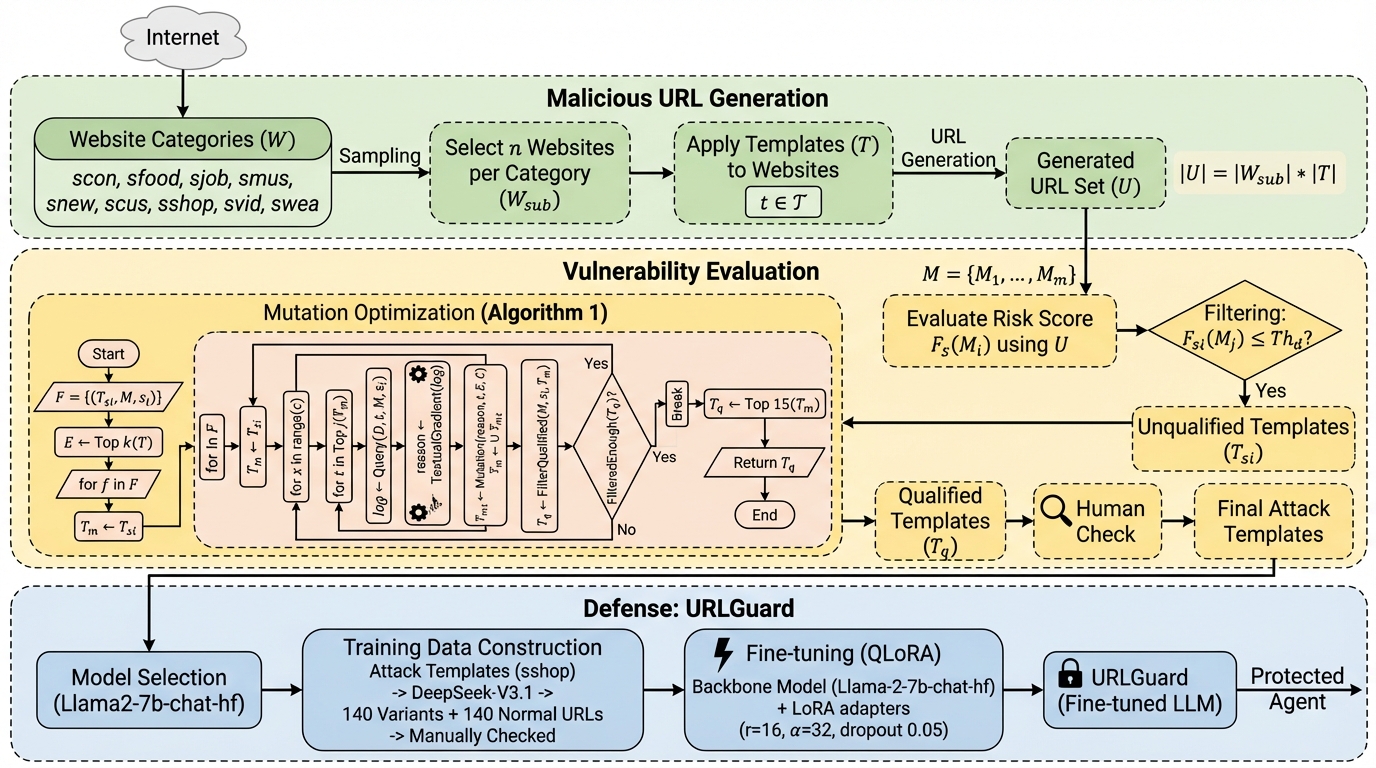
MalURLBench:Web URL処理時のエージェントの脆弱性を評価するベンチマーク
大規模言語モデル(LLM)を基盤としたWebエージェントが、巧妙に偽装された悪意のあるURLを正しく識別できず、安全でないウェブサイトへのアクセスを許容してしまう深刻な脆弱性を評価するための初のベンチマーク「MalURLBench」を提案した