UniT:統合型マルチモーダルモデルに複数ラウンドの推論・検証・編集を組み込み、推論時計算を画像ラウンドで拡張する枠組み
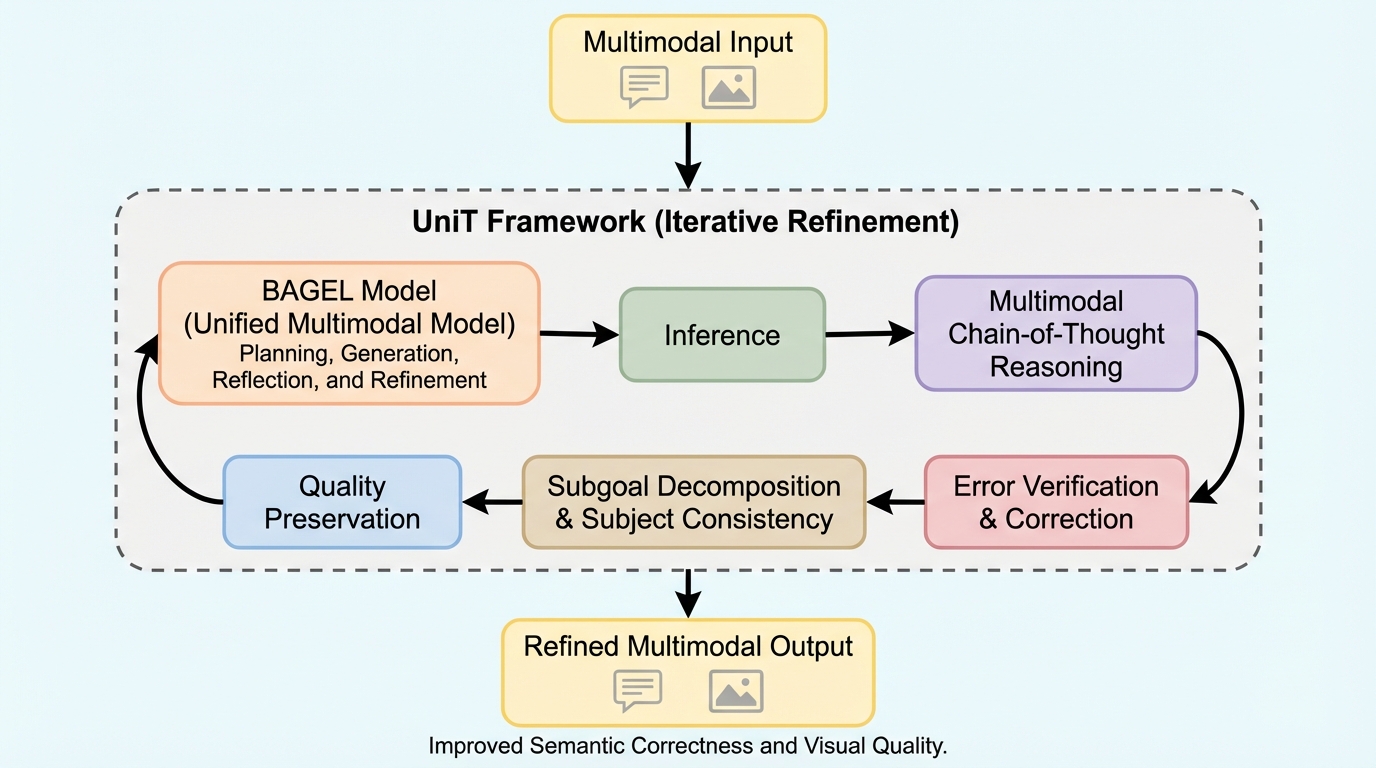
UniTは、理解と生成を同じモデルでこなしつつ、1回で答えを出すのではなく、画像を作り、確かめ、直し、また確かめるという反復をテスト時に回す枠組みです。 / 重要なのは、候補を並列にたくさん出して選ぶよりも、逐次的に考えて直していく方が、同じ計算量あたりで強い点です。画像生成、編集、視覚推論の複数ベンチで一貫して優位が出ています。 / 成功の鍵は、検証、サブゴール分解、内容記憶という三つの認知的ふるまいを学習データに埋め込んだことにあります。逆に言うと、単に推論回数を増やすだけでは足りず、何を確認し、何を覚え、どう分けて直すかまで設計しないと伸びません。
論文図解
TL;DR(結論)
- UniTは、理解と生成を同じモデルでこなしつつ、1回で答えを出すのではなく、画像を作り、確かめ、直し、また確かめるという反復をテスト時に回す枠組みです。
- 重要なのは、候補を並列にたくさん出して選ぶよりも、逐次的に考えて直していく方が、同じ計算量あたりで強い点です。画像生成、編集、視覚推論の複数ベンチで一貫して優位が出ています。
- 成功の鍵は、検証、サブゴール分解、内容記憶という三つの認知的ふるまいを学習データに埋め込んだことにあります。逆に言うと、単に推論回数を増やすだけでは足りず、何を確認し、何を覚え、どう分けて直すかまで設計しないと伸びません。
なぜこの問題か
近年の統合マルチモーダルモデルは、画像理解と画像生成を一つのアーキテクチャで扱えるようになりました。ところが、実際の使い方を見ると、多くはまだ単発です。指示を受けたら一度で画像や回答を出し、その後に自分で検証したり、途中結果を踏まえて改善したりする機構は弱いままです。
核心:何を提案したのか
UniTの核心は、統合マルチモーダルモデルに対して、逐次的な chain-of-thought test-time scaling を成立させる統一フレームワークを与えた点にあります。単に推論時間を長くするのではなく、画像生成・編集・理解をまたぐ一連の反復を、同じモデルの中で扱えるようにします。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related