MARS:マージンを考慮した自己洗練による報酬モデリング――曖昧さ(低マージン)へ学習を寄せる適応的データ拡張
人手の選好データに強く依存する報酬モデリングでは、どの比較が「判断しにくいか」を無視して一様に増やしても、モデルの弱点に学習が届かない可能性があるため、推定が難しい領域を狙って鍛える発想が重要です。
TL;DR(結論)
- 人手の選好データに強く依存する報酬モデリングでは、どの比較が「判断しにくいか」を無視して一様に増やしても、モデルの弱点に学習が届かない可能性があるため、推定が難しい領域を狙って鍛える発想が重要です。
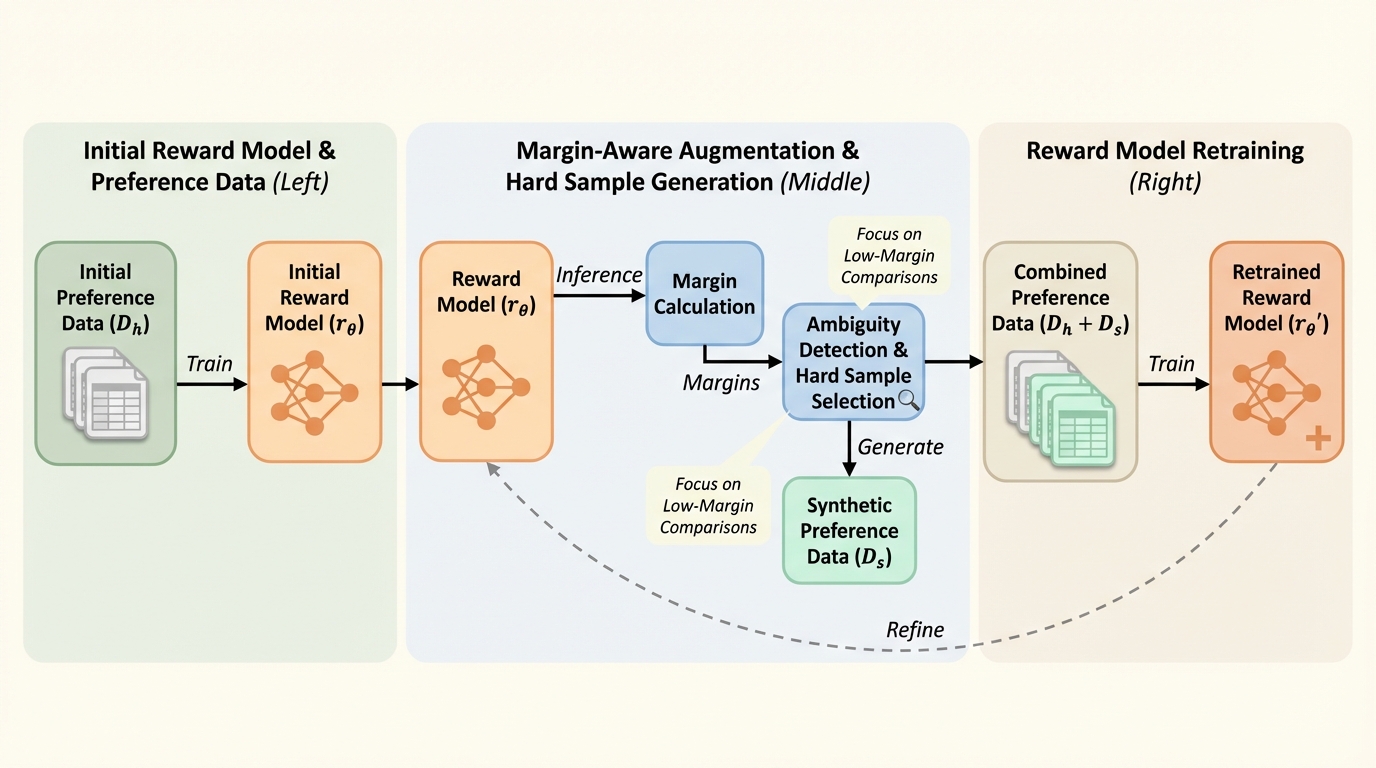
- MARSは、好ましい応答と棄却応答のスコア差が小さい比較ペア(低マージン)を曖昧な例として抽出し、そこへ拡張とサンプリングを集中させたうえで、難例中心の学習分布へ反復的に更新します。
- 理論的には損失の平均曲率が高まって情報量と最適化の条件付けが改善すると説明され、実証でも一様な拡張より一貫した改善が示されることで、より頑健な報酬モデル学習に繋がる可能性が示唆されます。
なぜこの問題か
報酬モデリングは、RLHFやRLAIFといった整列パイプラインの中で中核的な役割を担います。特に、PPOやTRPOのような方策最適化では、学習済みの報酬関数が更新方向を左右するため、報酬モデルの品質が整列結果に直結しやすいです。実運用でも、選好データからまず報酬モデルを訓練し、その報酬モデルを用いて方策を最適化する流れが重要だと位置づけられています。 一方で、信頼できる報酬モデルを作るには、人手で付与された選好ラベルが必要になりやすいです。典型的には、同一プロンプトに対する2つの応答を提示し、どちらが好ましいかをアノテータが選ぶペアワイズ比較がデータの基本単位になります。しかし、この人手データは高コストで、量にも限界があります。そこでデータ拡張が動機になりますが、既存の拡張は表現や意味の操作に寄りやすく、報酬モデルが「どの比較で推定に苦しんでいるか」という難易度に必ずしも合わせていない点が問題になります。 さらに、報酬モデリングには、報酬ハッキング、誤った一般化、無関係な特徴への過敏さといった脆弱性が報告されており、単にデータを増やすだけでは頑健性に繋がらない可能性があります。…
核心:何を提案したのか
本論文が提案するMARSは、マージンを手がかりにした適応的なデータ拡張とサンプリングの枠組みです。ここでいうマージンは、同じプロンプトに対して提示された2応答のうち、好ましい応答と棄却応答に対して報酬モデルが与えるスコアの差として扱われます。差が小さいと、モデルは両者を十分に区別できておらず、判断が曖昧な比較ペアだと解釈できます。MARSはこの低マージンのペアを、報酬モデルの不確実性が高い領域、あるいは失敗モードが出やすい領域の兆候として利用します。 提案の中心は、拡張を「全体に一様に施す」のではなく、低マージンの比較ペアへ集中的に適用する点です。これにより、モデルが迷っている境界付近の例が増え、学習が難所に届きやすくなります。またMARSは自己洗練を掲げており、現時点のモデルで曖昧さを測り、その結果に基づいて次の学習に使うデータ分布を更新することを繰り返します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related