識別器駆動型拡散モデルによる教師なし分解と再結合
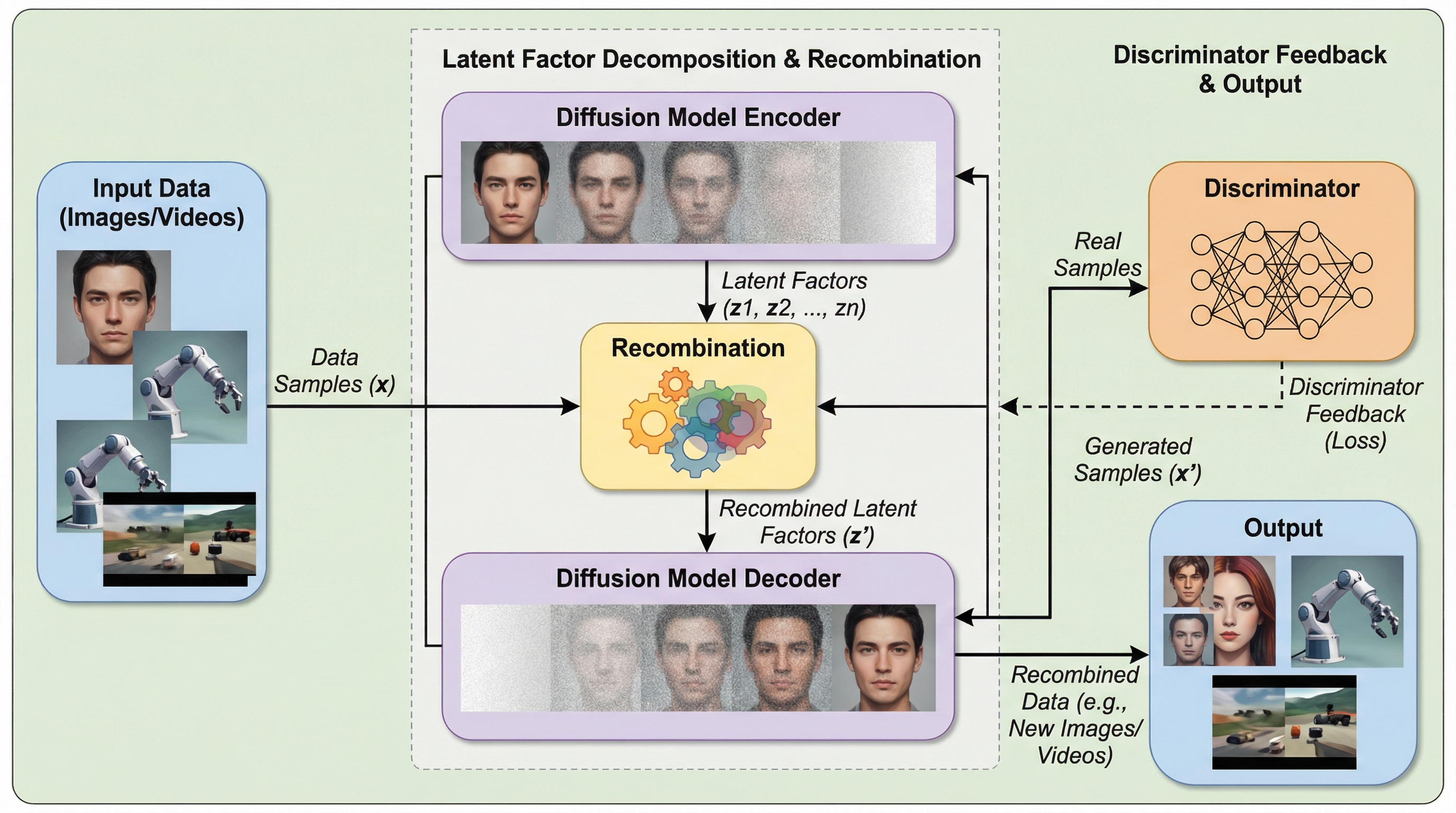
複雑なデータを教師なしで背景、照明、物体の属性、あるいはロボットの動作といった独立した構成要素へと分解し、それらを自在に再結合して新たなサンプルを合成する手法を提案する。本研究では拡散モデルを基盤とし、要素レベルの教師信号を一切必要とせずに、再利用可能な構成要素を抽出する能力を持つ因子化された潜在空間の学習を実現している。 学習過程において、単一のデータ源から生成されたサンプルと、複数のデータ源の構成要素を組み合わせて生成されたサンプルを判別する「識別器」を用いた敵対的学習シグナルを導入した。生成器がこの識別器を欺くように最適化されることで、再結合されたデータにおける物理的および意味的な一貫性が強化され、不自然なアーティファクトの抑制と高品質な合成が可能になる。 CelebA-HQ、Virtual KITTI、CLEVR、Falcor3Dといった画像データセットで、従来手法を上回るFIDスコアと高い解離性を達成した。さらに、ロボットのビデオ軌跡における動作要素の再結合という新しい応用を実証し、LIBEROベンチマークにおいて状態空間の探索範囲を大幅に拡大する多様なシーケンスの生成に成功した。
TL;DR(結論)
複雑なデータを教師なしで背景、照明、物体の属性、あるいはロボットの動作といった独立した構成要素へと分解し、それらを自在に再結合して新たなサンプルを合成する手法を提案する。本研究では拡散モデルを基盤とし、要素レベルの教師信号を一切必要とせずに、再利用可能な構成要素を抽出する能力を持つ因子化された潜在空間の学習を実現している。 学習過程において、単一のデータ源から生成されたサンプルと、複数のデータ源の構成要素を組み合わせて生成されたサンプルを判別する「識別器」を用いた敵対的学習シグナルを導入した。生成器がこの識別器を欺くように最適化されることで、再結合されたデータにおける物理的および意味的な一貫性が強化され、不自然なアーティファクトの抑制と高品質な合成が可能になる。 