有害性関連グラフによるマルチモーダルデータ内の潜在的な有害性の解明:グラフベースの指標と解釈可能な検出フレームワーク
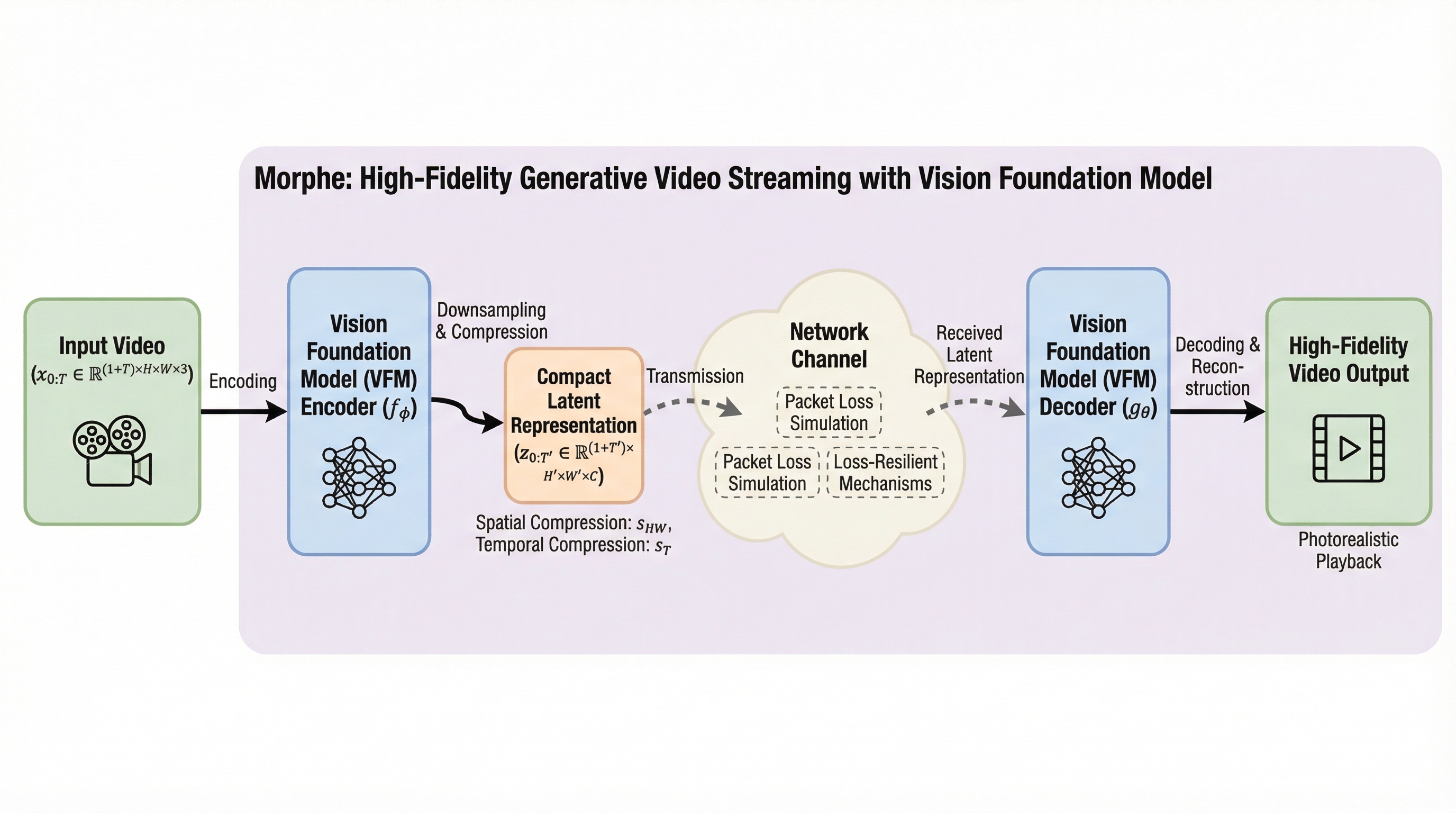
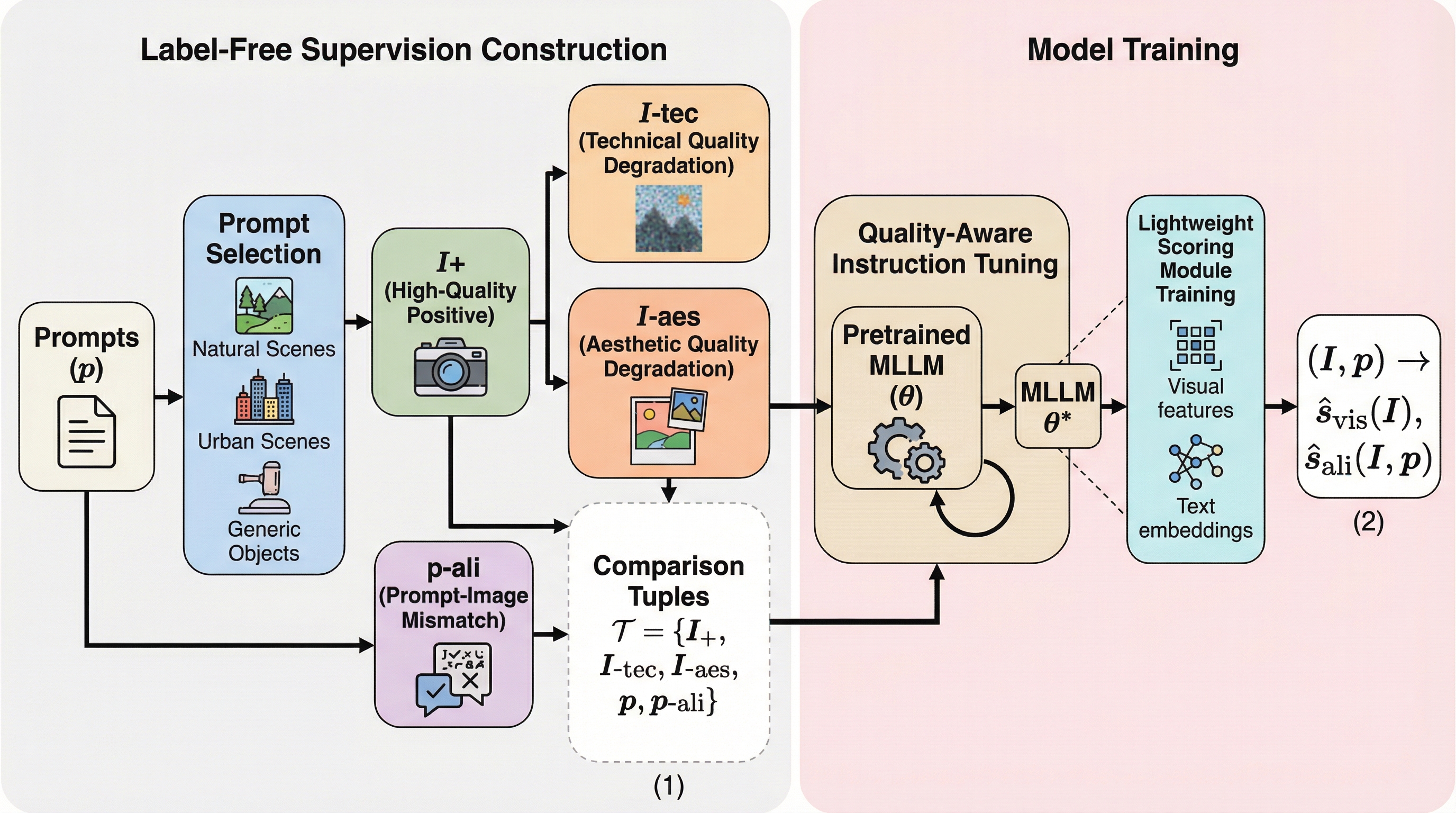