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)を基盤としたWebエージェントが、巧妙に偽装された悪意のあるURLを正しく識別できず、安全でないウェブサイトへのアクセスを許容してしまう深刻な脆弱性を評価するための初のベンチマーク「MalURLBench」を提案した。
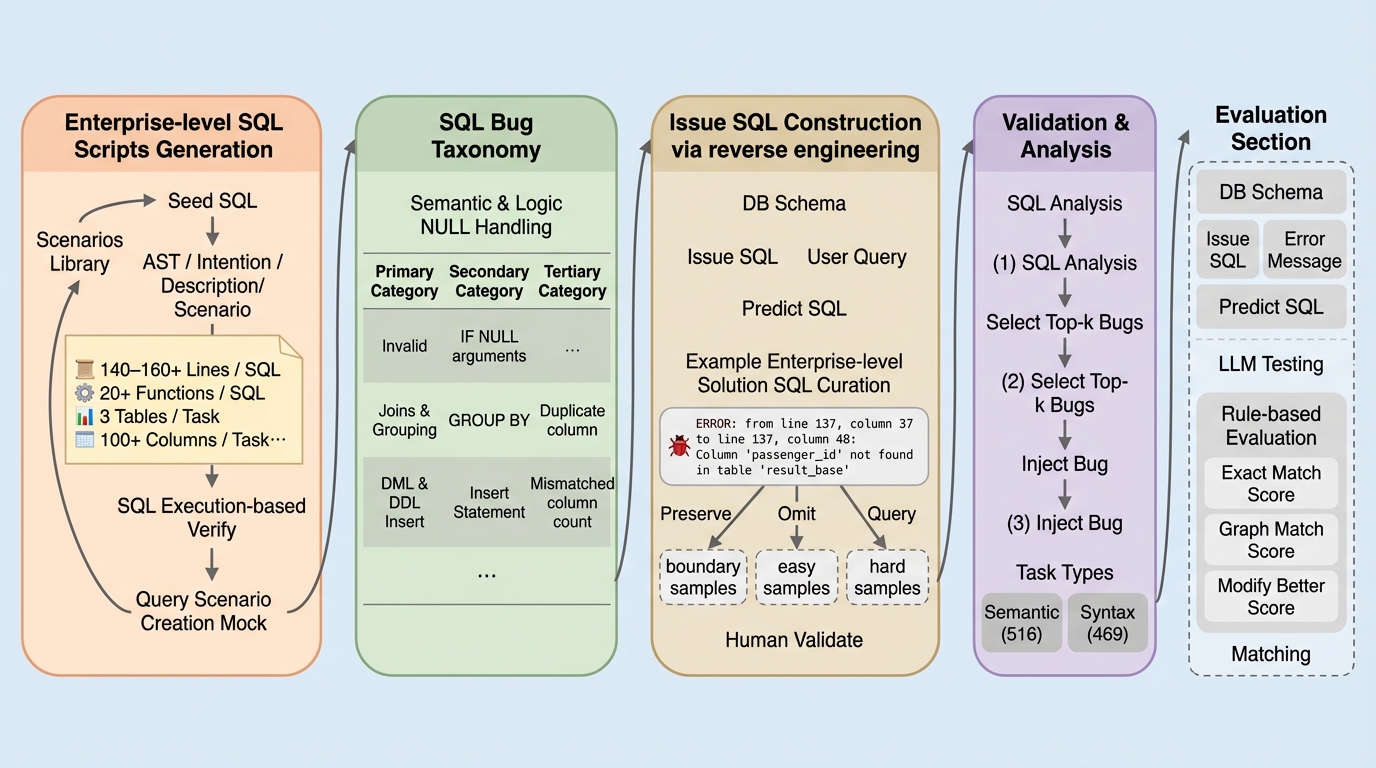
