検索注入型推論サンドボックス:検索能力と推論能力を分離するためのベンチマーク
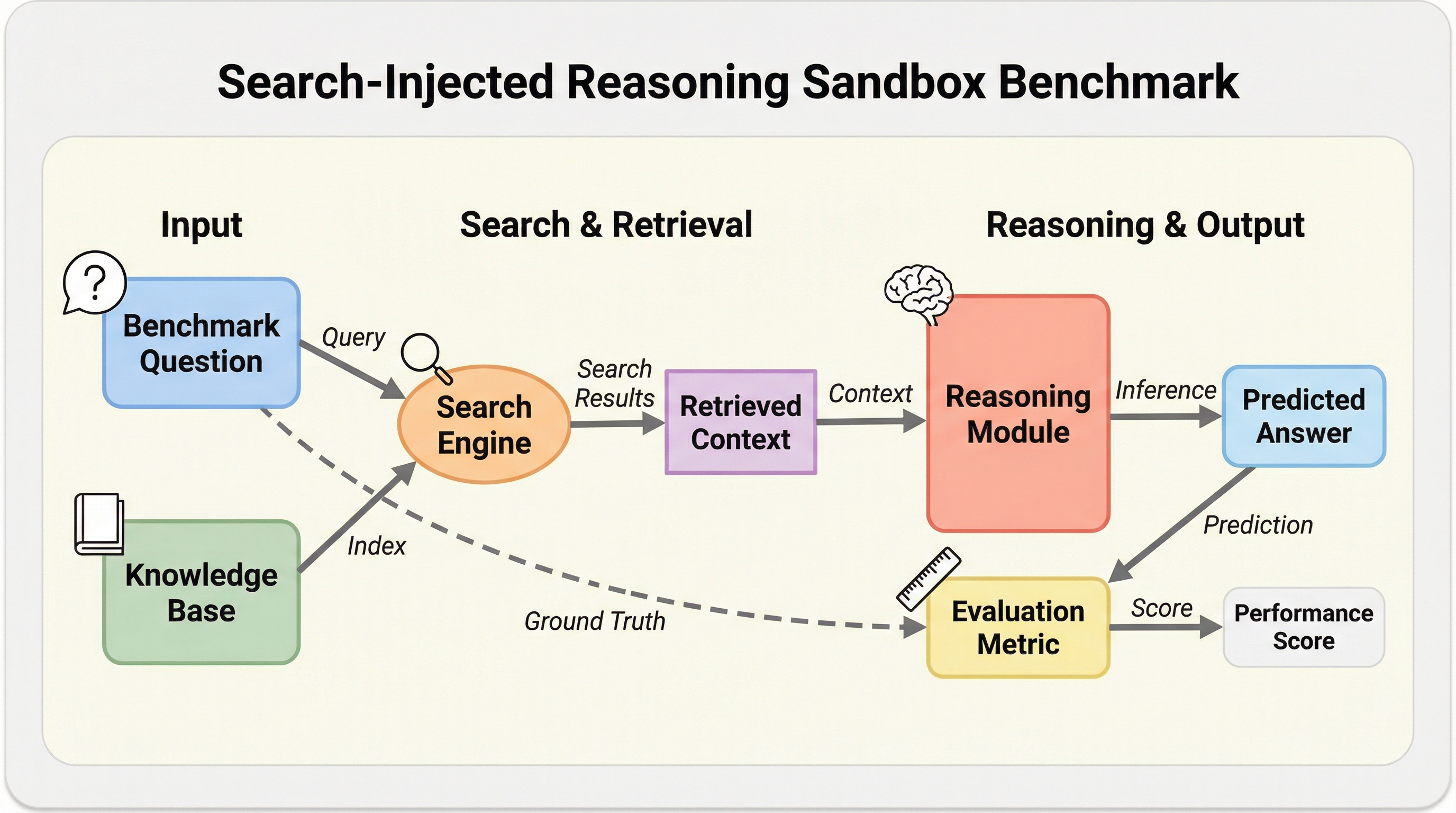
DeR2は、大規模言語モデルが未知の科学的情報に対して推論を行う能力を、検索プロセスから切り離して評価するための新しいベンチマークである。従来の評価手法では検索の失敗か推論の失敗かを判別できなかったが、本手法は2023年から2025年の最新の理論的論文に基づき、情報のアクセスレベルを4段階に分けることでエラーの原因を詳細に特定する。 評価設定として、命令のみ、概念のみ、関連文書のみ、全文書セットの4つのレジームを導入し、モデルがどの段階で性能を低下させているかを「検索損失」と「推論損失」として数値化する。これにより、モデルが学習済みの知識で解いているのか、あるいは提供された証拠を適切に処理して解いているのかを厳密に検証するプロトコルを確立している。 検証の結果、GPT-5.1やGemini-3-Proといった最新モデルでも、文書が与えられると推論モードへの切り替えに失敗する「モード切替の脆弱性」や、概念を正しく認識しても適用できない「構造的な概念の誤用」が明らかになった。このサンドボックスは、検索能力と推論能力の統合における現在の限界を可視化し、次世代AIの開発に向けた重要な指針を提供する。
TL;DR(結論)
DeR2は、大規模言語モデルが未知の科学的情報に対して推論を行う能力を、検索プロセスから切り離して評価するための新しいベンチマークである。従来の評価手法では検索の失敗か推論の失敗かを判別できなかったが、本手法は2023年から2025年の最新の理論的論文に基づき、情報のアクセスレベルを4段階に分けることでエラーの原因を詳細に特定する。 評価設定として、命令のみ、概念のみ、関連文書のみ、全文書セットの4つのレジームを導入し、モデルがどの段階で性能を低下させているかを「検索損失」と「推論損失」として数値化する。これにより、モデルが学習済みの知識で解いているのか、あるいは提供された証拠を適切に処理して解いているのかを厳密に検証するプロトコルを確立している。 