CelebA-HQ、Virtual KITTI、CLEVR、Falcor3Dといった画像データセットで、従来手法を上回るFIDスコアと高い解離性を達成した。さらに、ロボットのビデオ軌跡における動作要素の再結合という新しい応用を実証し、LIBEROベンチマークにおいて状態空間の探索範囲を大幅に拡大する多様なシーケンスの生成に成功した。
なぜこの問題か
機械学習において、複雑なデータを低次元の潜在空間に符号化する表現学習と、潜在コードからデータを合成する生成モデルは、互いに補完的な役割を果たす重要な柱である。特に、データの生成過程を反映した独立した因子、例えば背景、物体、位置、照明などを個別に抽出する「解離(Disentanglement)」は、分類や回帰、可視化といった下流タスクの性能向上に直結する。しかし、完全な教師なし設定での解離は、追加の仮定なしには理論的に不可能であることが証明されており、適切な帰納バイアスをどのようにモデルに組み込むかが長年の大きな課題となっていた。 現実世界の多くのデータ、特に視覚情報は、離散的または連続的な要素の組み合わせによって構成されている。例えば、川を流れるボートの映像であれば、ボート自体の属性、水の流れ、背景の景色といった要素に分解できる。これらの要素を個別に制御し、学習データには存在しない未知の組み合わせを合成する「構成的汎化」は、モデルの柔軟性を高めるために極めて重要である。…
核心:何を提案したのか
本研究の核心的な提案は、因子化された潜在拡散モデルに対して「識別器(Discriminator)」による敵対的学習シグナルを導入したことである。この識別器は、単一のデータソースから得られた潜在因子のみを用いて生成された「通常のサンプル」と、異なる2つのデータソースから抽出された因子をランダムに入れ替えて合成された「再結合サンプル」を区別するように訓練される。生成器とエンコーダは、この識別器を欺いて再結合サンプルを本物らしく見せるように最適化される。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related