性能か分散対応か――レイアウト抽象
モデルの「分散」と「カーネル最適化」は、同じ言葉で語れないまま別々に進化してきたのでは? 分散はデバイスメッシュの上で語られ、カーネルはスレッドやメモリ階層の上で語られる──その“距離”が、最適化の議論そのものを難しくしているようにも見えます。
論文図解
TL;DR(結論)
- 提案の中心はAxe Layoutです。
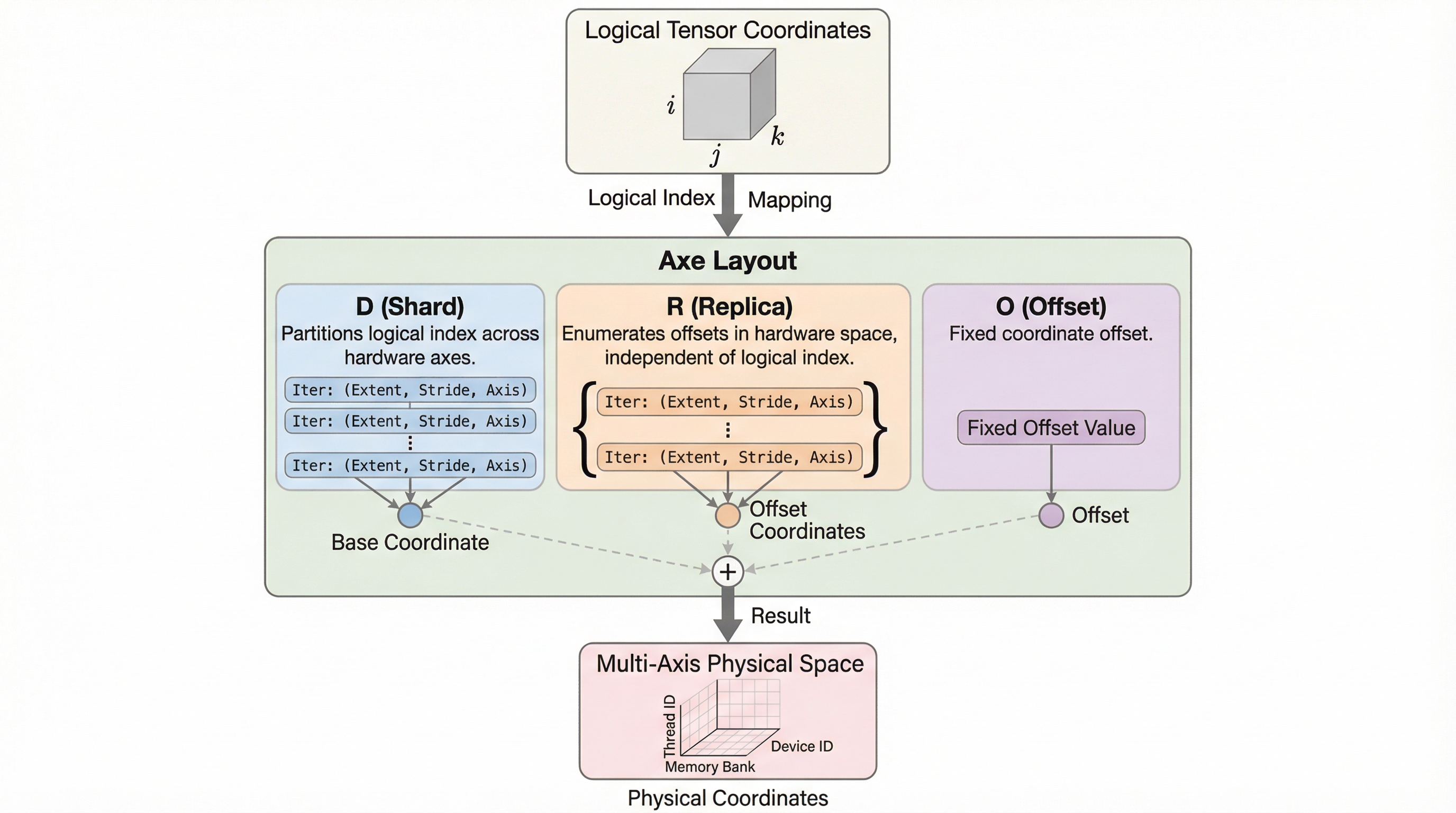
- 論文はこれを「論理テンソルの座標を、名前付きの軸を介して多軸の物理空間へ写像する、ハードウェアを意識した抽象」と説明しています。
- Axe Layoutは、古典的なshape–strideモデルを拡張する、と述べられています。
なぜこの問題か
深層学習のワークロードがスケールすると、データと計算を「どこに置くか」が性能を決めます。論文は、デバイスメッシュ、メモリ階層、そして異種アクセラレータをまたいだ“協調配置”が必要だ、と出発点を置きます。 ここで重要なのは、単に速い命令や速いメモリを使う話ではなく、配置そのものが計算の形を左右する、という見取り図です。
核心:何を提案したのか
提案の中心はAxe Layoutです。論文はこれを「論理テンソルの座標を、名前付きの軸を介して多軸の物理空間へ写像する、ハードウェアを意識した抽象」と説明しています。 ポイントは、論理(モデル側が自然に持つ添字)と物理(実際に走る場所やメモリの形)を、変換の“規則”として捉え直すところにあります。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related