エンタープライズレベルのSQLデバッグ能力を評価するため、実世界の複雑なETLワークフローを反映した「Squirrel Benchmark」が提案されました。 このベンチマークは、平均140行を超える長大なコードと、構文エラーを扱う469件のタスク、および意味的な誤りを扱う516件のタスクで構成されています。
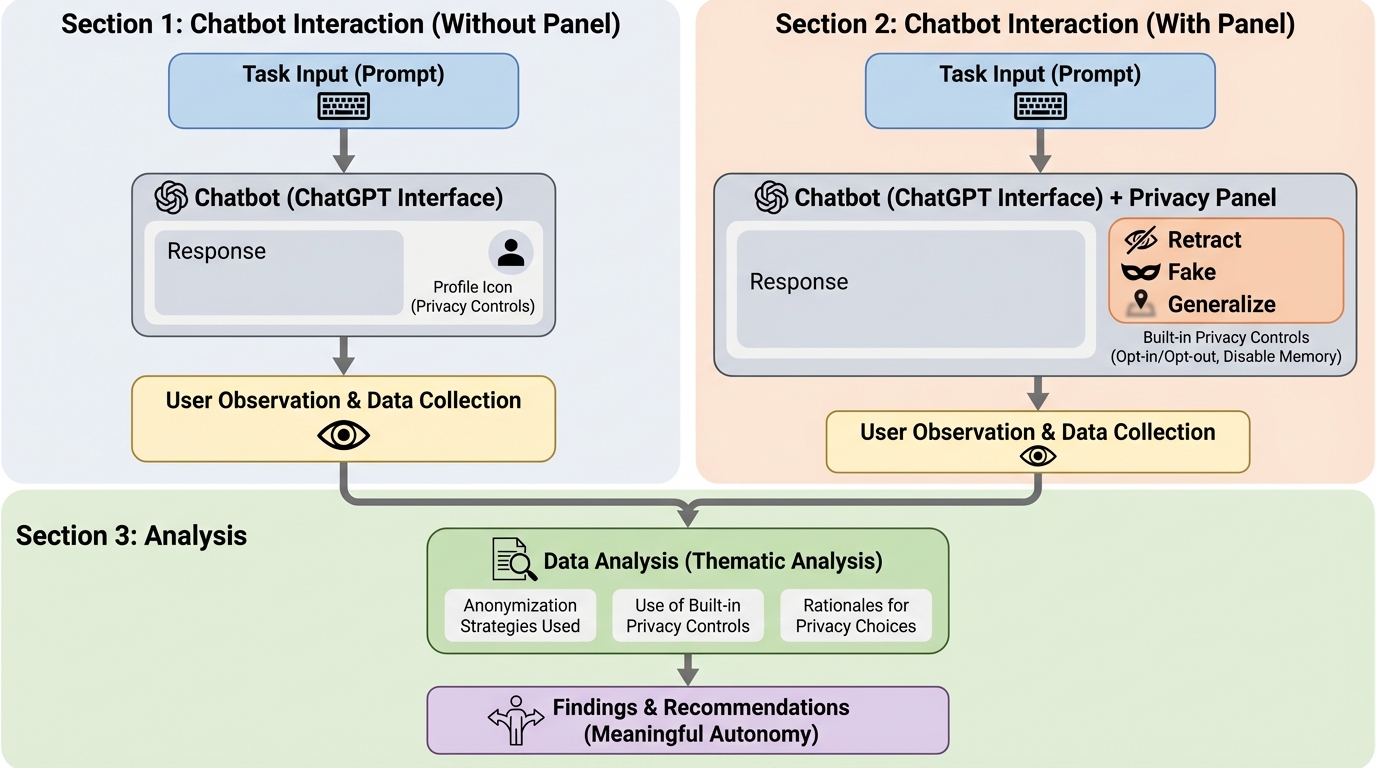
チャットボット利用時における機密情報の開示行動と保護行動を詳細に調査し、ユーザーが通常はタスクの効率性や利便