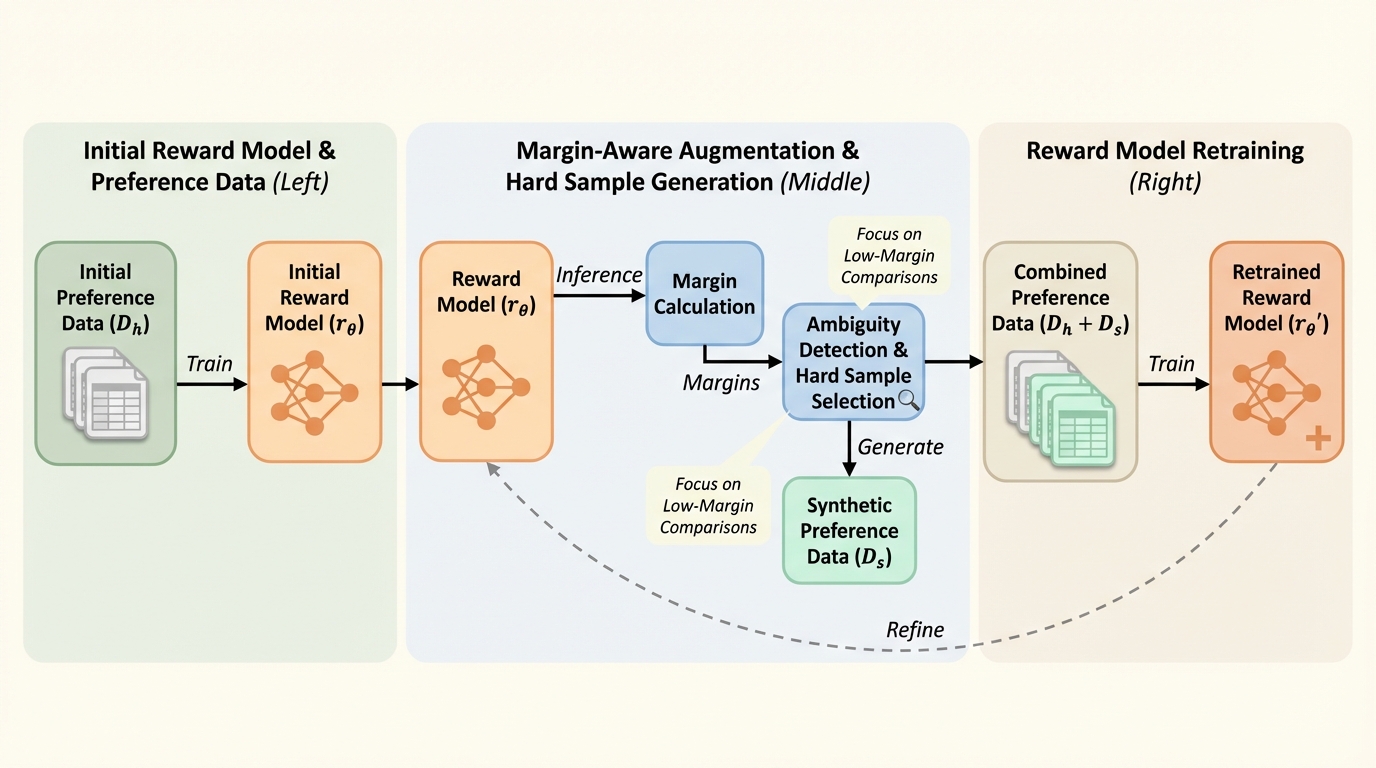
MARS:マージンを考慮した自己洗練による報酬モデリング――曖昧さ(低マージン)へ学習を寄せる適応的データ拡張
人手の選好データに強く依存する報酬モデリングでは、どの比較が「判断しにくいか」を無視して一様に増やしても、モデルの弱点に学習が届かない可能性があるため、推定が難しい領域を狙って鍛える発想が重要です。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