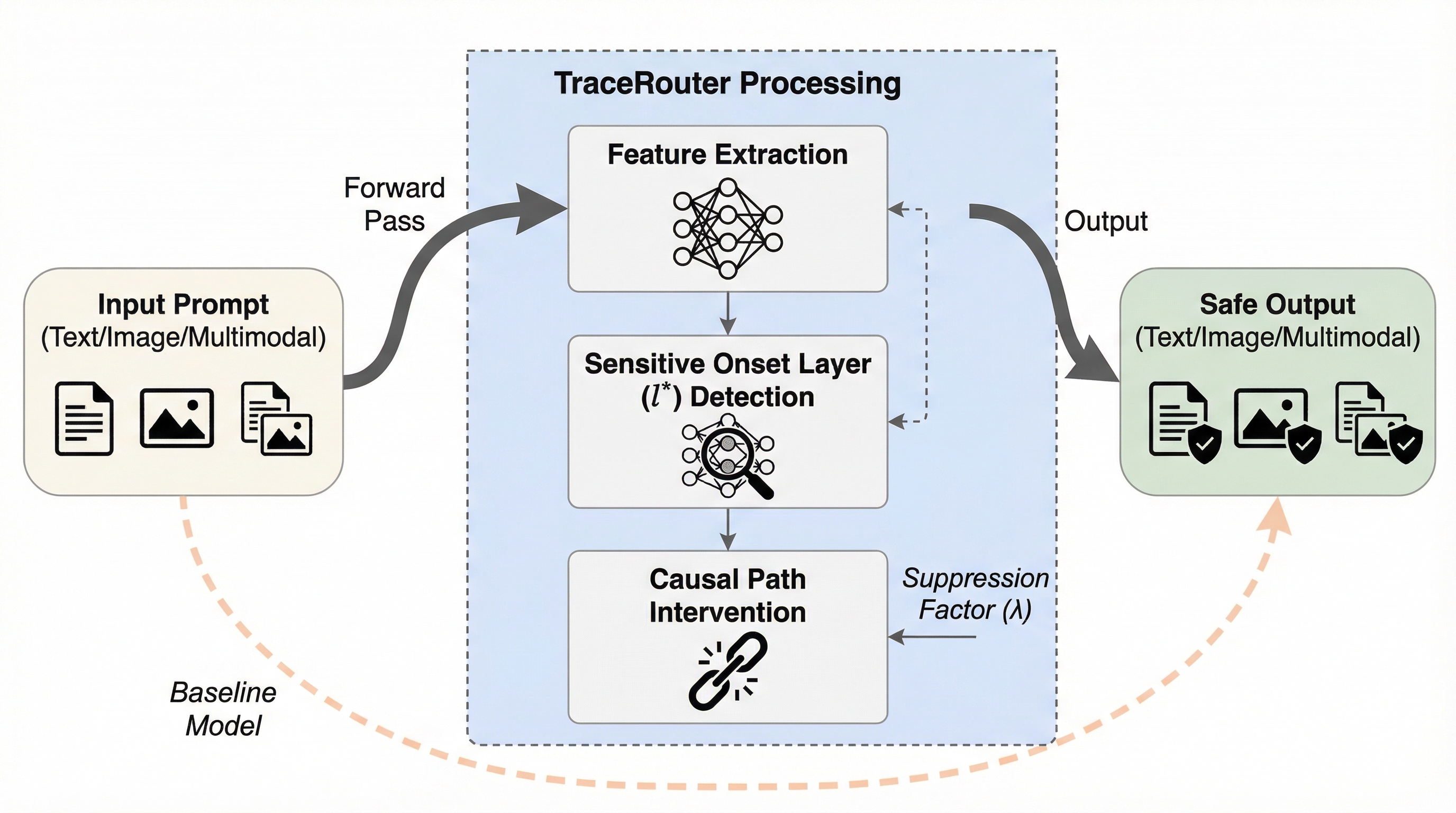
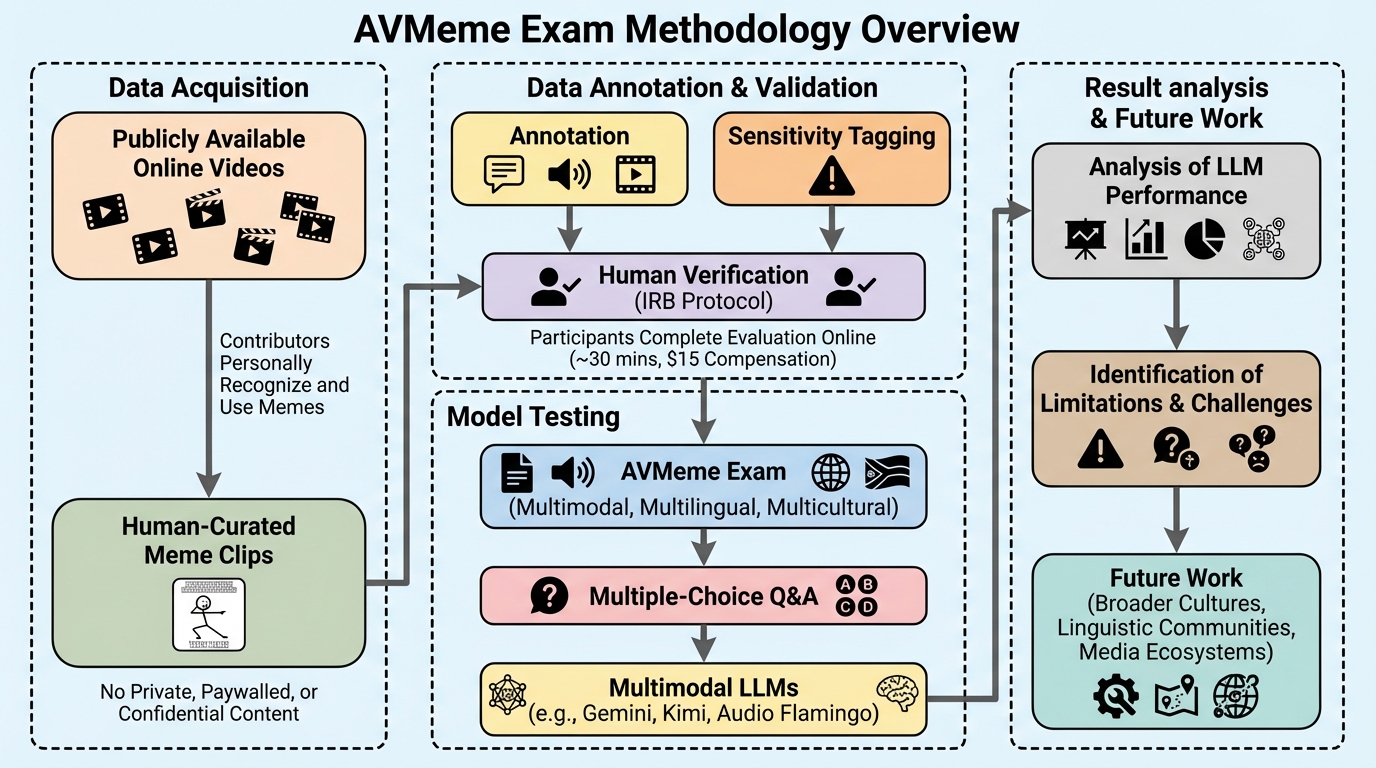
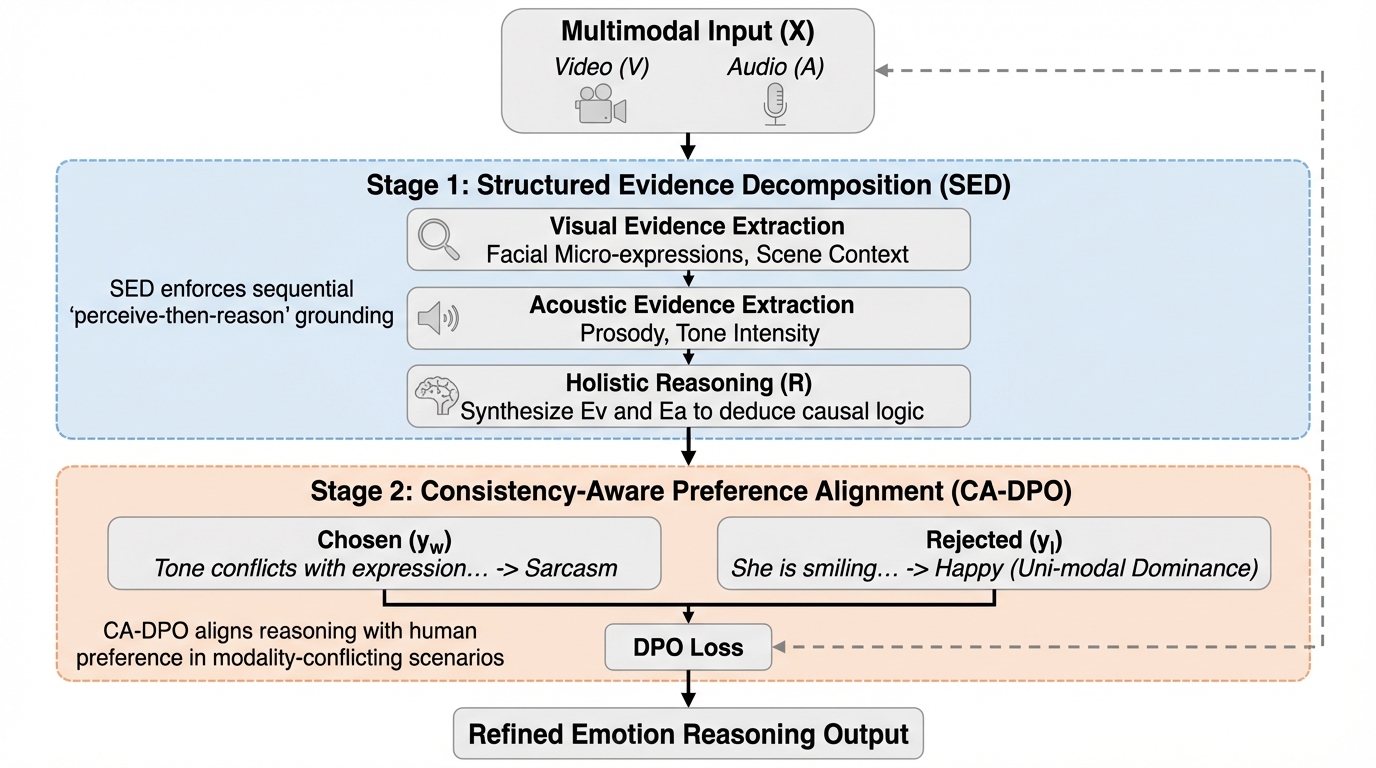
