意味的チャンク分割と自然言語のエントロピー:階層構造から「約1ビット/文字」を説明する試み。
印刷された英語のエントロピー率が「約1ビット/文字」と推定されるほど小さいことは、ランダムなテキストに期待される「約5ビット/文字」と比べて大きな冗長性を含むことを意味し、その理由を意味の階層構造から説明しようとしています。 / 大規模言語モデルを使って文書を意味的に一貫した塊へ再帰的に分割し、トークンを葉にもつ「意味木」を作ったうえで、最大分岐数Kだけで定まるランダムなK分木アンサンブルにより、その木が現れる確率を計算できる形にします。 / 意味木の確率から得た理論的なエントロピー率の推定は、次トークン確率から得るクロスエントロピー推定と多様なコーパスで近くなり、さらにエントロピー率は固定ではなくコーパスの意味的複雑さに応じて系統的に増えるという見通しを示します。
TL;DR(結論)
- 印刷された英語のエントロピー率が「約1ビット/文字」と推定されるほど小さいことは、ランダムなテキストに期待される「約5ビット/文字」と比べて大きな冗長性を含むことを意味し、その理由を意味の階層構造から説明しようとしています。
- 大規模言語モデルを使って文書を意味的に一貫した塊へ再帰的に分割し、トークンを葉にもつ「意味木」を作ったうえで、最大分岐数Kだけで定まるランダムなK分木アンサンブルにより、その木が現れる確率を計算できる形にします。
- 意味木の確率から得た理論的なエントロピー率の推定は、次トークン確率から得るクロスエントロピー推定と多様なコーパスで近くなり、さらにエントロピー率は固定ではなくコーパスの意味的複雑さに応じて系統的に増えるという見通しを示します。
なぜこの問題か
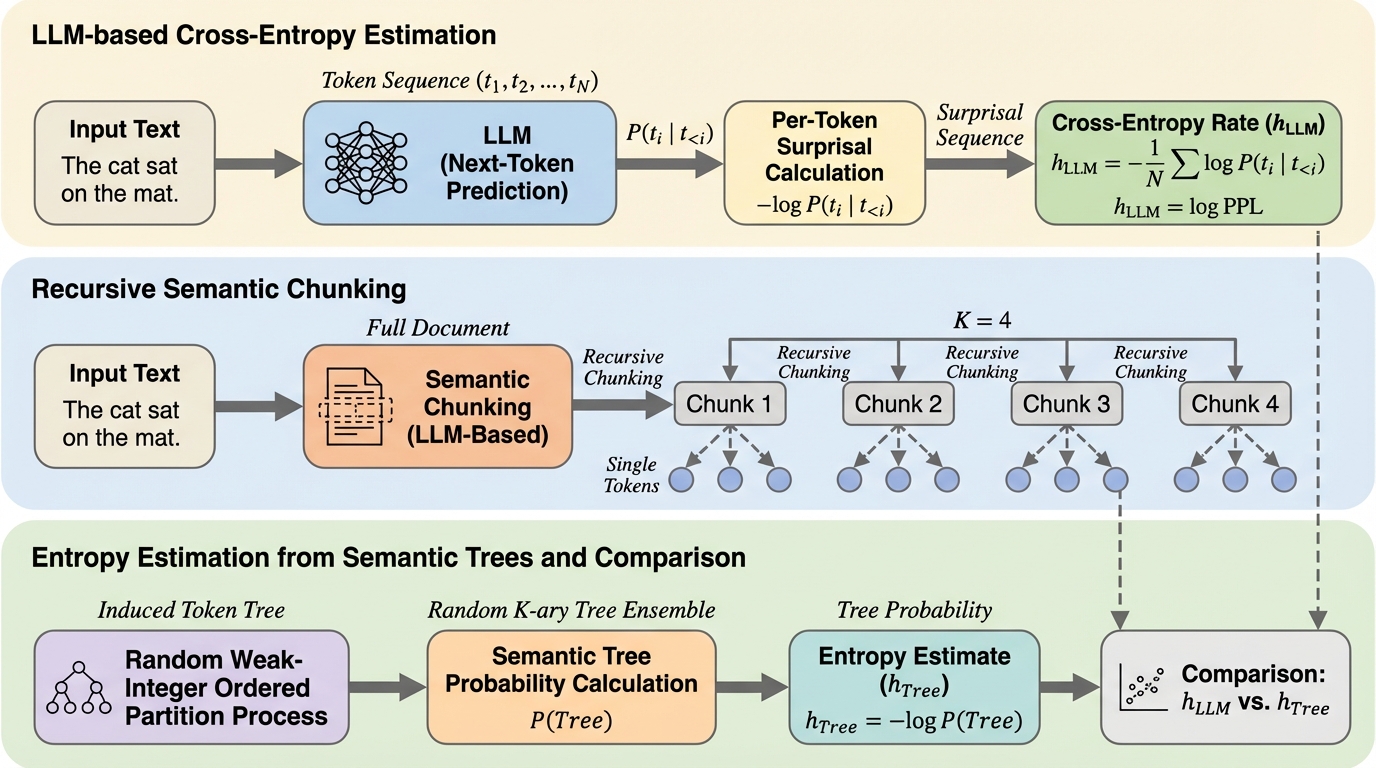
印刷された英語のエントロピー率が約1ビット/文字という推定は、情報理論の古典的な基準としてよく知られています。これは、文字が完全にランダムに並ぶ場合に期待される約5ビット/文字と比べると、英語には大きな冗長性があることを示します。近年は大規模言語モデルが次トークン予測から同種の尺度を推定できるようになり、同程度の値に近づいていると位置づけられていますが、「なぜその程度まで不確実性が下がるのか」を第一原理から説明する枠組みは十分ではない、という問題意識が置かれています。 著者らは、自然文の理解が一段階の当て推量ではなく、抽象度の異なる複数段階の推論として進む点に焦点を当てます。読者はまず全体の話題や意図を推定し、次に段落や節の役割を推定し、その後に文法的な制約へと期待を絞り込む、という入れ子の推論が想定されています。このような階層は、単語列そのものより前に「あり得る続き方」を狭めるため、各段で統計的な冗長性を生みます。たとえば文法は語の並びを強く制限し、文同士の関係は次の展開を拘束し、物語の終わりは始まりとの対応を要請します。 そこで、テキストの意味を段階的に要約する「要点」の集まりを木として表す考え方が導入されます。…
核心:何を提案したのか
提案の中心は、自然言語がもつ「多スケールの意味構造」を、自己相似的な分割として定式化し、そこからエントロピー率を導く統計モデルを与えることです。具体的には、文書を意味的に一貫した連続区間(チャンク)へ分割し、その各チャンクをさらに同様に分割する操作を、単一トークンの水準まで再帰的に繰り返します。その結果、文書全体を根、意味的スパンを内部節点、トークンを葉にもつ階層的な木が得られ、これを意味木として扱います。 この意味木は、同じテキストでも理解の仕方により異なり得るという見取り図も示されており、個別の木そのものよりも、ある長さのテキスト集合に対応する「木の集合」を統計的に近似することが重要になります。そこで著者らは、木の集合をランダムなK分木のアンサンブルで近似します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related