3DGesPolicy:アクション制御に基づく音素を考慮した包括的な発話随伴ジェスチャ生成
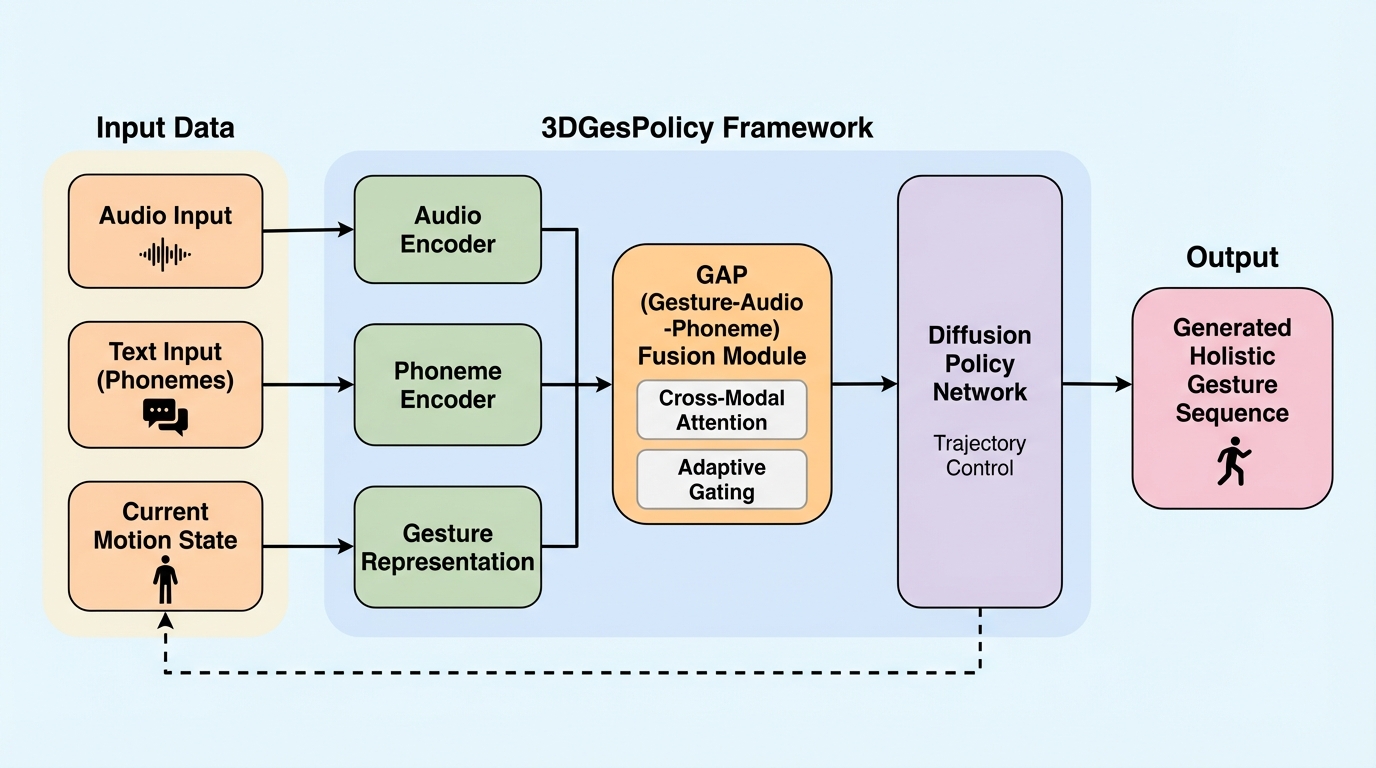
本研究は、ロボット工学の拡散ポリシー(Diffusion Policy)を応用し、全身の動きと顔の表情を統合的に生成する新しいフレームワーク「3DGesPolicy」を提案した。従来のフレーム単位の回帰や部位分解手法が抱えていた、空間的な不安定さや意味的な不整合という課題を解決するため、ジェスチャー生成を「連続的な軌道制御問題」として再定義し、フレーム間の変化を統一された「アクション」としてモデル化している。さらに、音素レベルの言語情報と音響特徴を高度に融合させるGAP(Gesture-Audio-Phoneme)モジュールを導入することで、発話内容と身体動作、唇の動きが精密に同期した、自然で表現力豊かなデジタルヒューマンの挙動を実現し、BEAT2データセットにおいて既存の最先端手法を上回る性能を実証した。
TL;DR(結論)
本研究は、ロボット工学の拡散ポリシー(Diffusion Policy)を応用し、全身の動きと顔の表情を統合的に生成する新しいフレームワーク「3DGesPolicy」を提案した。従来のフレーム単位の回帰や部位分解手法が抱えていた、空間的な不安定さや意味的な不整合という課題を解決するため、ジェスチャー生成を「連続的な軌道制御問題」として再定義し、フレーム間の変化を統一された「アクション」としてモデル化している。さらに、音素レベルの言語情報と音響特徴を高度に融合させるGAP(Gesture-Audio-Phoneme)モジュールを導入することで、発話内容と身体動作、唇の動きが精密に同期した、自然で表現力豊かなデジタルヒューマンの挙動を実現し、BEAT2データセットにおいて既存の最先端手法を上回る性能を実証した。
なぜこの問題か
バーチャルアシスタントやソーシャルロボット、AR/VRテレプレゼンスといった分野において、リアリスティックな3Dデジタルヒューマンの構築は極めて重要な要素となっている。これらのアプリケーションでは、キャラクターの動作の質がユーザーのエンゲージメントやコミュニケーションの有効性に直結するため、音声に同期した自然なジェスチャーの生成が求められている。しかし、身体の動きと顔の表情を統合した「包括的(Holistic)」なジェスチャー生成には、依然として大きな課題が存在する。既存の手法は大きく分けて、身体部位を分解して扱うアプローチと、フレーム単位で回帰を行うアプローチの2つがあるが、それぞれに固有の欠点がある。 部位分解法は、離散的なコードブックを利用して動作を予測するが、身体を量子化されたセグメントに分けることで、部位間の調整や細かな動作のディテールが損なわれやすい。その結果、全身としてのまとまりに欠け、意味的に一貫性のないジェスチャーが生成されることが多い。一方、フレーム単位の回帰手法は、拡散モデルを用いて連続空間でジェスチャーを生成し、多様性を確保しようとする。…
核心:何を提案したのか
本研究の核心は、全身の共話ジェスチャー生成を単なるポーズの予測ではなく、「連続的な軌道制御問題」として再定義した点にある。これを実現するために、ロボットの操作学習で成功を収めている「拡散ポリシー(Diffusion Policy)」のメカニズムをジェスチャー生成の領域に初めて応用した。具体的には、従来のモデルのように絶対的な座標やポーズを直接出力するのではなく、フレーム間の全身および顔の動きの変化を「統一されたアクション(Unified Action)」として定義し、現在の動作状態、音声、および音素レベルの意味情報に基づいた動作軌道を生成する。 このアプローチにより、タスクの性質が静的なポーズの当てはめから、物理的な一貫性を持つ動的な軌道の制御へとシフトする。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related