サイズは重要:単眼画像からの食事量推定のための実寸3Dモデル再構築
従来の単眼画像からの3D再構築手法では、ブルーベリーとカボチャが同じサイズに見えるような「物理的スケールの欠如」が課題でしたが、本研究はCLIPの視覚的特徴と多角的なレンダリング画像を組み合わせることで、実寸大の3Dモデルを復元する手法を提案しました。
TL;DR(結論)
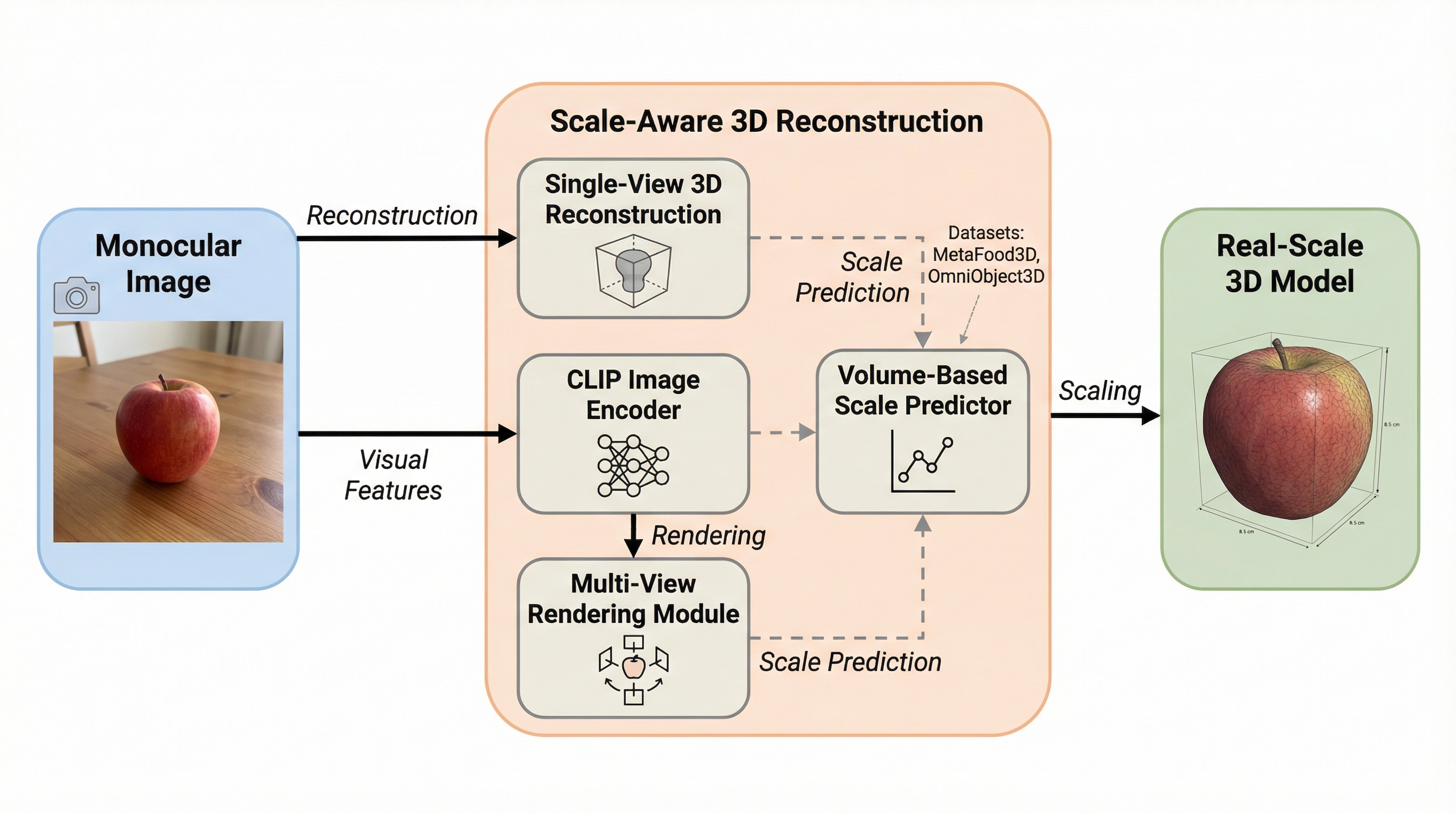
従来の単眼画像からの3D再構築手法では、ブルーベリーとカボチャが同じサイズに見えるような「物理的スケールの欠如」が課題でしたが、本研究はCLIPの視覚的特徴と多角的なレンダリング画像を組み合わせることで、実寸大の3Dモデルを復元する手法を提案しました。 この手法は、入力画像と再構築モデルの投影図から「ボリューム・スケール係数」を推定するReal-Scale Moduleを導入しており、MetaFood3DおよびOmniObject3Dデータセットを用いた検証において、既存手法と比較して平均絶対誤差(MAE)を最大で約30%削減することに成功しました。 正確な体積推定が可能になったことで、単一の画像から食事の摂取量やカロリーを精密に算出する「精密栄養学」の実現に大きく貢献し、食品だけでなく一般的な物体のサイズ推定においても高い汎用性と精度を示すことが確認されました。
なぜこの問題か
現代社会において、肥満や糖尿病、心血管疾患といった食事に関連する慢性疾患の増加は世界的な健康危機となっており、個人の食事摂取量を正確に監視する高度な予防戦略が求められています。精密栄養学の観点からは、何を食べているかだけでなく「どれだけの量を食べたか」を正確に把握することが不可欠ですが、スマートフォンのような単眼カメラで撮影された1枚の画像から、物体の絶対的なサイズや体積(ポーション)を復元することは、数学的に不良設定問題(ill-posed problem)であり、非常に困難な課題とされてきました。 近年のAI技術、特にNeural Radiance Fields(NeRF)や単眼拡散モデルの発展により、1枚の画像から物体の形状(ジオメトリ)を詳細に再構築することは可能になりました。しかし、これらの生成モデルは「正規化された空間」で物体を再構築するため、出力される3Dモデルには現実世界の物理的な単位やスケール情報が含まれていません。その結果、再構築されたモデル上では、小さなブルーベリーと大きなカボチャが全く同じサイズとして表現されてしまうという致命的な欠陥が生じます。…
核心:何を提案したのか
本研究の核心は、3Dコンピュータビジョンとデジタルヘルスケアの橋渡しをすることにあり、単一の画像から物体の形状を復元するだけでなく、その「現実世界での物理的な大きさ」を同時に回復する新しいフレームワークを提案した点にあります。この手法は、大規模データセットで学習された画像エンコーダが、画像内に含まれるシーンの文脈や物体の意味的な特徴から、暗黙的にスケールに関する情報を捉えているという洞察に基づいています。 具体的には、2つの主要なモジュールで構成されるシステムを構築しました。第一のモジュールは、入力された1枚の画像から高品質な3D形状を生成する「3D再構築モジュール」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related