Webエージェントのためのエージェンティックなテスト時スケーリング
Webのマルチステップ作業では、各ステップで同じだけ候補生成を増やす一様な推論時スケーリングは、手順が長いほど効果が早く頭打ちになり、簡単な操作にも計算が偏って無駄が生じやすいです。 / 各ステップで複数の候補行動をサンプルして投票分布を作り、その分布から不確実性(エントロピーや上位二択の差)を計算して、判断が割れているときだけ追加の選別器(Arbiter)を呼び出すCATTSを提案しています。 / CATTSはWebArena-LiteとGoBrowseでReActより最大9.1%の改善を示し、さらに一様スケーリングより最大2.3倍少ないトークンで動かせる可能性を示しつつ、どのステップで計算を増やしたかを規則として説明しやすくします。
TL;DR(結論)
- Webのマルチステップ作業では、各ステップで同じだけ候補生成を増やす一様な推論時スケーリングは、手順が長いほど効果が早く頭打ちになり、簡単な操作にも計算が偏って無駄が生じやすいです。
- 各ステップで複数の候補行動をサンプルして投票分布を作り、その分布から不確実性(エントロピーや上位二択の差)を計算して、判断が割れているときだけ追加の選別器(Arbiter)を呼び出すCATTSを提案しています。
- CATTSはWebArena-LiteとGoBrowseでReActより最大9.1%の改善を示し、さらに一様スケーリングより最大2.3倍少ないトークンで動かせる可能性を示しつつ、どのステップで計算を増やしたかを規則として説明しやすくします。
なぜこの問題か
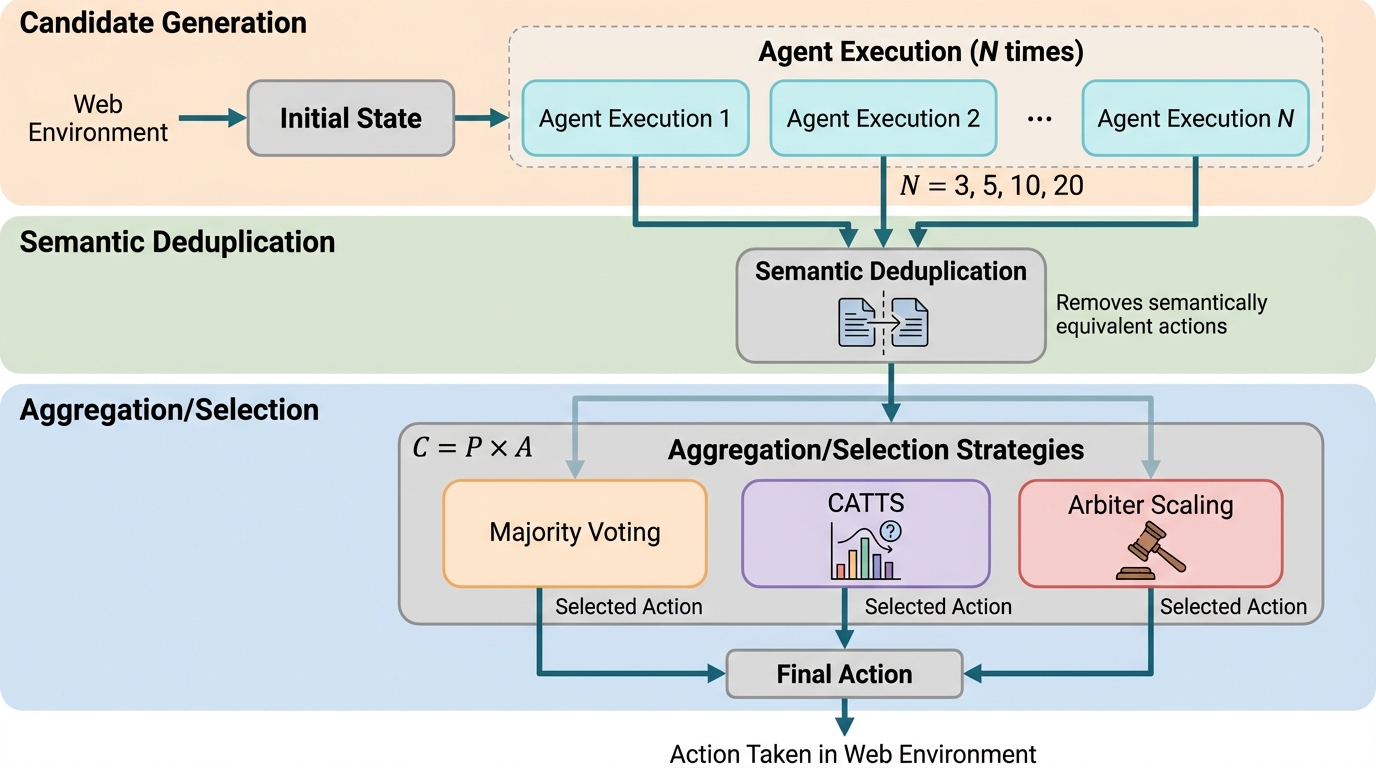
大規模言語モデルは、文章を返すだけでなく、ツールを呼び出して行動し、ブラウザのページを移動したりフォームに入力したりしながら、複数ステップで目的を達成する使い方が増えています。こうした環境では、エージェントは毎ステップで「いま見えているページ状態」と「これまでの履歴」を踏まえて次の行動を選び続ける必要があります。そのため単発の質問応答よりも信頼性が難しく、各ステップの小さな誤りが積み重なって、途中で回復が難しい状態に入ることがあると指摘されています。 そこで推論時スケーリングとして、テスト時に追加計算を使って候補を複数生成し、うまく集約して正しい行動を選ぶ発想が自然に出てきます。ただし、単発タスクで広く使われる「複数サンプルを生成して多数決する」やり方を、マルチステップのエージェントにそのまま当てはめると、各ステップで同じだけ計算を増やす一様な設計になりがちです。著者らは、この一様スケーリングには少なくとも二つの問題があると述べています。第一に、状態と目的から見て明らかな「簡単なステップ」が多い場合でも同じコストを払い続けてしまい、計算が浪費されます。…
核心:何を提案したのか
提案の中心は、Confidence-Aware Test-Time Scaling(CATTS)という、マルチステップのエージェントに対して推論時計算を動的に配分するための簡潔な規則です。発想は「すべてのステップを同じだけ重くする」のではなく、「本当に判断が割れているステップだけ重くする」というものです。著者らは、判断の割れ具合を測る信号として、モデル内部の確率やトークンごとの対数確率に依存せず、エージェントが自分でサンプルした候補行動の“合意度”を使います。 具体的には、各ステップでベースモデルから複数の候補行動をサンプルし、それらを意味的に重複除去したクラスタにまとめ、各クラスタの票数から投票分布を作ります。この投票分布が一つの行動に集中していれば「自信が高い」状態に近く、複数の行動に散っていれば「不確実」な状態に近いとみなせます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related