頑健なマルチモーダル感情推論のためのきめ細かい視聴覚証拠の統合
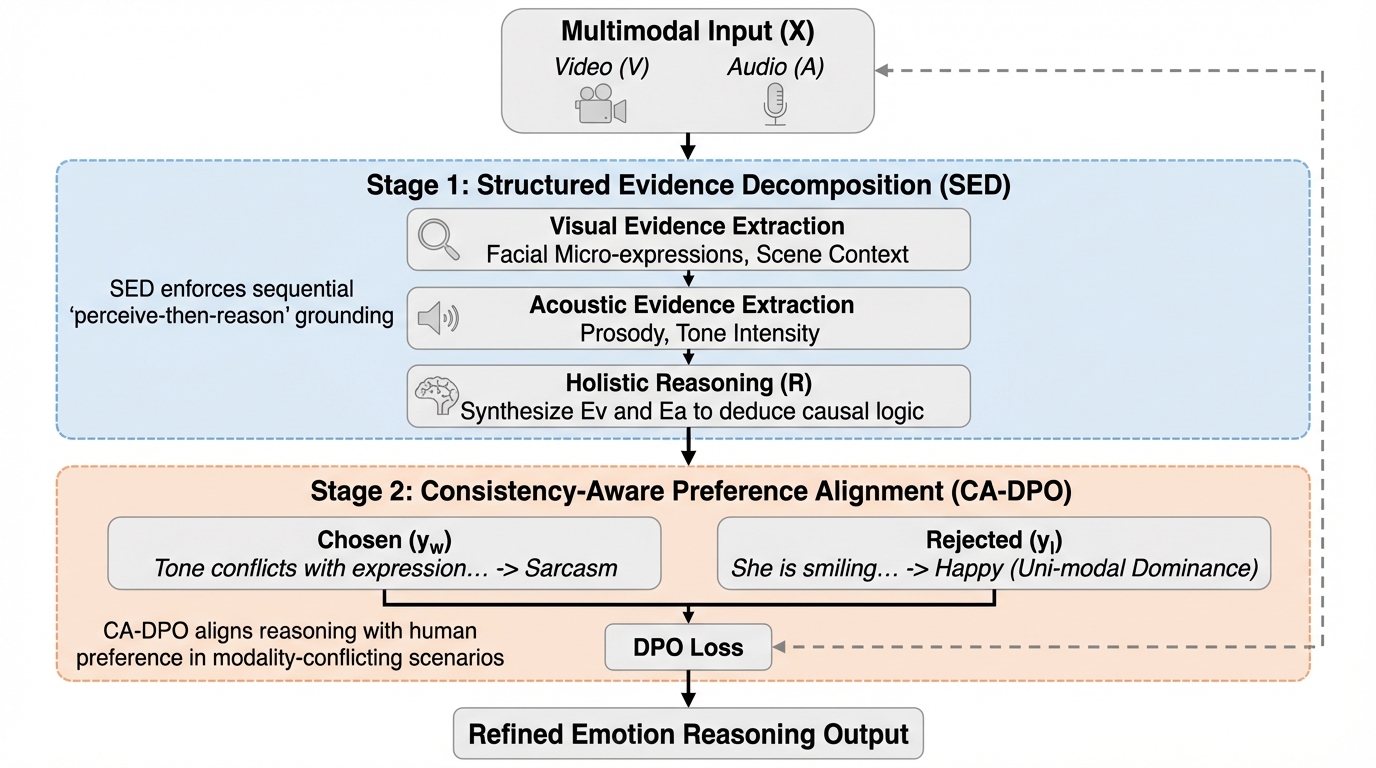
従来のマルチモーダル大規模言語モデルは、視覚と音声の微細な信号を統合できず、特定のモダリティに偏る「単一モダリティ優位」の問題を抱えていました。 本研究では、60万件の動画クリップからなる大規模データセット「SABER」と、証拠抽出を推論から分離する「構造化証拠分解(SED)」パラダイムを提案しました。
TL;DR(結論)
従来のマルチモーダル大規模言語モデルは、視覚と音声の微細な信号を統合できず、特定のモダリティに偏る「単一モダリティ優位」の問題を抱えていました。 本研究では、60万件の動画クリップからなる大規模データセット「SABER」と、証拠抽出を推論から分離する「構造化証拠分解(SED)」パラダイムを提案しました。 この手法により、皮肉などの矛盾する感情表現も正確に解読可能となり、7B規模のモデルでクローズドソースのGemini-2.5-Proに匹敵する性能を達成しました。
なぜこの問題か
マルチモーダル感情分析の分野は、単なる静的なラベル予測から、生成的な推論へと移行しつつあります。複雑な社会的文脈における感情を理解するためには、顔の微細な表情(マイクロエクスプレッション)や、音声の韻律(プロソディ)の変化といった、きめ細やかな信号を統合し、その背後にある潜在的な因果関係を解読する必要があります。しかし、現在のマルチモーダル大規模言語モデル(MLLM)には、微細な知覚能力において大きな限界が存在します。 この限界の主な原因は、高品質なデータの不足と、クロスモーダルな融合メカニズムの不十分さにあります。その結果、モデルは「単一モダリティ優位(unimodal dominance)」と呼ばれる現象に陥りやすくなります。これは、視覚と音声のどちらか一方の顕著な信号に過度に依存し、もう一方のモダリティに含まれる微妙だが重要な証拠を無視してしまう現象です。例えば、話し手が「笑顔」を見せていても、その「声のトーン」が冷ややかであったり、不満げであったりする場合、モデルは笑顔という視覚情報だけに引きずられて「喜び」と誤判定してしまいます。…
核心:何を提案したのか
本研究では、頑健なマルチモーダル感情推論を実現するためのフレームワーク「SABER-LLM」を提案しました。この提案の柱は大きく分けて二つあります。一つ目は、大規模かつ詳細な感情推論データセット「SABER(Scene, Audio, Body, Expression, and Reasoning)」の構築です。二つ目は、モデルの知覚と推論を分離し、モダリティ間の矛盾を解消するための新しい学習パラダイムの導入です。 SABERデータセットは、約60万件の動画クリップで構成される、これまでにない規模の感情推論用データです。このデータセットの最大の特徴は、独自の「6次元アノテーション・スキーマ」を採用している点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related