検証の結果、GPT-5.1やGemini-3-Proといった最新モデルでも、文書が与えられると推論モードへの切り替えに失敗する「モード切替の脆弱性」や、概念を正しく認識しても適用できない「構造的な概念の誤用」が明らかになった。このサンドボックスは、検索能力と推論能力の統合における現在の限界を可視化し、次世代AIの開発に向けた重要な指針を提供する。
なぜこの問題か
既存のベンチマークにおいて、大規模言語モデルが本当に新しい科学的情報に基づいて推論しているのか、あるいは単に学習済みの知識を思い出しているだけなのかを判別することは極めて困難である。従来の検索拡張生成(RAG)の評価手法は、検索、再ランク付け、要約、推論といった一連の工程をまとめてスコア化するため、どの段階でエラーが発生したのかを特定することができないという構造的な欠陥を抱えている。また、インターネット上の公開情報を用いた評価は、情報の更新や削除といったウェブの変動性の影響を受けやすく、再現性が低いという課題も深刻である。さらに、モデルが学習データとして持っている知識によって正解してしまう「パラメトリックな漏洩」が発生すると、純粋な推論能力を測定するためのシグナルが汚染されてしまう。このような背景から、検索能力と推論能力を明確に分離し、未知の高度な科学的課題に対するモデルの真の対応力を測定するための制御された環境が強く求められている。 現在の深層探索(Deep Research)の評価においては、モデルが多段階の探索やノイズ除去、証拠に基づく合成を行えるかどうかが重要視されている。…
核心:何を提案したのか
本研究では、検索能力と推論能力を分離して評価するための制御された研究用サンドボックスである「DeR2」を提案した。DeR2は、モデルが文書に基づいた推論を行う能力を、検索の難しさを維持したまま隔離して評価することを目的としている。具体的には、証拠へのアクセス方法を「命令のみ」「概念のみ」「関連文書のみ」「全文書セット」という4つのレジームに分割することで、検索による損失と推論による損失を数値化…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related