Vision-DeepResearch:マルチモーダル大規模言語モデルにおけるDeepResearch能力の動機付け
既存のマルチモーダル大規模言語モデル(MLLM)は、外部ツールを用いた検索において、画像全体を一度に検索する単純な手法に頼っており、ノイズの多い現実の環境では必要な情報に辿り着けない「ヒット率」の問題や、推論の深さと検索の幅が不足しているという課題を抱えています。
TL;DR(結論)
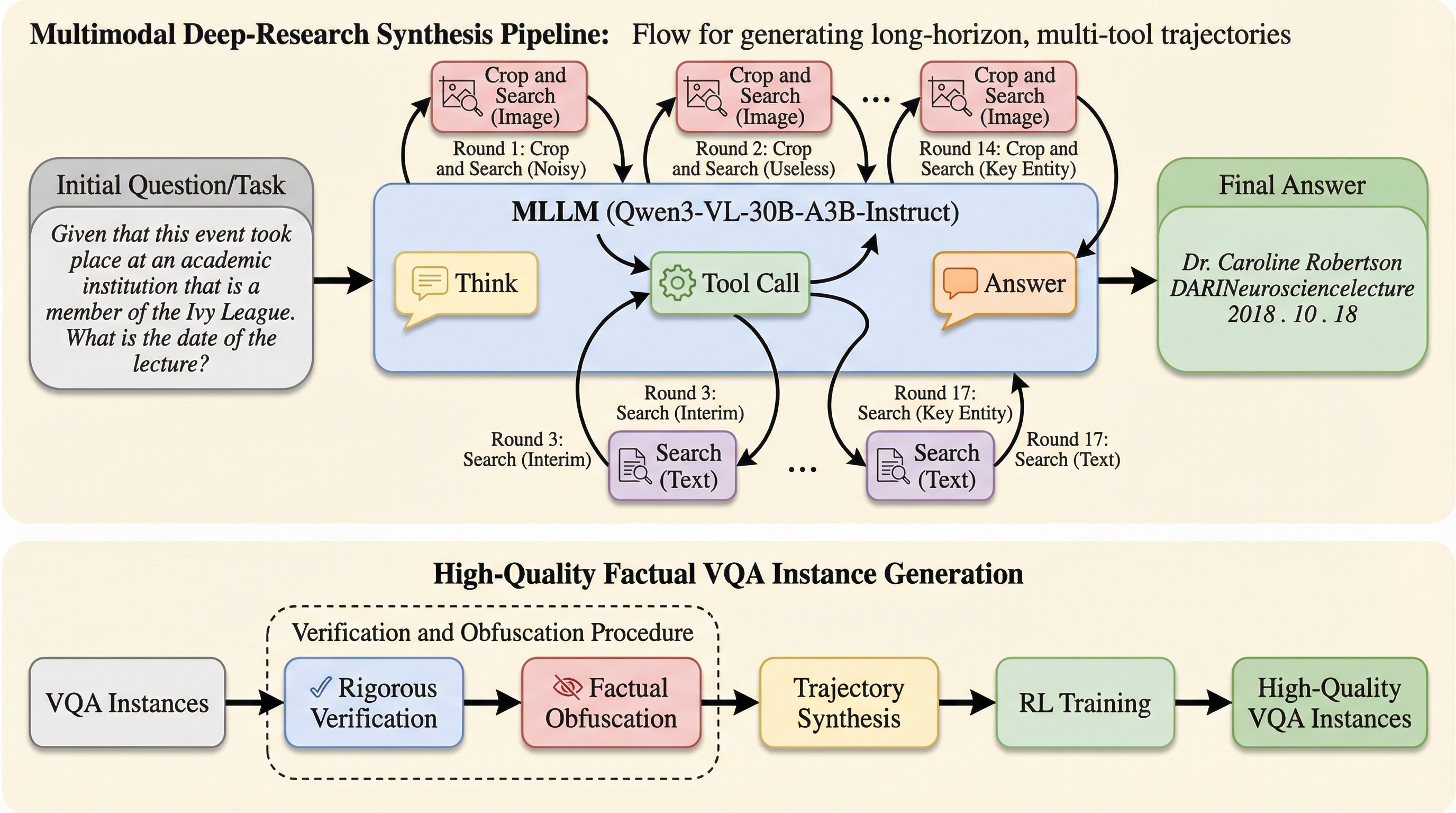
既存のマルチモーダル大規模言語モデル(MLLM)は、外部ツールを用いた検索において、画像全体を一度に検索する単純な手法に頼っており、ノイズの多い現実の環境では必要な情報に辿り着けない「ヒット率」の問題や、推論の深さと検索の幅が不足しているという課題を抱えています。 本研究が提案する「Vision-DeepResearch」は、複数のエンティティや異なるスケールでの画像切り出しを繰り返すマルチターンな視覚・テキスト検索パラダイムを導入し、数十段階の推論ステップと数百回のツール操作を可能にすることで、複雑な事実確認を必要とする問題に対して高い精度で回答を導き出します。 自動化されたデータ生成パイプラインにより、高品質な視覚的質問応答(VQA)インスタンスと長期間の推論軌跡を合成し、強化学習を通じてモデルに深層調査能力を内在化させた結果、GPT-5やGemini-2.5-proなどの強力なクローズドソースモデルを上回る性能を複数のベンチマークで達成しました。
なぜこの問題か
マルチモーダル大規模言語モデル(MLLM)は幅広い視覚タスクで成功を収めていますが、モデル内部に保持されている世界知識には限界があるため、広範な事実情報を必要とする複雑な視覚的質問応答(VQA)は依然として大きな課題となっています。これまでの研究では、推論した後にツールを呼び出す「reasoning-then-tool-call」というパラダイムを用いて、外部の検索エンジンから事実情報を取得することで性能を向上させてきました。しかし、既存の手法におけるマルチモーダル検索は、画像全体または単一のエンティティレベルでのクエリ一回と、少数のテキストクエリだけで必要な証拠が得られるという、現実的ではない単純な設定に基づいています。 現実世界の検索エンジンには膨大な視覚的ノイズが含まれており、画像全体をクエリにしてもターゲットとは無関係な情報に埋もれてしまう「ヒット率」の問題が発生します。また、検索エンジンはヒット率の変動が大きく、同じ視覚的またはテキスト的なエンティティをクエリにしても、クエリのスケールが異なると検索結果が大きく変動するため、一回の検索で確実な証拠を得ることは困難です。…
核心:何を提案したのか
本研究では、現実世界のノイズが激しい検索エンジンに対しても頑健に情報を取得できる新しいマルチモーダル深層調査パラダイム「Vision-DeepResearch」を提案しました。この手法の核心は、単発の検索ではなく、マルチターン、マルチエンティティ、そしてマルチスケールでの視覚およびテキスト検索を実行することにあります。具体的には、数十段階の推論ステップと数百回に及ぶエンジンとの対話をサポートし、複雑な事実確認を自律的に行う能力をMLLMに持たせています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related