SONIC:キーバリューキャッシングにおける情報圧縮のためのセグメント化された最適化ネクサス
大規模言語モデルのマルチターン対話において、履歴の増加に伴い線形に肥大化するKVキャッシュのメモリ問題を解決するため、履歴セグメントを「Nexus」と呼ばれる少数の学習可能なトークンに集約して圧縮する新しいフレームワーク「SONIC」が提案されました。
TL;DR(結論)
大規模言語モデルのマルチターン対話において、履歴の増加に伴い線形に肥大化するKVキャッシュのメモリ問題を解決するため、履歴セグメントを「Nexus」と呼ばれる少数の学習可能なトークンに集約して圧縮する新しいフレームワーク「SONIC」が提案されました。 この手法は、階層的な可視性マスクによって履歴の生テキストを削除しつつ重要な文脈を保持し、さらに動的予算トレーニングを導入することで、推論時に再学習を行うことなく利用可能なメモリ量に合わせて圧縮率を柔軟に調整できる仕組みを実現しています。 MTBench101を含む4つのベンチマークで検証した結果、既存の代表的な圧縮手法であるH2OやStreamingLLMを一貫して上回り、特にMTBench101では平均スコアを35.55%向上させ、推論速度もフルコンテキスト時より50.1%向上させる成果を上げました。
なぜこの問題か
大規模言語モデル(LLM)の主要な用途としてマルチターン対話が定着していますが、標準的なトランスフォーマーの自己注意機構には、Key-Value(KV)キャッシュが文脈の長さに応じて線形に増加し続けるという性質があります。この線形な増加は、推論時のメモリ消費量とレイテンシを増大させ、効率的なデプロイメントを妨げる重大なボトルネックとなっています。FlashAttentionのような既存の最適化手法はメモリへのアクセスパターンを改善しますが、KVキャッシュ自体の増大という根本的な問題は解決できません。この課題に対し、線形注意機構や状態空間モデル(SSM)といった新しいアーキテクチャも提案されていますが、現在の対話モデルの主流は依然としてトランスフォーマーであり、既存のエコシステムとの互換性や再学習にかかる膨大なコストが普及の障壁となっています。 一方で、推論時にKVキャッシュを圧縮する既存の戦略として、注意スコアに基づいてトークンを破棄するH2Oや、初期トークンを維持するStreamingLLMなどが存在します。…
核心:何を提案したのか
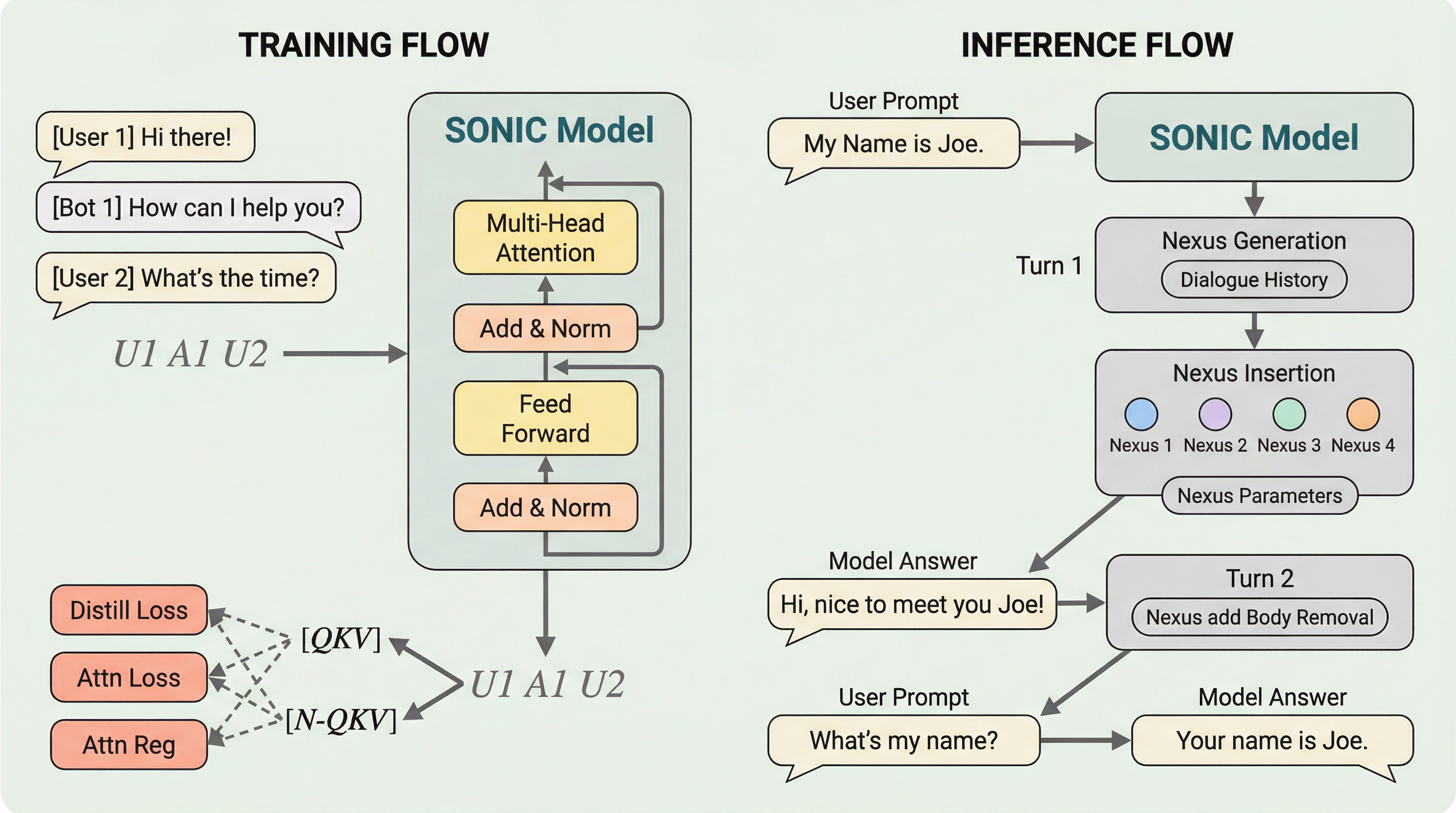
本論文では、マルチターン対話におけるKVキャッシュのメモリ制約を解消するための学習型フレームワーク「SONIC(Segmented Optimized Nexus for Information Compression)」を提案しています。このフレームワークの核となるのは「Nexus」と呼ばれるメカニズムです。これは、履歴の各セグメントに挿入される特殊な学習可能トークンであり、過去の情報をコンパクトかつ意味的に豊かな表現として集約する役割を担います。SONICは、履歴情報を単純に間引くのではなく、Nexusトークンを通じて情報を「要約」し「保持」することで、メモリ使用量を大幅に削減しながら文脈の整合性を保ちます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related