正解ラベルなしでLLMを評価する「審査員考慮型」ランキングフレームワーク
大規模言語モデル(LLM)の評価において、別のLLMを審査員として用いる手法が普及していますが、審査員ごとの信頼性の違いを無視して一律に扱うと、ランキングに偏りが生じ、データが増えるほど誤った結論に対して過剰な自信を持ってしまうという統計的な問題があります。
TL;DR(結論)
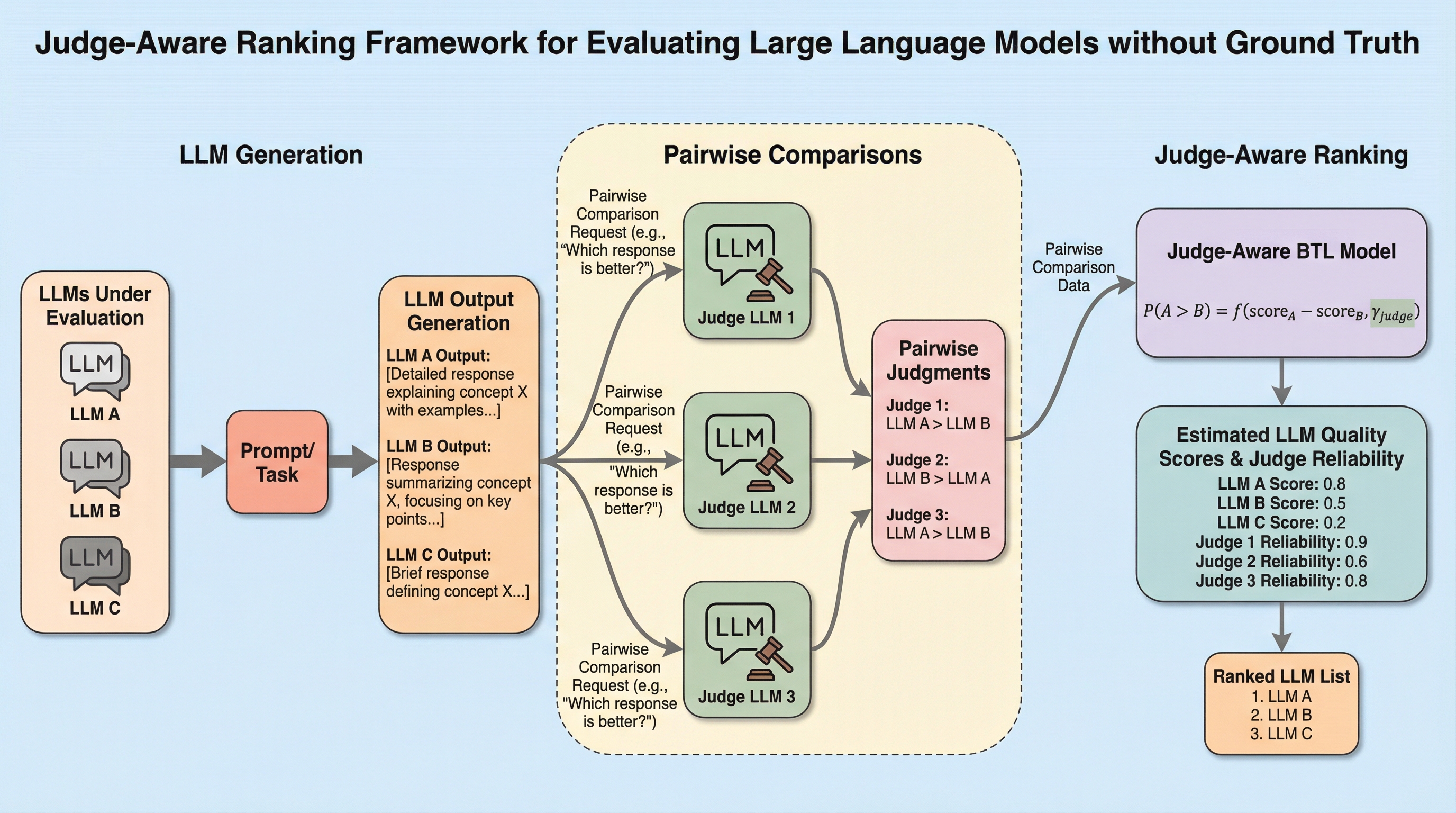
大規模言語モデル(LLM)の評価において、別のLLMを審査員として用いる手法が普及していますが、審査員ごとの信頼性の違いを無視して一律に扱うと、ランキングに偏りが生じ、データが増えるほど誤った結論に対して過剰な自信を持ってしまうという統計的な問題があります。 本研究は、従来のBradley–Terry–Luceモデルを拡張し、審査員固有の「識別パラメータ」を導入することで、正解ラベルがない状態でもモデルの品質と審査員の信頼性を同時に推定する「審査員考慮型」ランキングフレームワークを提案しました。 実験の結果、この手法は人間の好みに高い精度で一致し、少ないデータ量で効率的に評価を行えるだけでなく、統計的な不確実性を正確に数値化できる信頼区間の算出を可能にし、より科学的で堅牢なリーダーボードの構築を実現しました。
なぜこの問題か
LLMが汎用的なアシスタントとして急速に普及する中で、その能力を正確に比較し、順位付けすることは、研究開発の方向性決定や実社会への導入判断において極めて重要な課題となっています。MMLUやBIG-Benchといった従来のベンチマークスイートは、数学や知識問題など正解が明確なタスクでの能力測定には非常に有効ですが、自由形式の対話や創造的な文章作成といった、ユーザーの主観的な好みが関わるオープンエンドなタスクにおける性能を十分に捉えきれないという限界があります。人間による評価は最も直接的で信頼できる信号を提供しますが、膨大なコストと時間がかかり、再現性を確保することも困難です。 これらの制限を克服するために、LLMを審査員として利用して他のモデルの出力を評価させる「LLM-as-a-judge」という枠組みが、スケーラブルで参照不要な評価インフラとして広く採用されるようになりました。しかし、このパラダイムには、審査員として機能するLLM自体の信頼性がモデルごとに大きく異なるという、これまで見過ごされてきた重大な問題があります。…
核心:何を提案したのか
本研究では、ペア比較データからモデルの品質スコアと審査員の信頼性を同時に推定する、新しい「審査員考慮型(Judge-Aware)」ランキングフレームワークを提案しています。このフレームワークは、統計的なランキングモデルとして長い歴史を持つBradley–Terry–Luce(BTL)モデルを基礎とし、それを現代のLLM評価の文脈に合わせて拡張したものです。具体的には、各審査員に対して固有の「識別パラメータ(discrimination parameter)」を導入し、審査員がモデル間の品質差をどれだけ敏感に察知できるかを数理モデルに組み込みました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related