人手の選好データに強く依存する報酬モデリングでは、どの比較が「判断しにくいか」を無視して一様に増やしても、モデルの弱点に学習が届かない可能性があるため、推定が難しい領域を狙って鍛える発想が重要です。
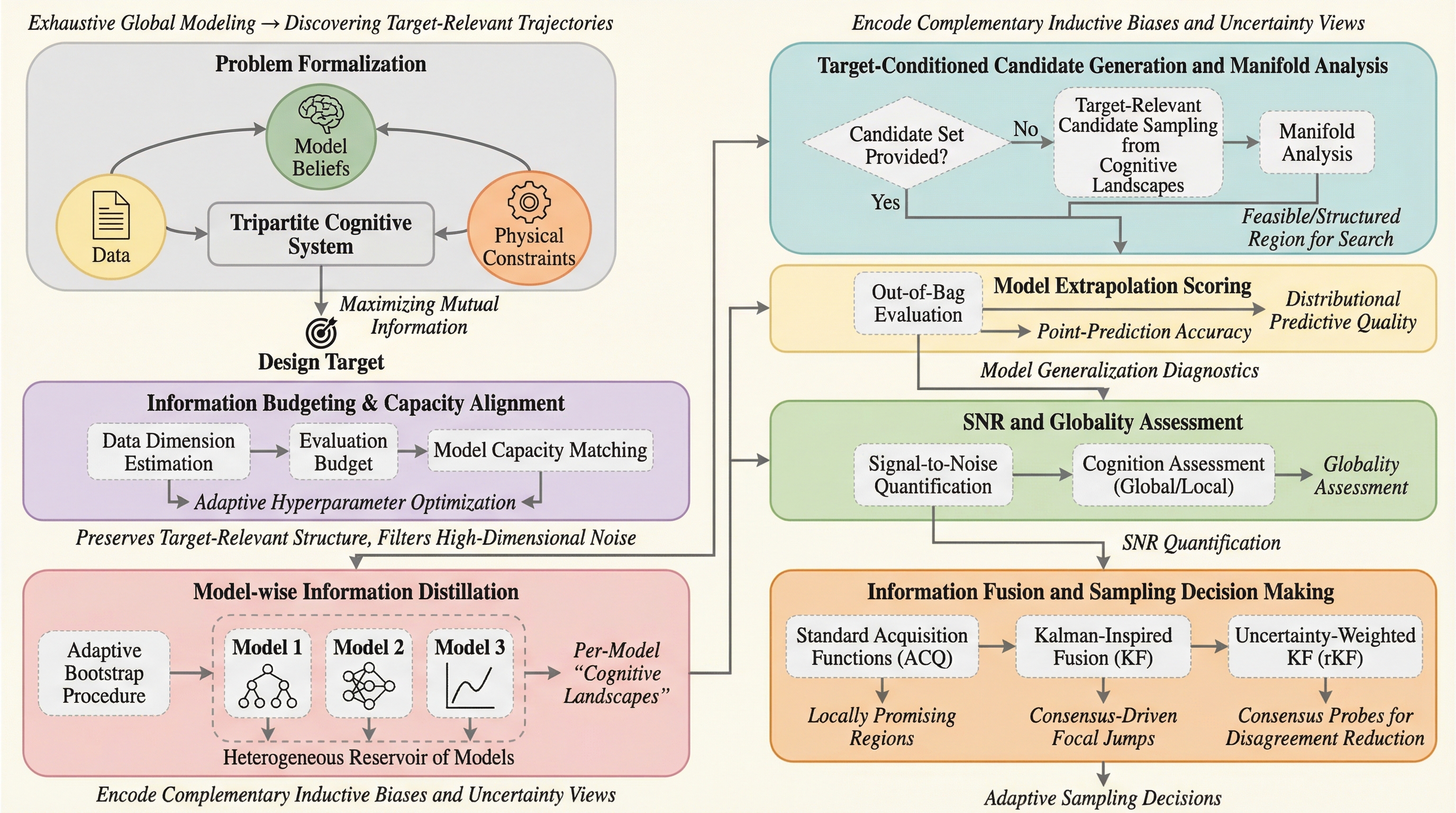
現代の材料科学における高次元かつ極めてデータが不足している環境下で、効率的に目標を達成するための情報理論に基づいた新しい適応的サンプリングの枠組みが提案されました。