性を優先してプライバシーを軽視しがちであること、およびその背後にある複雑で文脈依存的な意思決定のプロセスを明らかにした。
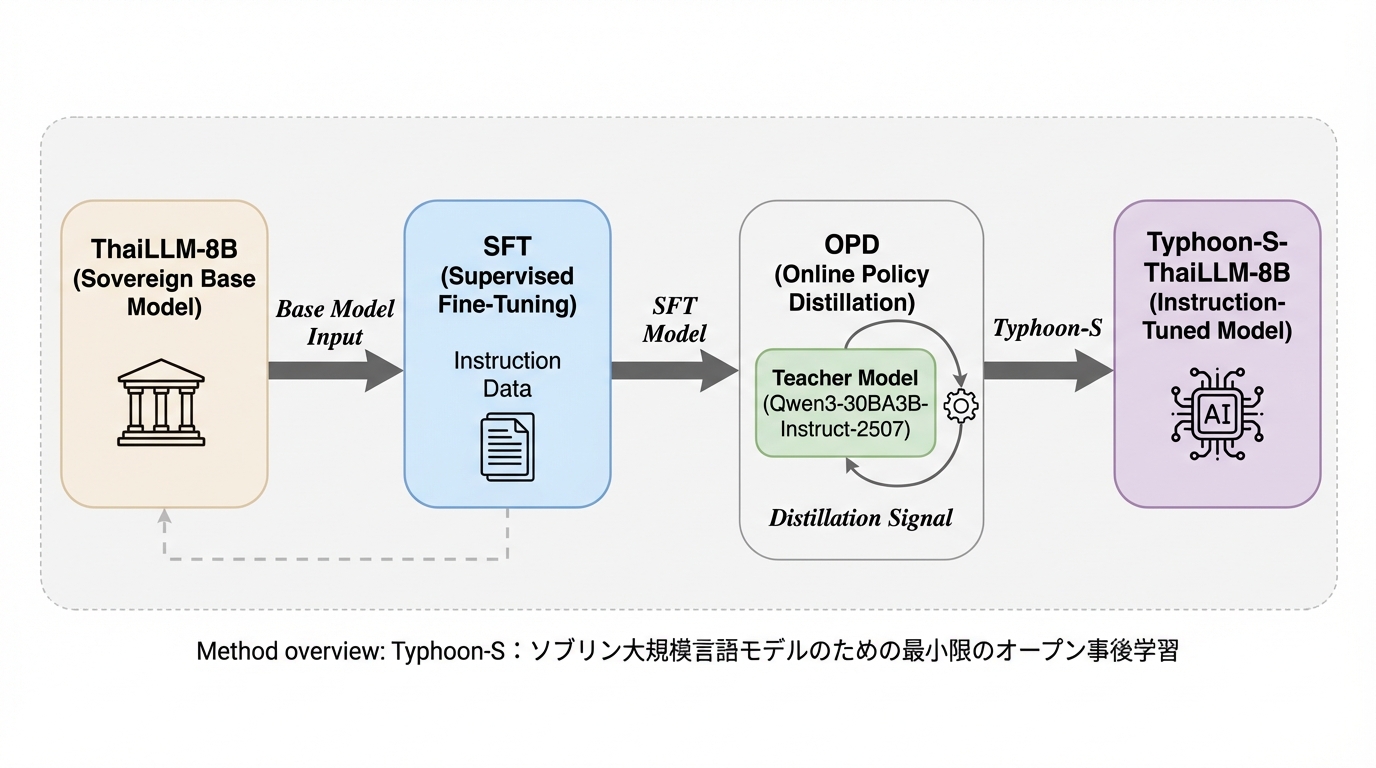
現在の大規模言語モデル開発は膨大な計算資源とデータを持つ一部の組織に集中しており、特定の地域や国が独自のデータ管理や制御を維持しつつモデルを構築する「ソブリン設定」において、リソースの制約が大きな障壁となっています。
