TraceRouter: 大規模基盤モデルのための経路レベル介入による堅牢な安全性
TraceRouterは、大規模基盤モデルにおける有害情報の伝播を、個別のニューロン単位ではなく複数の層にまたがる「経路(パス)」のレベルで特定し遮断する新しい安全フレームワークである。 従来の防御手法が依存していた局所性仮説の限界を打破し、注意力の分散分析とスパース自己符号化器(SAE)を用いて有害なセマンティクスの回路を精密に特定し、特徴影響スコア(FIS)に基づき因果的な伝播を物理的に断ち切る。 画像生成、言語生成、マルチモーダルの各分野で検証され、モデル本来の生成品質や汎用的な推論能力を維持したまま、敵対的な脱獄攻撃に対しても極めて高い防御成功率と堅牢性を実現することに成功した。
TL;DR(結論)
TraceRouterは、大規模基盤モデルにおける有害情報の伝播を、個別のニューロン単位ではなく複数の層にまたがる「経路(パス)」のレベルで特定し遮断する新しい安全フレームワークである。 従来の防御手法が依存していた局所性仮説の限界を打破し、注意力の分散分析とスパース自己符号化器(SAE)を用いて有害なセマンティクスの回路を精密に特定し、特徴影響スコア(FIS)に基づき因果的な伝播を物理的に断ち切る。 画像生成、言語生成、マルチモーダルの各分野で検証され、モデル本来の生成品質や汎用的な推論能力を維持したまま、敵対的な脱獄攻撃に対しても極めて高い防御成功率と堅牢性を実現することに成功した。
なぜこの問題か
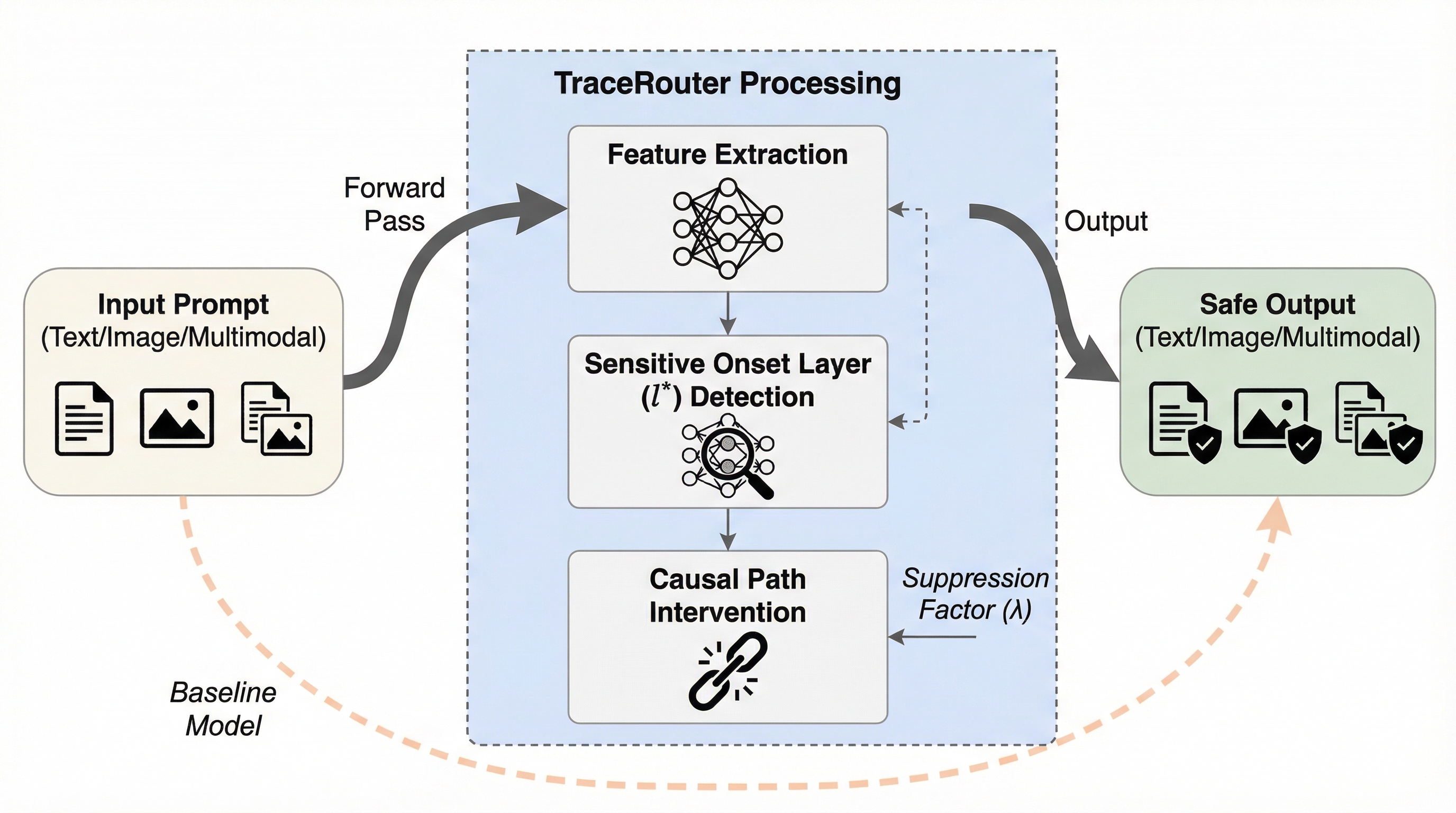
大規模基盤モデル(LFM)の急速な普及に伴い、拡散モデル(DM)や大規模言語モデル(LLM)、マルチモーダル大規模言語モデル(MLLM)における安全性の確保が喫緊の課題となっている。現在の主な安全介入手法は、特定のニューロンや特徴を抑制することで有害な概念を取り除こうとする「局所性仮説」に基づいている。しかし、このアプローチには根本的な欠陥があることが本論文で指摘されている。実際には、有害なセマンティクスは単一のコンポーネントに閉じ込められているわけではなく、複数の層にまたがる複雑な計算経路、すなわち「回路」として分散してエンコードされているからである。このような分散的な性質を無視して特定の点だけを抑制しても、敵対的な誘導によって有害な情報が別の経路を通って漏れ出す「セマンティック・リーク(意味の漏洩)」を防ぐことは困難である。 また、単一のニューロンが複数の意味を持つ「ポリセマンティック(多義的)」な性質を有している場合、無差別に抑制を行うとモデルの本来の能力まで損なわれてしまうという副作用が生じる。…
核心:何を提案したのか
本論文は、モデルのアーキテクチャに依存せず、有害な情報のループを自動的に特定して因果的に遮断する「TraceRouter」というユニバーサルなフレームワークを提案している。このフレームワークは「発見(Discover)」「追跡(Trace)」「切断(Disconnect)」という3つの主要なステージで構成されている。TraceRouterの最大の特徴は、点としての抑制から経路レベルの調整へと視点を転換した点にあり、これにより有害な情報の因果的な伝播を物理的に断ち切ることを目指している。このアプローチは、モデルの重みを大幅に書き換えるファインチューニングやマシンアンラーニングとは異なり、推論時に精密な制御を行うことができるため、計算コストを抑えつつ高い安全性を実現できる。 「発見」ステージでは、注意力の分散を分析することで、背景コンテキストから有害なセマンティクスが最初に発生する「感受性開始層」を特定する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related