この手法は、全探索空間を近似するのではなく、目標に関連する「軌道」を特定することに焦点を当て、次元を考慮した情報予算管理や、カルマンフィルタに着想を得たマルチモデル融合を組み合わせています。14種類の材料設計タスクと複雑な数理ベンチマークを用いた検証により、わずか100回程度の評価でトップクラスの性能を持つ領域に到達できる高いサンプル効率と、多様な問題に対する堅牢性が実証されました。
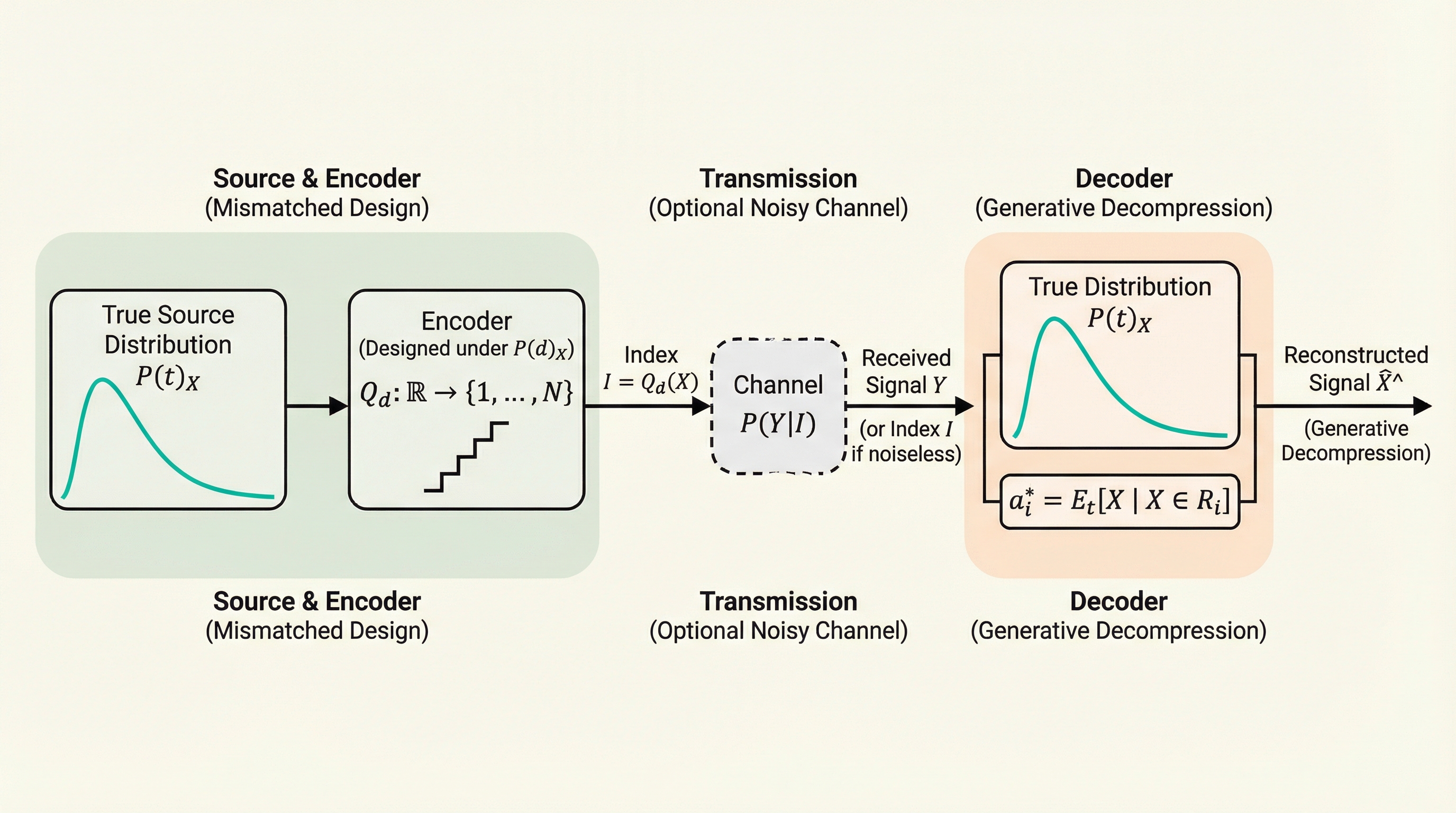
本論文は、圧縮機の設計時に想定したデータ分布と実際のソース分布が異なる「分布の