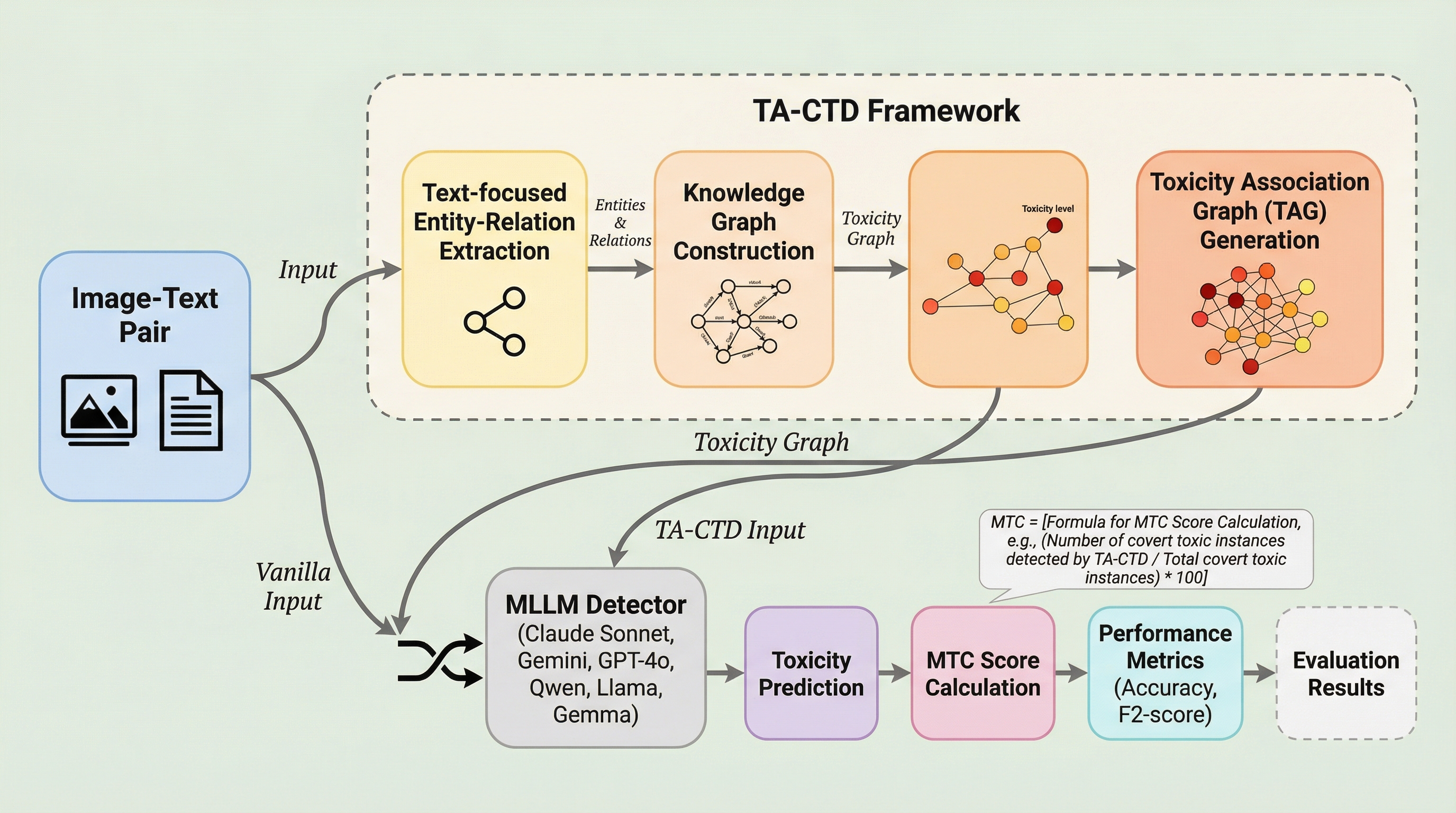
マルチモーダルデータにおいて、画像やテキストが単独では無害に見えても、それらを組み合わせることで潜在的な有害性が生じる「隠れた毒性(Covert Toxicity)」を検出するため、意味的な連想を構造化する「毒性連想グラフ(TAG)」と、その隠蔽度を定量化する世界初の指標「マルチモーダル毒性隠蔽度(MTC)」を提案した。 このグラフ構造に基づき、マルチモーダル大規模言語モデル(MLLM)を用いて毒性の推論経路を明示的に生成する検出フレームワーク「TA-CTD」を開発し、意思決定プロセスの透明性と解釈性を確保しながら、従来の moderation モデルでは見逃されがちな巧妙な有害コンテンツを特定することを可能にした。 高い隠蔽度を持つ事例を収集した初のベンチマーク「Covert Toxic Dataset(CTD)」を構築して評価を行った結果、提案手法は既存の検出手法を精度と説明力の両面で上回り、特に複雑な文化的・文脈的な連想を必要とする高度に隠蔽された毒性の検出において顕著な有効性を示した。