幾何学的潜在部分空間を用いた離散データの生成モデリング
離散データの生成モデルを構築するため、カテゴリ分布の積多様体における指数パラメータ空間内に低次元の潜在部分空間を導入する「幾何学的主成分分析(GPCA)」を提案した。この手法は、離散変数間の統計的依存関係を符号化しつつ冗長な自由度を排除することで、高次元データの効率的な圧縮と正確な表現を可能にする。
TL;DR(結論)
離散データの生成モデルを構築するため、カテゴリ分布の積多様体における指数パラメータ空間内に低次元の潜在部分空間を導入する「幾何学的主成分分析(GPCA)」を提案した。この手法は、離散変数間の統計的依存関係を符号化しつつ冗長な自由度を排除することで、高次元データの効率的な圧縮と正確な表現を可能にする。 パラメータ領域に独自のリーマン幾何学(e-metric)を導入することで、潜在空間とデータ多様体の間の距離を等長写像によって関連付け、測地線が直線となる効率的なフローマッチングを実現した。この幾何学的構成により、低次元の潜在空間上での学習が計算効率の高いものとなり、従来の計量を用いる手法よりも簡潔な目的関数で最適化が行える。 実験ではMNISTなどの高次元データセットにおいて、大幅な次元削減を行いながらデータを正確に再現できることが示された。教師なし学習による幾何学的な埋め込みによって、離散データの統計的性質を保持したまま、効率的な生成プロセスを実行できることが実証されている。
なぜこの問題か
機械学習において離散データの生成モデルを構築することは、近年の研究における主要な課題の一つとなっている。特に、カテゴリ変数の結合確率分布を扱う際、データの表現方法とその変数が定義される空間の幾何学的構造が、モデルの性能を左右する重要な要素となる。従来の生成モデルでは実数値変数の量子化や直接的な離散表現が試みられてきたが、高次元の離散データを正確に符号化しつつ、その統計的依存関係を効率的に学習することは依然として困難であった。 通常、離散データの結合分布を扱う場合、変数の数が増えるにつれて非負テンソルのサイズが指数関数的に増大し、計算が実質的に不可能になるという問題に直面する。このため、古典的な変分平均場近似のように、各変数が独立であると仮定する完全分解積分布が用いられることが多い。しかし、このような単純な独立性の仮定では、データセット内に存在する複雑な統計的相関を捉えることができず、生成モデルとしての表現力が制限されてしまう。 また、データの次元削減において広く用いられる主成分分析(PCA)を離散データに直接適用する場合、ユークリッド空間への埋め込みがデータの離散的な性質を十分に反映できないという課題がある。…
核心:何を提案したのか
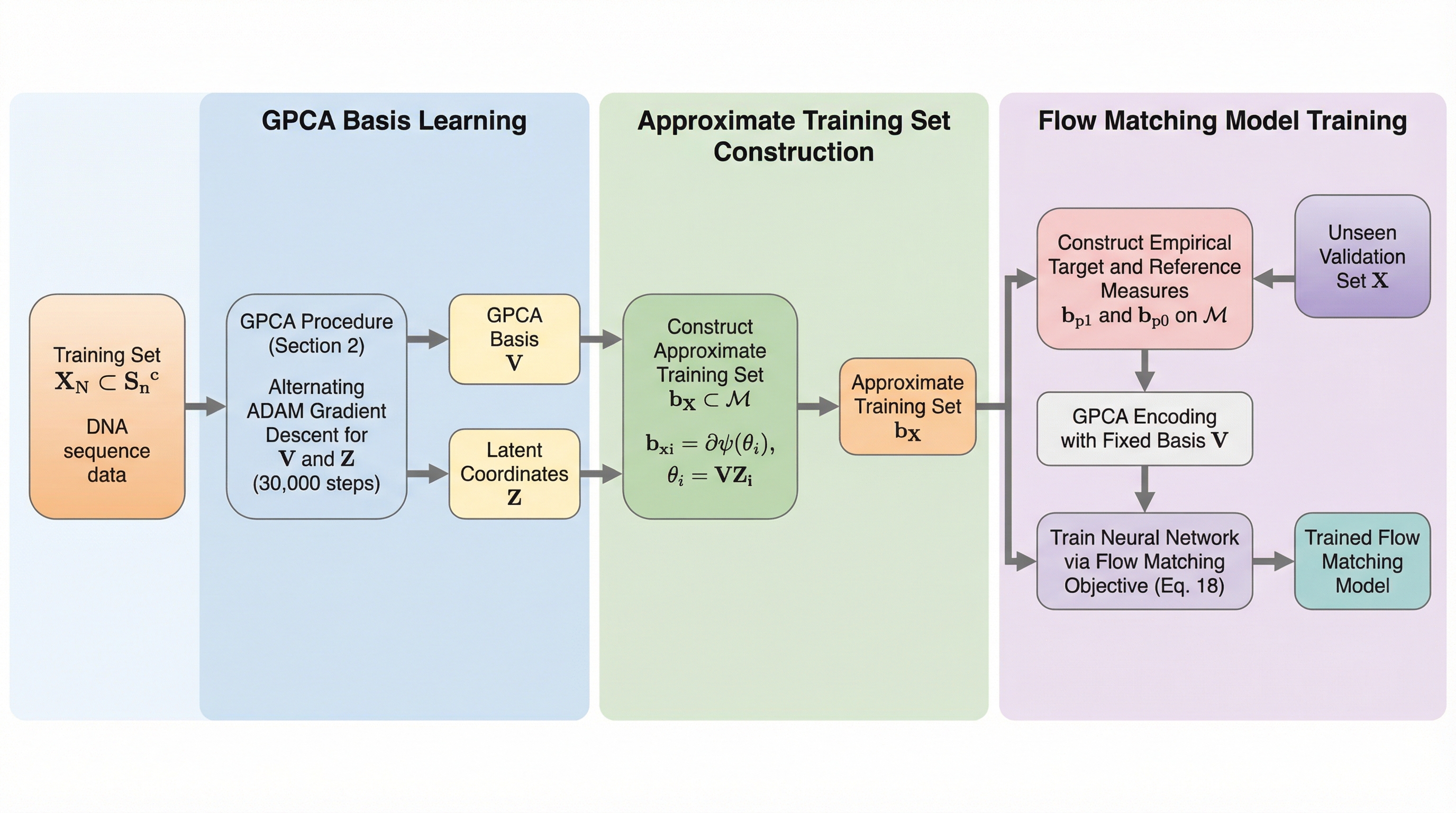
本研究の主な貢献は、離散データの正確な符号化、高次元データの圧縮、および生成モデルの設計を統合した幾何学的アプローチを提案したことにある。具体的には、離散的な結合分布を統計多様体として捉える情報幾何学の枠組みに基づき、古典的な一般化PCAを拡張した「幾何学的主成分分析(GPCA)」を導入した。この手法では、カテゴリ分布の指数パラメータ空間(自然パラメータ空間)内に、低次元の線形部分空間を潜在空間として定義する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related