不整合に耐性のあるモデル駆動型可逆圧縮アルゴリズム
大規模言語モデル(LLM)を用いたデータ圧縮において、計算環境の違いで生じる予測確率の微細な不整合が復号失敗を招くという重大な課題に対し、確率のズレを乗法的な範囲で許容する新しい可逆圧縮アルゴリズムが提案されました。
TL;DR(結論)
大規模言語モデル(LLM)を用いたデータ圧縮において、計算環境の違いで生じる予測確率の微細な不整合が復号失敗を招くという重大な課題に対し、確率のズレを乗法的な範囲で許容する新しい可逆圧縮アルゴリズムが提案されました。 この手法は、従来の数値精度に極めて敏感な算術符号化に依存せず、ハフマン符号に近い接頭辞符号の仕組みを応用しており、エンコーダとデコーダの間で確率分布に構造的な不一致があっても、特定の条件下で数学的に正しい復号を保証できることが証明されています。 実際のデータセットを用いた検証では、業界標準のgzipを超える圧縮率を達成しつつ、GPUの浮動小数点演算の順序変更などに起因する数値的な誤差に対しても堅牢に動作することが示され、実用的なモデル駆動型圧縮の実現に向けた大きな進展となりました。
なぜこの問題か
現代のデータ圧縮技術において、次に現れるシンボルを正確に予測する能力と圧縮効率には深い相関があり、大規模言語モデル(LLM)のような強力な予測モデルを算術符号化と組み合わせることで、標準的なアルゴリズムを大幅に凌駕する圧縮率が達成されています。しかし、このアプローチは「エンコーダとデコーダが全く同一の出力分布を生成する」という極めて厳格な前提条件に依存しており、わずかな不一致でも復号が完全に失敗するという脆弱性を抱えています。現実の計算環境では、同じ入力と乱数シードを用いても、異なるマシン間で同一の出力が得られない「非決定性」と呼ばれる現象が発生します。特にGPUを用いた推論パイプラインでは、ハードウェアアーキテクチャやソフトウェアのバージョン、実行環境の違いによって、浮動小数点演算の順序が入れ替わったり、近似方法が異なったりすることがあります。 こうした微細な数値的差異は、ニューラルネットワークの多層的な計算過程を通じて増幅され、最終的な予測確率を実質的に変化させてしまいます。GPUライブラリの多くは、特定の条件下で決定性を保証しないことを明記しており、これがモデル駆動型圧縮を実用化する上での大きな障壁となっていました。…
核心:何を提案したのか
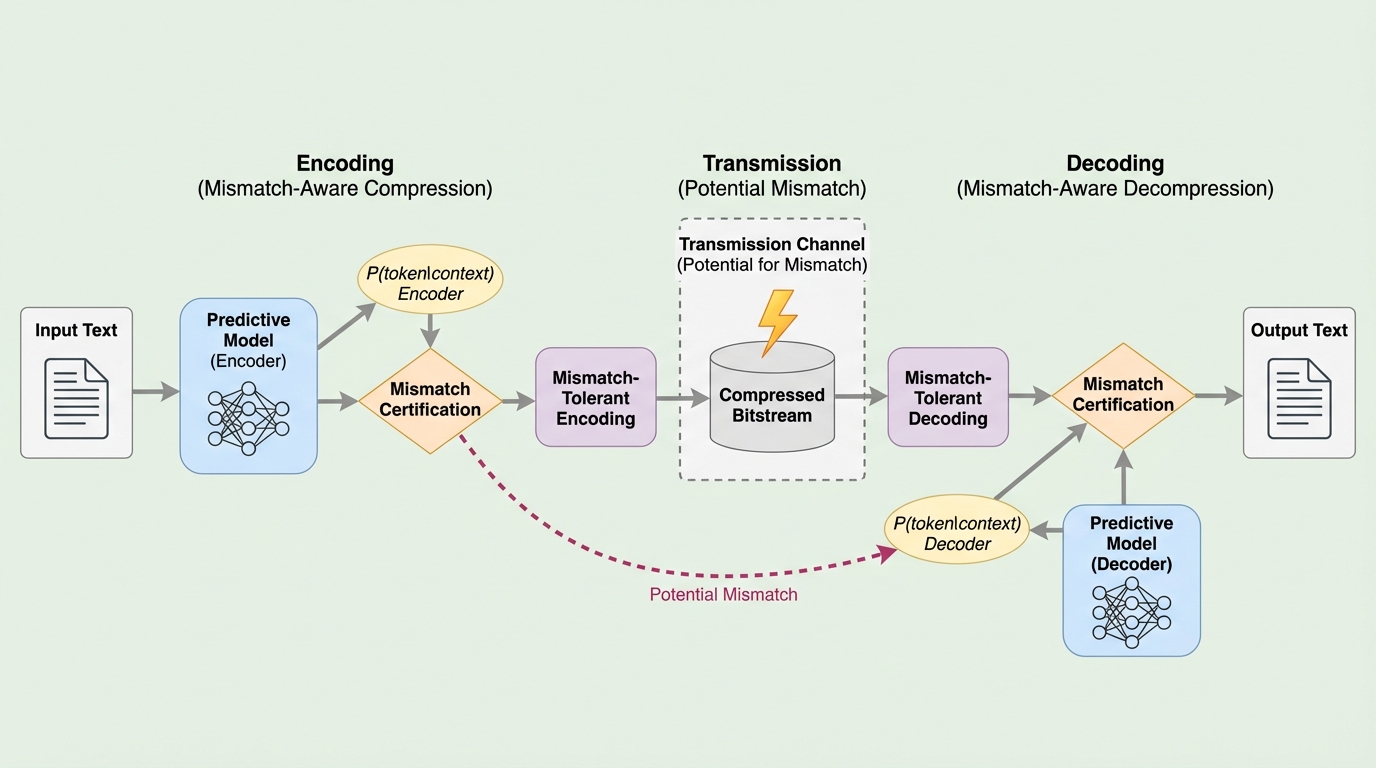
本研究では、エンコーダとデコーダの間の構造的な予測不整合を許容しつつ、高い圧縮性能を維持する新しいモデル駆動型可逆圧縮アルゴリズムを提案しています。このアルゴリズムの最大の特徴は、従来の算術符号化を捨て、ハフマン符号に近い接頭辞符号の考え方をベースに構築されている点にあります。提案手法は、予測される確率分布が乗法的に類似しているという仮定に基づいています。具体的には、最大不一致係数 $c$ というパラメータを導入し、エンコーダとデコーダの予測確率の対数差がこの範囲内に収まっている場合に、正しく復号できることを数学的に証明しました。この「不整合の認定」という概念により、従来の数値的な厳密さへの依存から脱却しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related