AVMeme Exam:LLMの文脈的・文化的知識と思考のためのマルチモーダル・多言語・多文化ベンチマーク
本研究では、インターネット上の音声・映像ミーム1,032件を厳選し、AIモデルが人間の文化的・文脈的な意味をどの程度理解できるかを測定する新しいベンチマーク「AVMeme Exam」を開発しました。
TL;DR(結論)
本研究では、インターネット上の音声・映像ミーム1,032件を厳選し、AIモデルが人間の文化的・文脈的な意味をどの程度理解できるかを測定する新しいベンチマーク「AVMeme Exam」を開発しました。このデータセットは、単なる情報の書き起こしを超え、ユーモアの理由、感情の機微、具体的な使用場面、背景にある世界知識など、人間が共有する深い文化的文脈を問う7つのカテゴリで構成されています。 最新のマルチモーダル大型言語モデル(MLLM)を評価した結果、言語情報の乏しい音楽や効果音の理解、および文化的な文脈に基づいた高度な推論において、人間と比較して依然として顕著な限界があることが明らかになりました。特に、表面的な内容の記述は可能であっても、そのクリップがなぜ社会的に重要で、どのような意図で再利用されるのかという「意味の核心」を捉える能力に大きな課題が残されています。 本ベンチマークは、AIが真に人間と共鳴し、文化的な文脈を共有するアシスタントへと進化するための重要な指針を提供します。評価の結果、最高性能のモデルであっても、非言語的な音響信号から深い意味を抽出するプロセスにおいて人間に及ばず、マルチモーダル知能における「信号の表面」と「文化的な深層」の間の大きな溝を浮き彫りにしました。
なぜこの問題か
人工汎用知能(AGI)の実現には、単なる言葉の習得やテキストの処理能力以上のものが求められます。人間同士のコミュニケーションや知覚は、音や視覚、その他の感覚入力に深く依存しており、それらはテキストだけでは完全に表現しきれない豊かな情報を内包しています。例えば、声に含まれる皮肉のニュアンス、歌に込められた切実な感情、あるいは歌詞のない音楽が伝える勝利や敗北の感覚などは、時間とともに変化する音声や映像の信号を通じて伝達されます。また、ベートーヴェンの「運命」のモチーフやノキアの着信音のように、わずか数秒の音の断片が、世界中の人々に特定の意味や記憶を即座に想起させることもあります。 しかし、現在のマルチモーダル大型言語モデルには、大きな課題が残されています。第一に、音声や映像の信号は韻律、メロディ、テンポ、パッシングなどを通じて意味を伝えますが、これらは言語で記述し尽くせるものではありません。第二に、表面的な内容、つまり「誰が何を言ったか」や「何が映っているか」を理解することは、真の理解の出発点に過ぎません。…
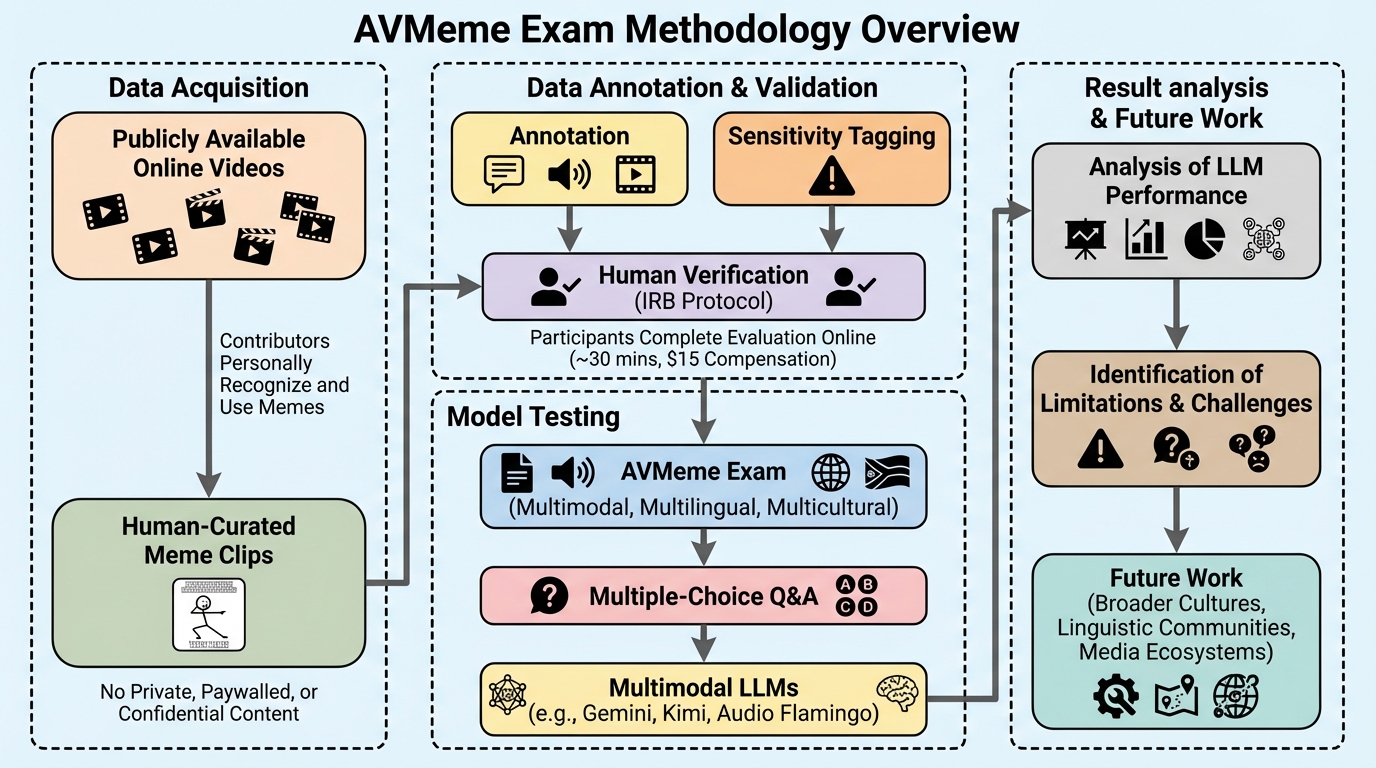
核心:何を提案したのか
本研究は、1,032件の象徴的なインターネット上の音声・映像クリップを収集し、人間が詳細な注釈を付けたベンチマーク「AVMeme Exam」を提案しました。ここで定義される「ミーム」とは、必ずしもユーモラスなものに限定されず、映画の台詞、効果音、音楽のフレーズなど、人々が感情や意図を表現するために再利用するクリップを広く指します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related