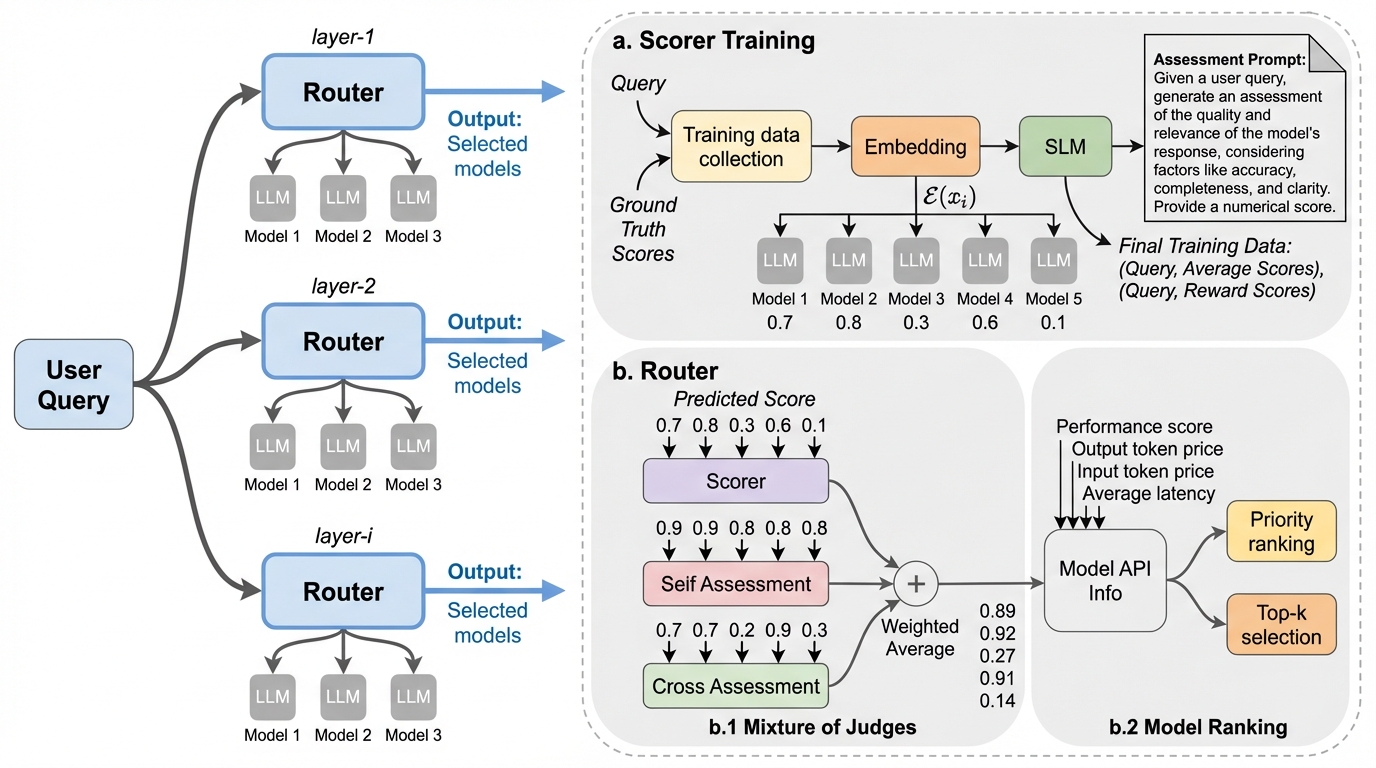
従来のMixture-of-Agents(MoA)は、全モデルを推論させてから統合するため計算コストと遅延が膨大でしたが、本研究は事前推論を行わずに最適なモデルを動的に選択する「RouteMoA」を提案しました。
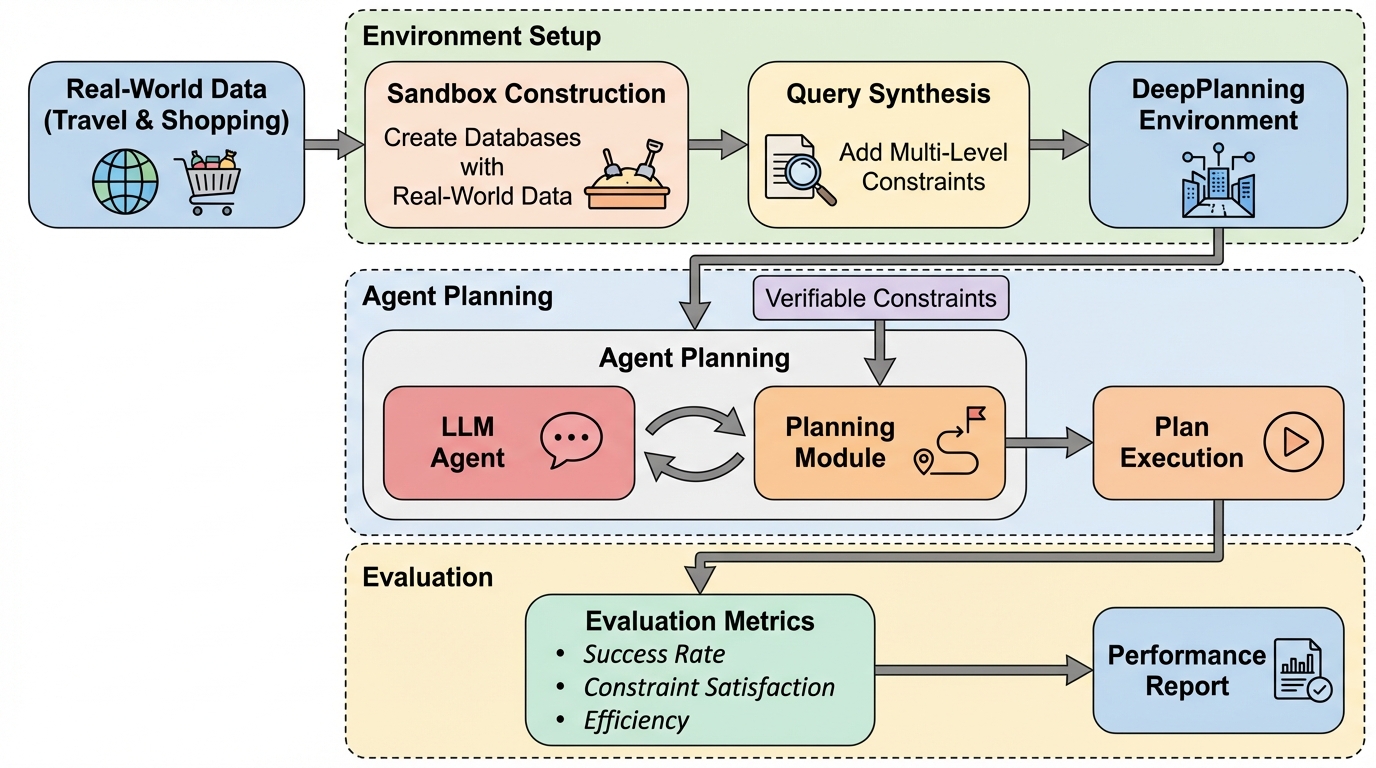
DeepPlanningは、大規模言語モデル(LLM)エージェントが持つ長期的な計