不一致」が発生する状況において、送信側のエンコーダを一切変更することなく、受信機側のみの調整で歪みを最小化する「生成デコンプレッション」を提案している。
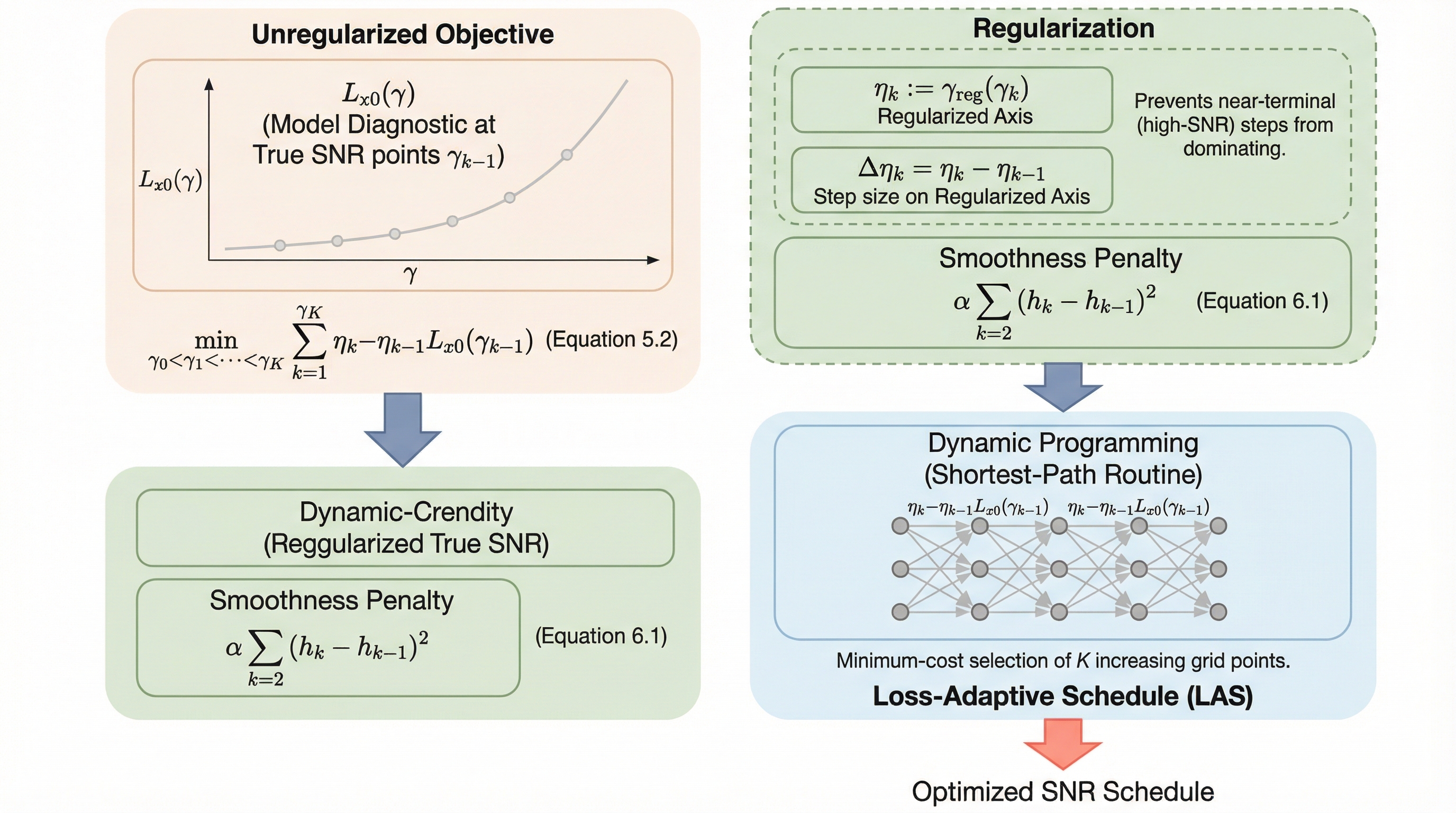
拡散モデルのサンプリング誤差がデータの次元数に比例して増大するという従来の理論的制約を打破し、情報の複雑さを示す「シャノン・エントロピー」を用いることで、次元に依存しない新しい収束境界を導出しました。
