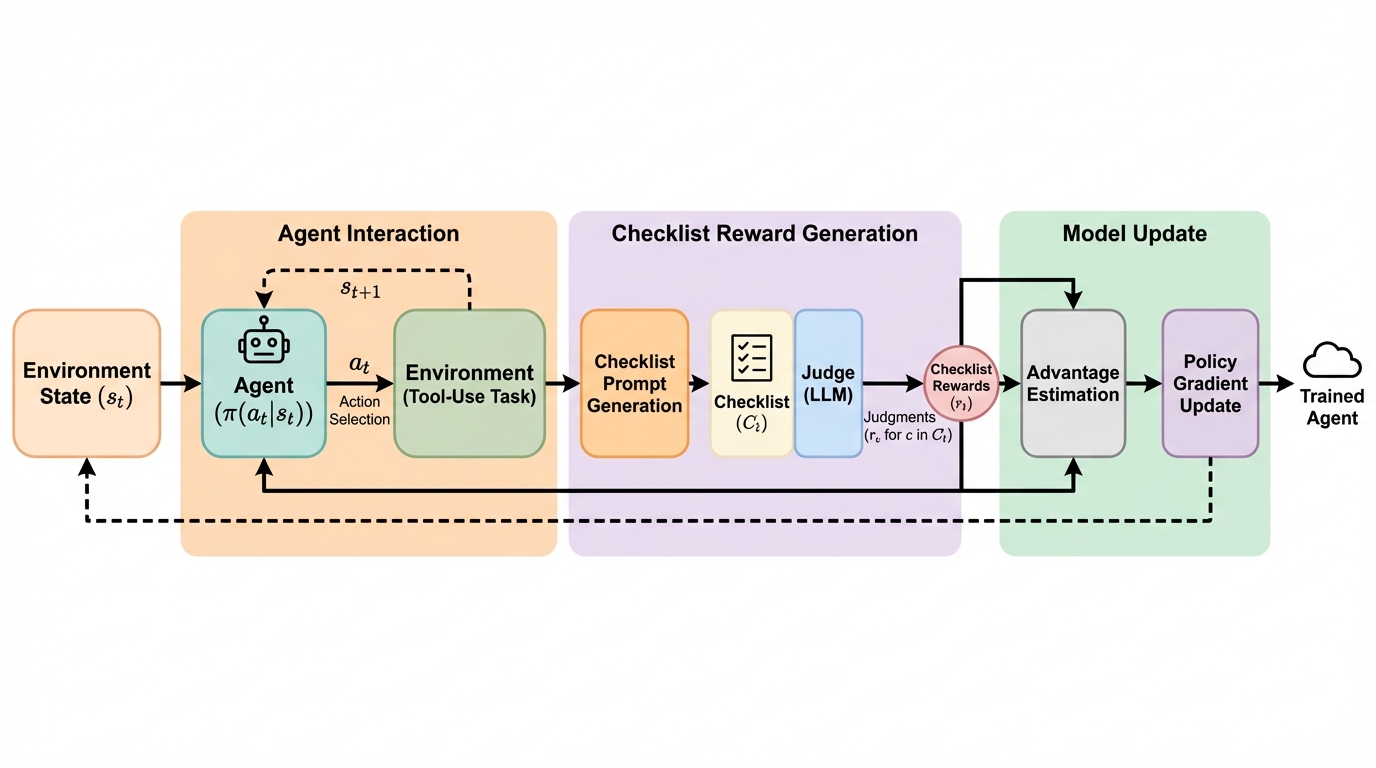
提案はCM2という枠組みで、検証可能なアウトカム報酬に頼らずに、チェックリスト報酬へ置き換えて強化学習する点が中核です。CM2では各ターンで意図される振る舞いを、複数の細粒度な二値基準に分解し、各基準がどの箇所を根拠に判断されるかを明示します。これにより、開放的な良し悪しを連続スコアで採点する問題として扱うのではなく、「条件を満たしたかどうか」の分類に近い形へ寄せ、判断の揺れを抑える狙いがあります。チェックリスト項目には、根拠となる証拠箇所へのポインタ、どの種類のステップに注目するか(推論、ツール呼び出し、ツール応答、最終返答など)の焦点、合格条件と不合格例、次ターンに進むために必須かどうかを示す厳格性、依存関係、重み付けといったメタデータが付与されます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related