Learn-to-Distance:LLM生成テキスト検出のための距離学習
大規模言語モデル(LLM)が生成したテキストを精度高く識別するため、元のテキストとその書き換え版との間の距離を適応的に学習する新手法「Learn-to-Distance」が提案されました。 幾何学的なアプローチによって、人間が書いた文章はLLMの生成空間から外れているため書き換えによる変化が大きくなるという原理を解明し、固定された指標ではなく学習可能な距離関数を用いることで検出精度を大幅に向上させています。 実験ではGPTやClaude、Geminiなどの最新モデルを含む広範な設定で検証が行われ、既存の強力な手法と比較して57.8%から80.6%の相対的な性能改善を達成し、未知のプロンプトや敵対的攻撃に対しても高い堅牢性を示しました。
TL;DR(結論)
大規模言語モデル(LLM)が生成したテキストを精度高く識別するため、元のテキストとその書き換え版との間の距離を適応的に学習する新手法「Learn-to-Distance」が提案されました。 幾何学的なアプローチによって、人間が書いた文章はLLMの生成空間から外れているため書き換えによる変化が大きくなるという原理を解明し、固定された指標ではなく学習可能な距離関数を用いることで検出精度を大幅に向上させています。 実験ではGPTやClaude、Geminiなどの最新モデルを含む広範な設定で検証が行われ、既存の強力な手法と比較して57.8%から80.6%の相対的な性能改善を達成し、未知のプロンプトや敵対的攻撃に対しても高い堅牢性を示しました。
なぜこの問題か
現代社会において、GPT、Claude、Geminiといった大規模言語モデル(LLM)は、学習や仕事、コミュニケーションのあり方を劇的に変化させました。これらのモデルは教育、学術、ソフトウェア開発、医療など、あらゆる分野で活用されており、メールの草稿作成やコードの記述、プレゼンテーション資料の準備などを効率化しています。しかし、その一方で、LLMが人間と見分けがつかないほど自然な文章を生成できる能力は、深刻な懸念も引き起こしています。具体的には、誤情報の拡散や学術的な誠実性の欠如、著作権や知的財産の帰属に関する問題が挙げられます。ニュースエコシステムにおける偏った情報の流布や、学生による不正利用などは、信頼性の高い検出アルゴリズムの必要性を急務としています。 既存の検出手法は、大きく分けて「能動的検出」と「受動的検出」の2つに分類されます。能動的検出は、モデルの設計段階でテキストに電子透かし(ウォーターマーク)を埋め込む手法ですが、これにはモデル内部へのアクセスが必要です。一方、本研究が焦点を当てている受動的検出は、事前の知識なしにテキストが人間によるものかLLMによるものかを判別します。…
核心:何を提案したのか
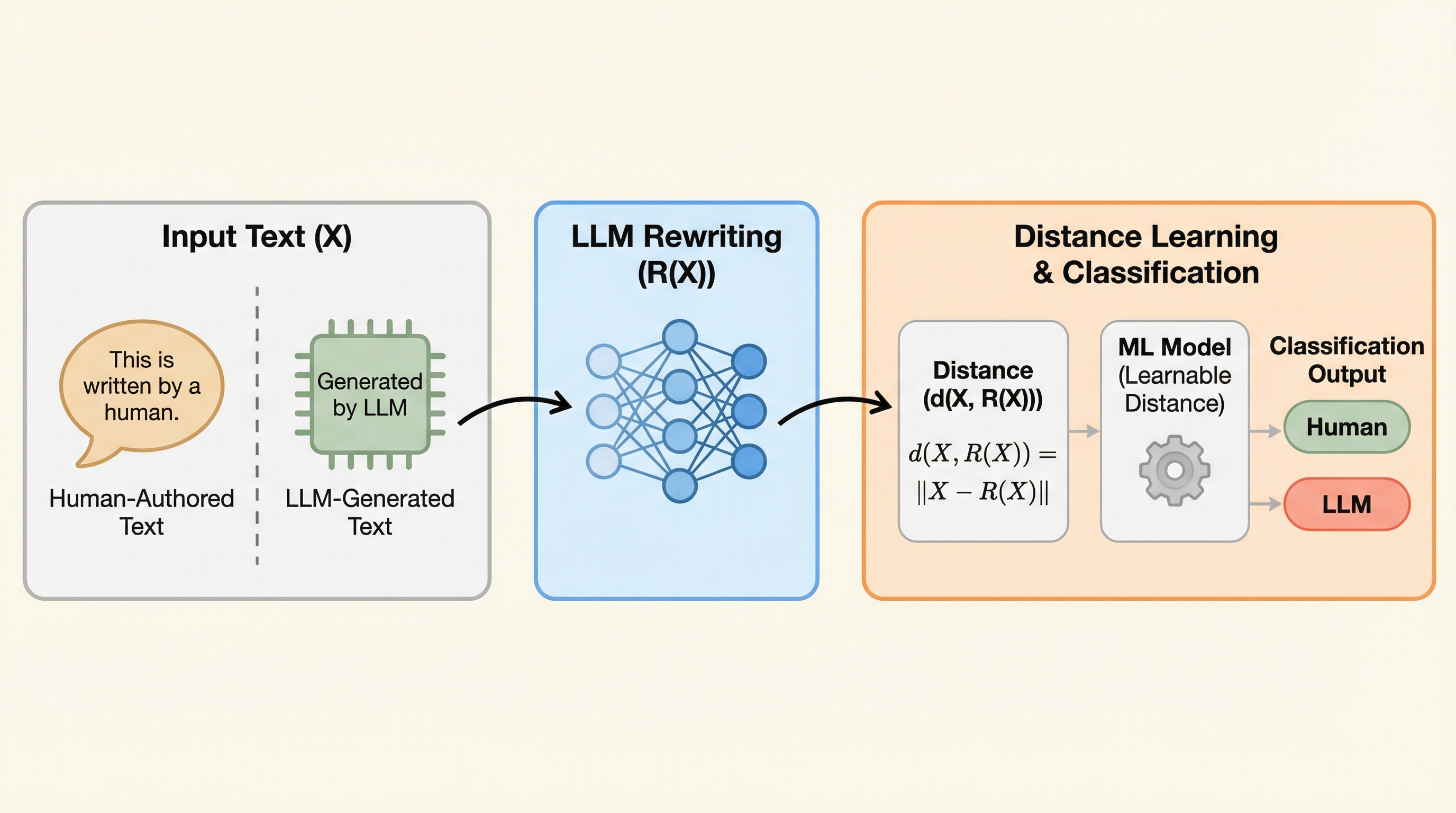
本研究では、LLM生成テキストを検出するための新しい機械学習ベースの書き換え手法「Learn-to-Distance」を提案しています。この手法の核心は、元のテキストとLLMによって書き換えられたテキストの間の「距離」を、固定された数式ではなく、データに基づいて適応的に学習するという点にあります。研究チームはまず、書き換えベースの検出アルゴリズムがなぜ機能するのかを幾何学的な観点から解明しました。彼らの理論によれば、人間が書いた文章とLLMが生成した文章は、埋め込み空間において異なる部分空間に存在しています。LLMによる書き換えプロセスは、入力をLLMの生成空間へと投影する操作と見なすことができます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related