トランスフォーマーモデルは優れた性能を持つ一方で、推論時に膨大な計算資源とメモリを要求するため、複数のデバイスに処理を分割して実行する手法が注目されていますが、その際に生じる中間表現の転送コストを抑えるための損失あり圧縮フレームワークが新たに提案されました。
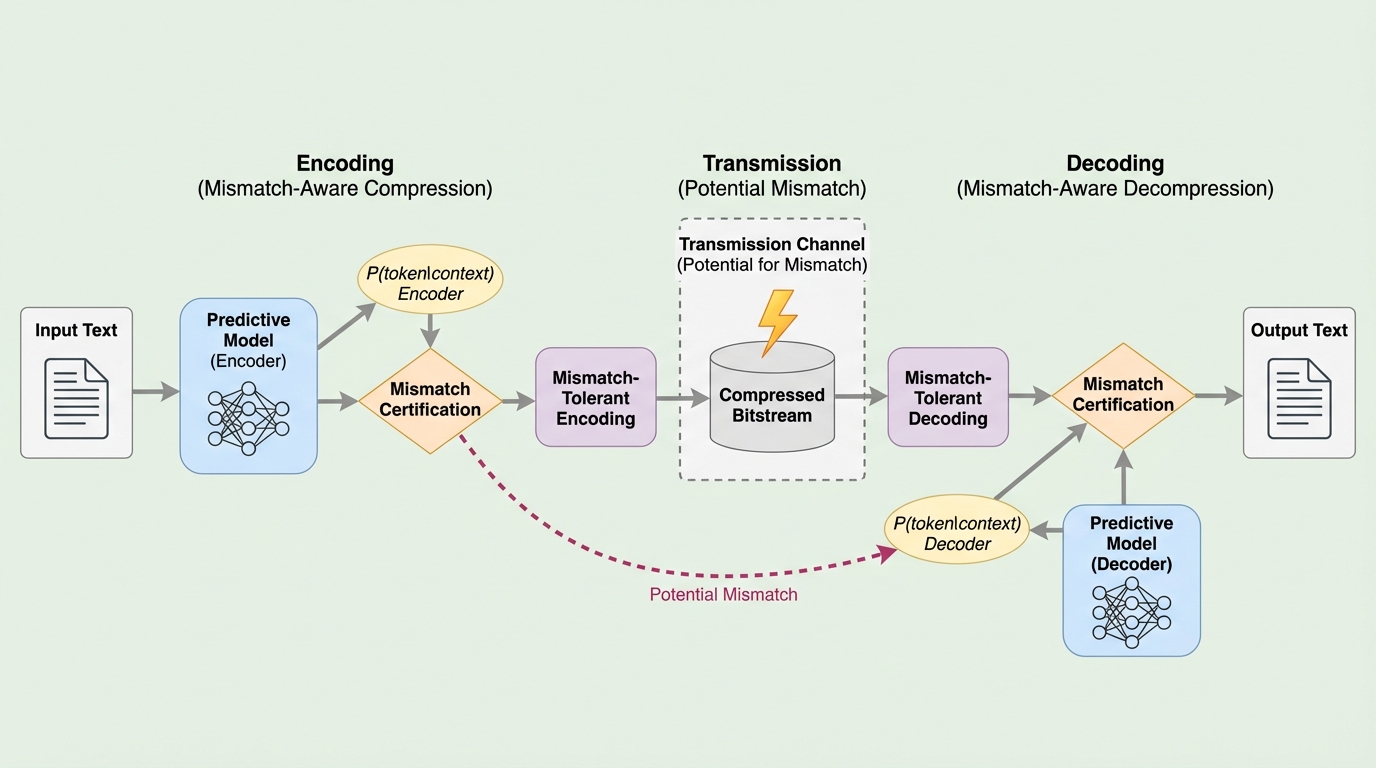
大規模言語モデル(LLM)を用いたデータ圧縮において、計算環境の違いで生じる予測確率の微細な不整合が復号失敗を招くという重大な課題に対し、確率のズレを乗法的な範囲で許容する新しい可逆圧縮アルゴリズムが提案されました。