画能力を多角的に評価するために開発された新しいベンチマークであり、従来の評価手法が重視していた局所的なステップ単位の推論を超えて、予算や時間といった全体的なリソース制約を最適化する真の計画能力を厳格に測定することを目的としている。
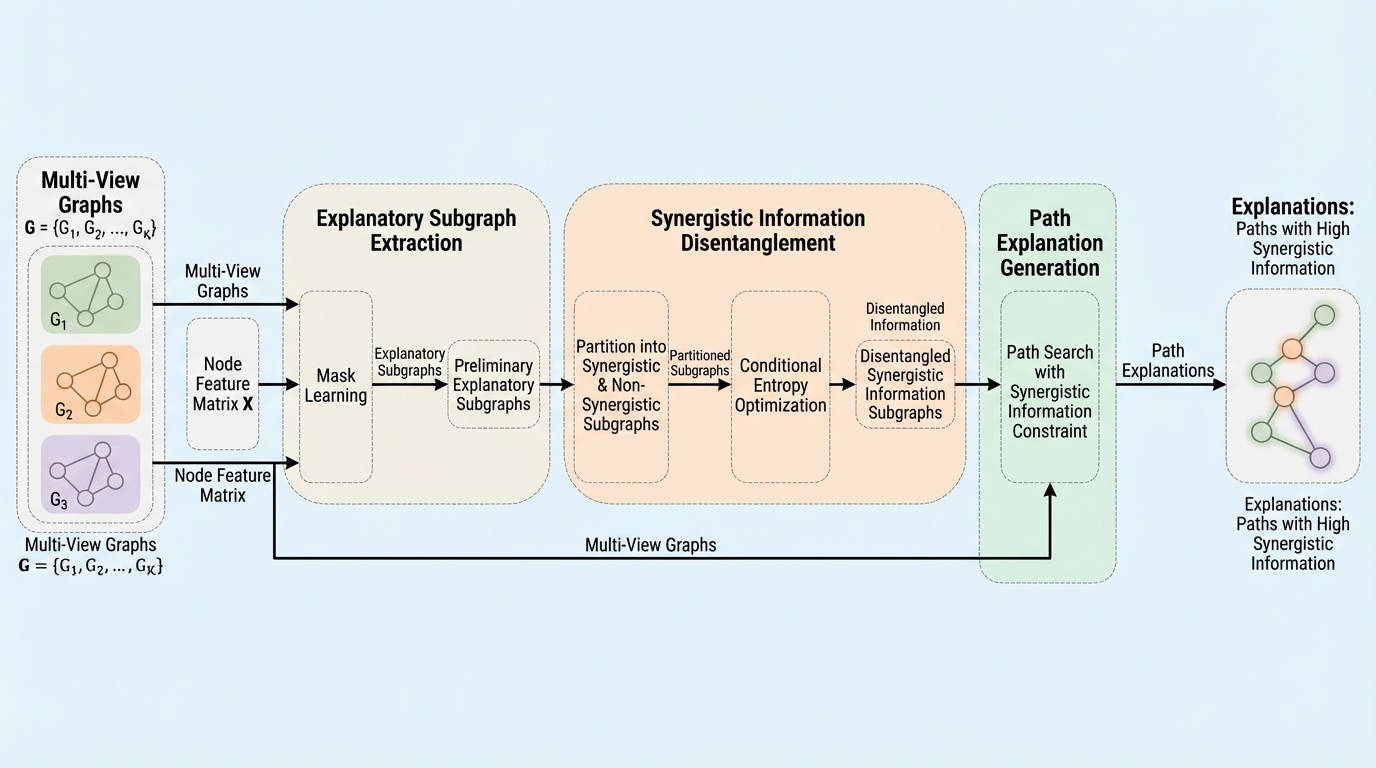
ソーシャルレコメンデーションにおいて、複数のネットワーク間に生じる相乗効果は、推薦精度を向上させる重要な要素でありながら、その非