タスクシフト下におけるベルマンアライメントを用いた楽観的転移学習
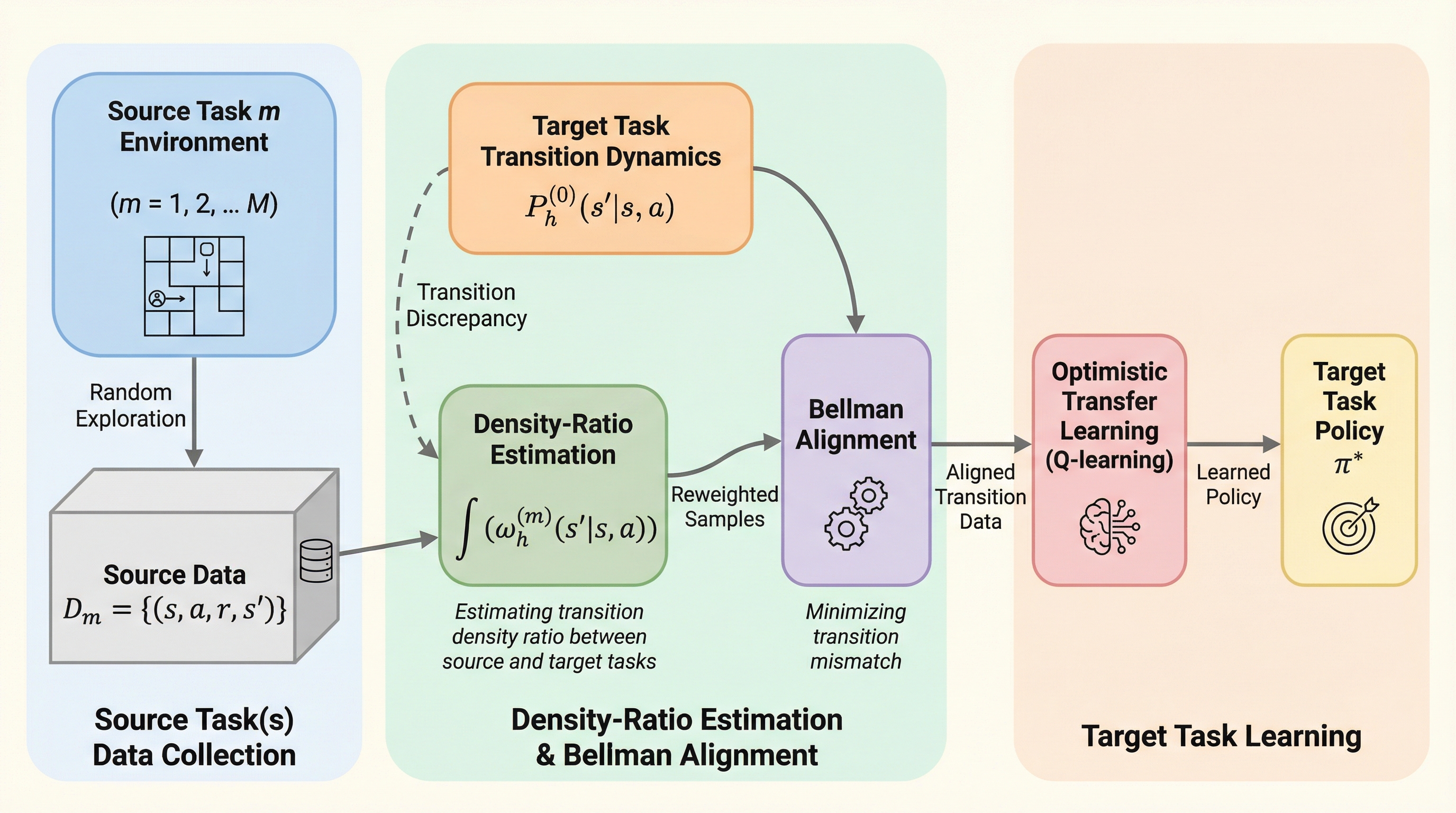
オンライン強化学習において、関連するソースタスクの経験をターゲットタスクに転移させることは、学習を加速させるための自然なアプローチである。しかし、従来のタスク類似性の定義は報酬や遷移のレベルに留まっており、オンライン学習アルゴリズムが実際に操作するベルマン回帰ターゲットとの間に乖離があるため、単純なデータ統合では系統的なバイアスが生じ、探索の理論的保証が損なわれるという構造的な課題があった。本研究では、この問題を解決するために、演算子レベルでベルマンアライメントを行う「再重み付けターゲット(RWT)」を提案し、タスク間の不一致を継続価値に依存しない固定の一段階補正へと変換する手法を確立した。このアライメントに基づく二段階のQ学習フレームワークは、RKHS関数近似の設定において、リグレット界がターゲットタスク全体の複雑さではなくタスク間のシフトの複雑さに依存することを理論的に証明し、シミュレーションおよびニューラルネットワークを用いた実験の両方で、単一タスク学習やナイーブなデータ統合を上回る一貫した性能向上を実証している。
TL;DR(結論)
オンライン強化学習において、関連するソースタスクの経験をターゲットタスクに転移させることは、学習を加速させるための自然なアプローチである。しかし、従来のタスク類似性の定義は報酬や遷移のレベルに留まっており、オンライン学習アルゴリズムが実際に操作するベルマン回帰ターゲットとの間に乖離があるため、単純なデータ統合では系統的なバイアスが生じ、探索の理論的保証が損なわれるという構造的な課題があった。本研究では、この問題を解決するために、演算子レベルでベルマンアライメントを行う「再重み付けターゲット(RWT)」を提案し、タスク間の不一致を継続価値に依存しない固定の一段階補正へと変換する手法を確立した。このアライメントに基づく二段階のQ学習フレームワークは、RKHS関数近似の設定において、リグレット界がターゲットタスク全体の複雑さではなくタスク間のシフトの複雑さに依存することを理論的に証明し、シミュレーションおよびニューラルネットワークを用いた実験の両方で、単一タスク学習やナイーブなデータ統合を上回る一貫した性能向上を実証している。