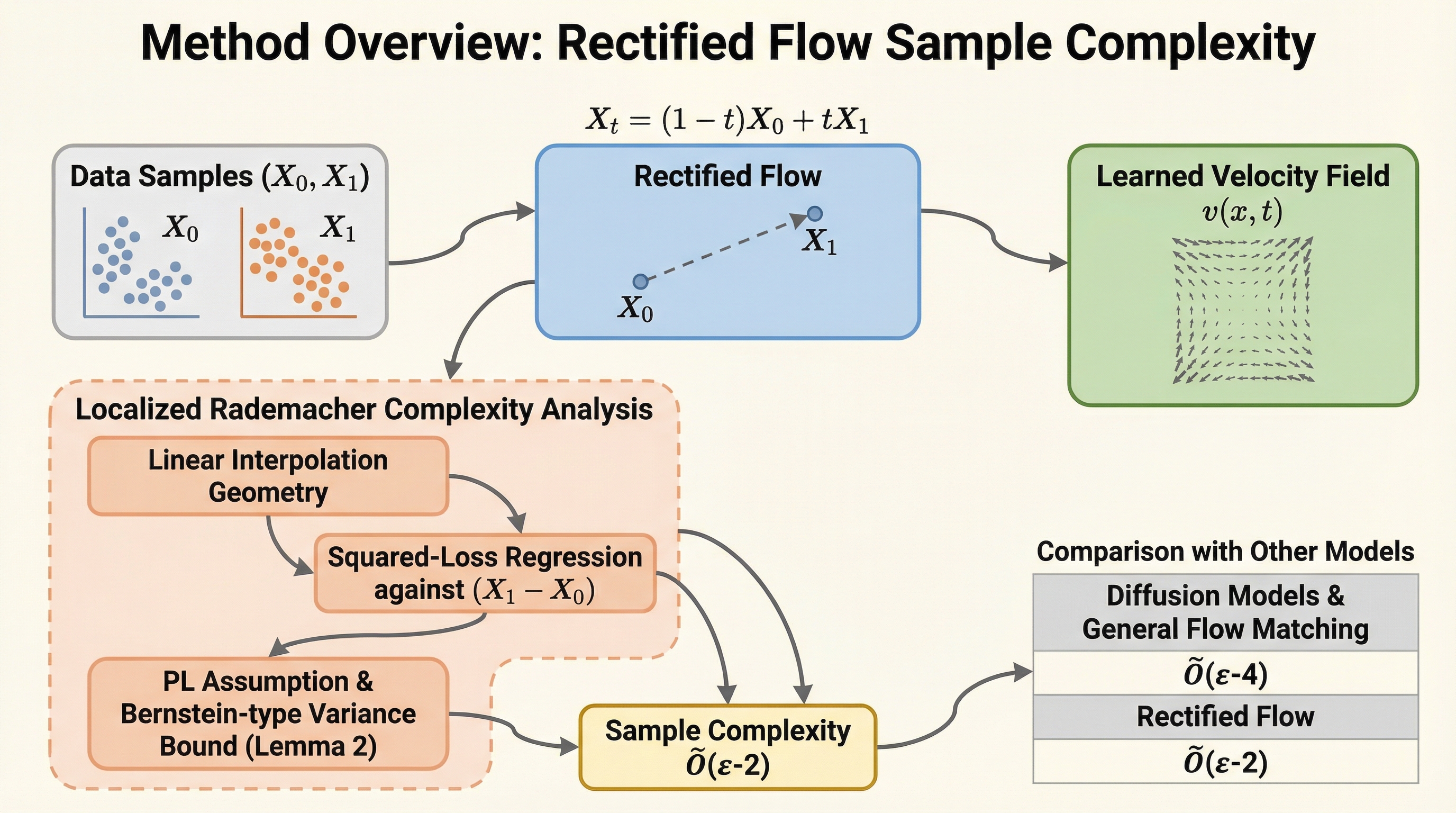
本研究は、Rectified Flow(RF)がターゲット分布を学習する際に必要とするサンプル数(サンプル複雑度)において、情報理論的な下限値である $\tilde{O}(\epsilon^{-2})$ を達成することを理論的に証明しました。
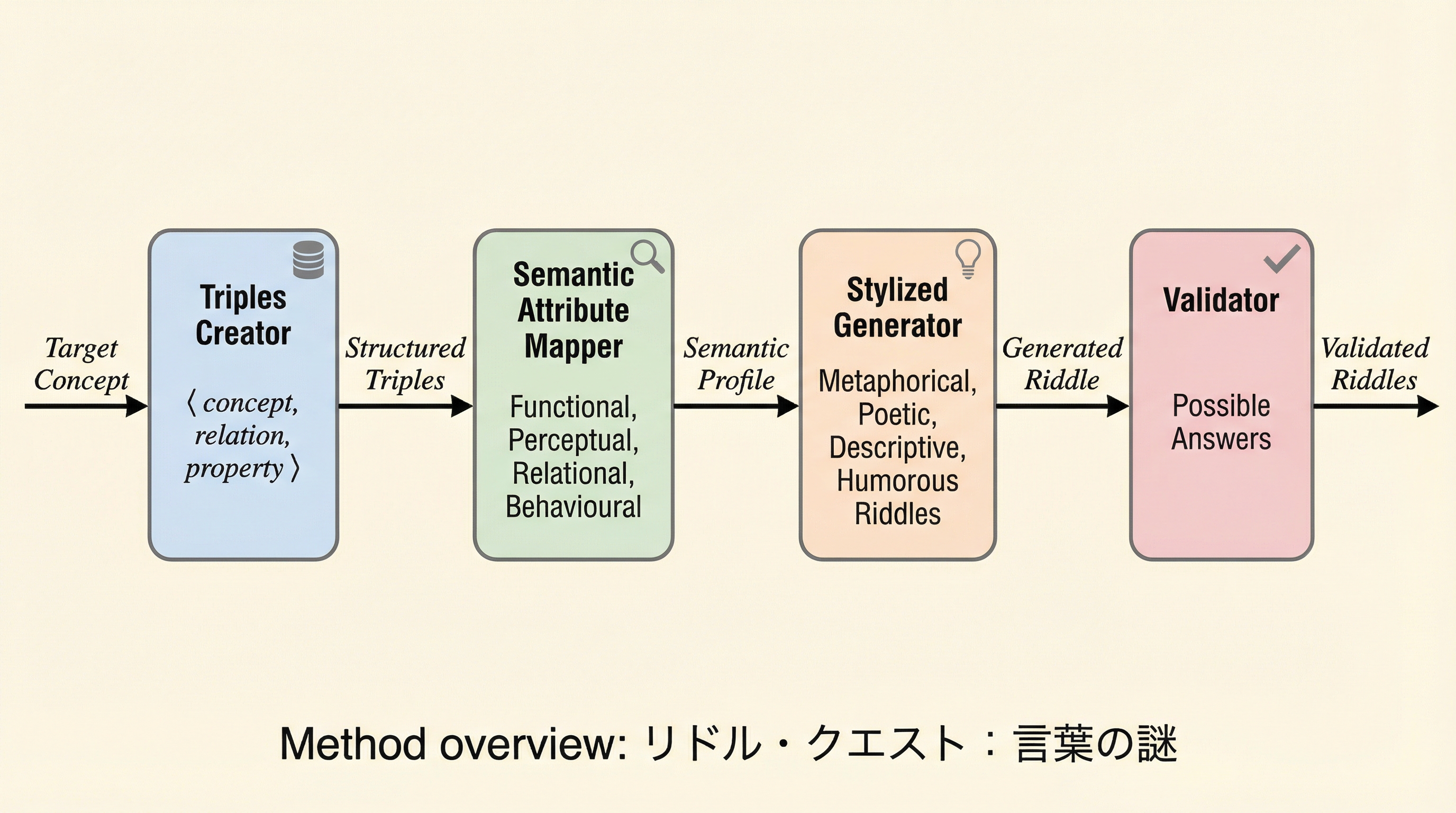
本研究は、類推に基づくなぞなぞを自動生成し、大規模言語モデルの推論能力や曖昧さの処理能力を多角的に評価するための新しいパイプライン「リドル・クエスト」を提案している。 システムは対象概念を構造化データとして捉え、属性分類を経て五つの多様なスタイルで問題を生成するが、検証の結果、最新の言語モデルであっても比喩的表現における正解の網羅的な特定には大きな課題があることが判明した。 なぞなぞは、人工知能の抽象化能力や多段階の推論を測定するための軽量かつ有効なマイクロベンチマークとして機能し、単なる正誤判定を超えてモデルが持つ知識の広がりと解釈の深さを定量的に評価する重要なツールとなる。