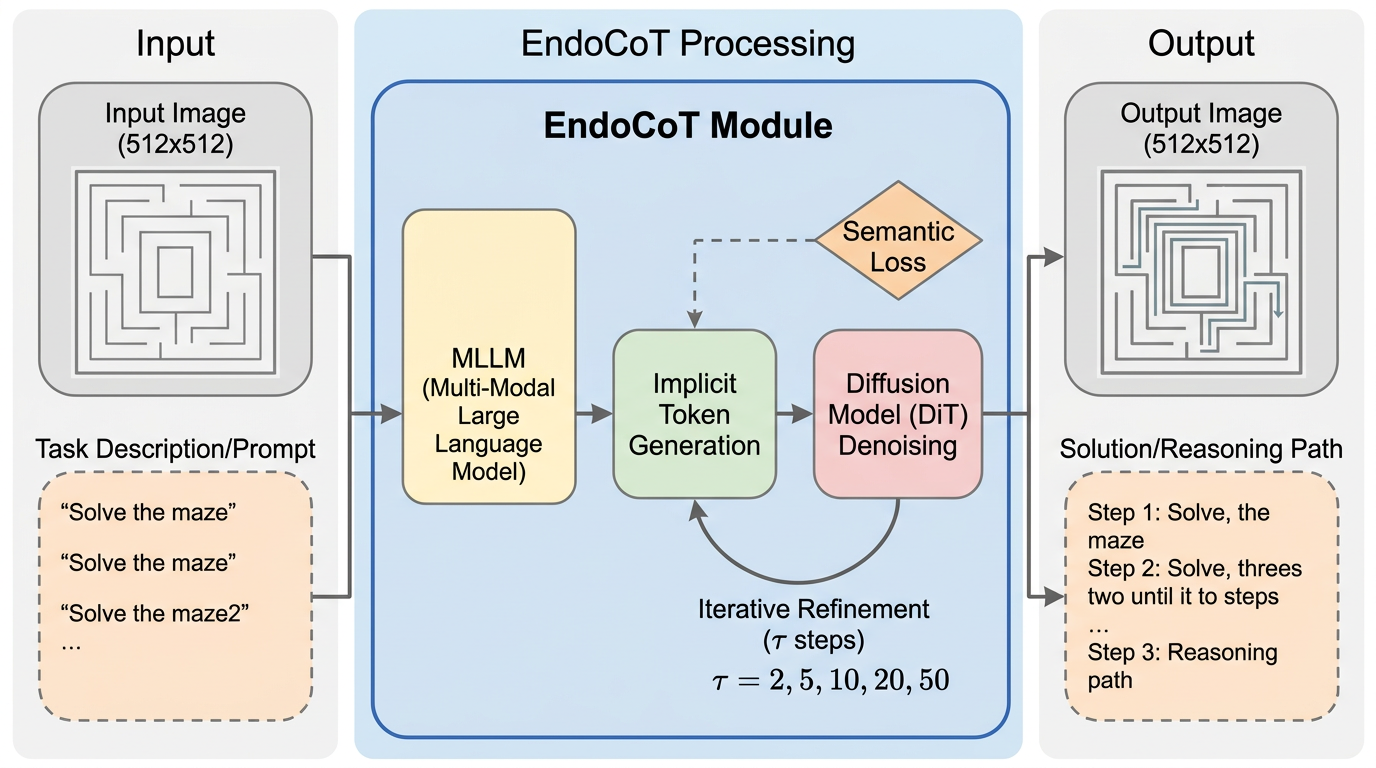
SciMDR:科学論文の長文・図表推論を、忠実さと現実性を両立した合成データで鍛える
科学論文向けのマルチモーダル推論データを作るときは、量を増やすと幻覚が増えやすく、忠実さを優先すると現実の長大文書らしさが失われるという板挟みがある。 SciMDR は、この板挟みを「小さな根拠断片で正確に生成する段階」と「それを論文全体へ再配置して実運用に近づける段階」に分けることで、30万件規模と高忠実性と文書全体の複雑さを同時に狙う。 Qwen2.5-VL-7B を SciMDR で学習すると、独自ベンチ SCIMDR-Eval で 19.8 から 49.1 へ伸び、GPT-5.2 の 49.9 に迫る水準まで到達した。