なぜこの問題か
強化学習エージェントは、シミュレーションから現実世界への転移や、ユーザー間のパーソナライズ、あるいは異なる市場間での意思決定など、関連するタスクの経験が利用可能な環境で展開されることが増えている。新しいターゲットタスクでの学習を加速させるために、これらのソースタスクの経験を活用することは実用上極めて自然な発想である。しかし、探索を伴うオンライン転移学習において、原理的な保証を伴う形でデータを再利用することは依然として困難な課題として残されている。既存の理論の多くは、ターゲットタスクを他のタスクから孤立させて扱うか、あるいはオンライン強化学習アルゴリズムが実際に学習を進める仕組みとは整合しない仮定に依存しているのが現状である。 この問題の中心的な障害は、タスクの類似性がオンライン強化学習が動作するレベルで定義されていないことにある。現代の強化学習アルゴリズムは、継続価値と遷移分布の両方に依存する一段階のベルマンターゲットを回帰することで学習を進める。そのため、報酬や遷移、あるいは価値関数に基づいた類似性の仮定は、そのまま再利用可能なベルマンサンプルに変換されるわけではない。…
核心:何を提案したのか
本研究では、オンライン転移学習における構造的な障害を解決するために、「再重み付けターゲット(RWT)」と呼ばれる演算子レベルのベルマンアライメントを提案した。RWTは、継続価値をターゲットタスクに合わせ直すと同時に、測度変換(密度比)を通じて遷移の不一致を補正する仕組みである。このアライメントにより、ベルマン不一致から継続価値への依存性が完全に取り除かれ、タスク間の不一致を固定された一段階の補正として扱うことが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related