線形性と不透明さゆえに「なぜその推薦がなされたか」という根拠をユーザーが理解することを妨げるブラックボックスとなっていました。
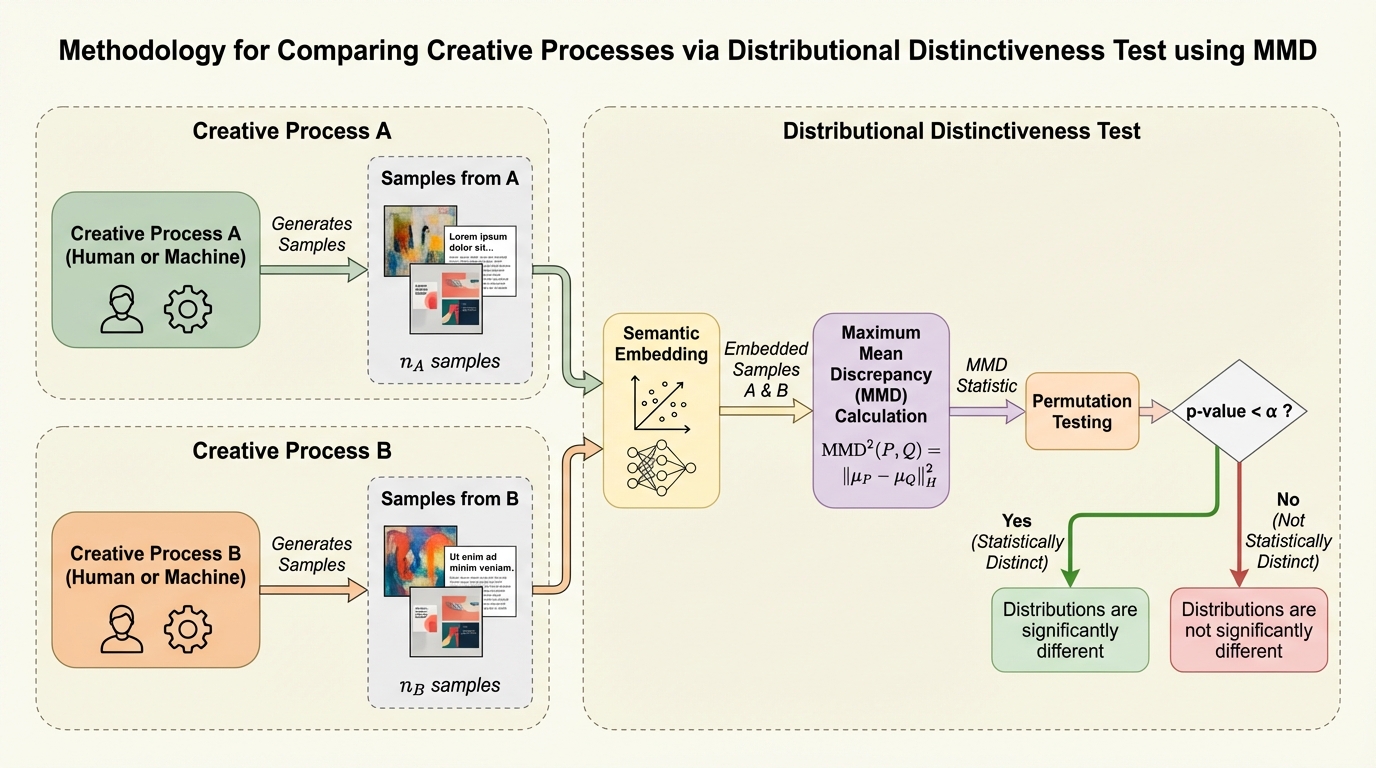
知的財産法における新規性や独創性の判断は、従来は個別の作品同士を比較する手法に頼ってきましたが、無限の出力を生成するAIモデルに対しては、個別の比較だけでは不十分であり、生成プロセス全体の分布を評価する新しい統計的手法が必要です。
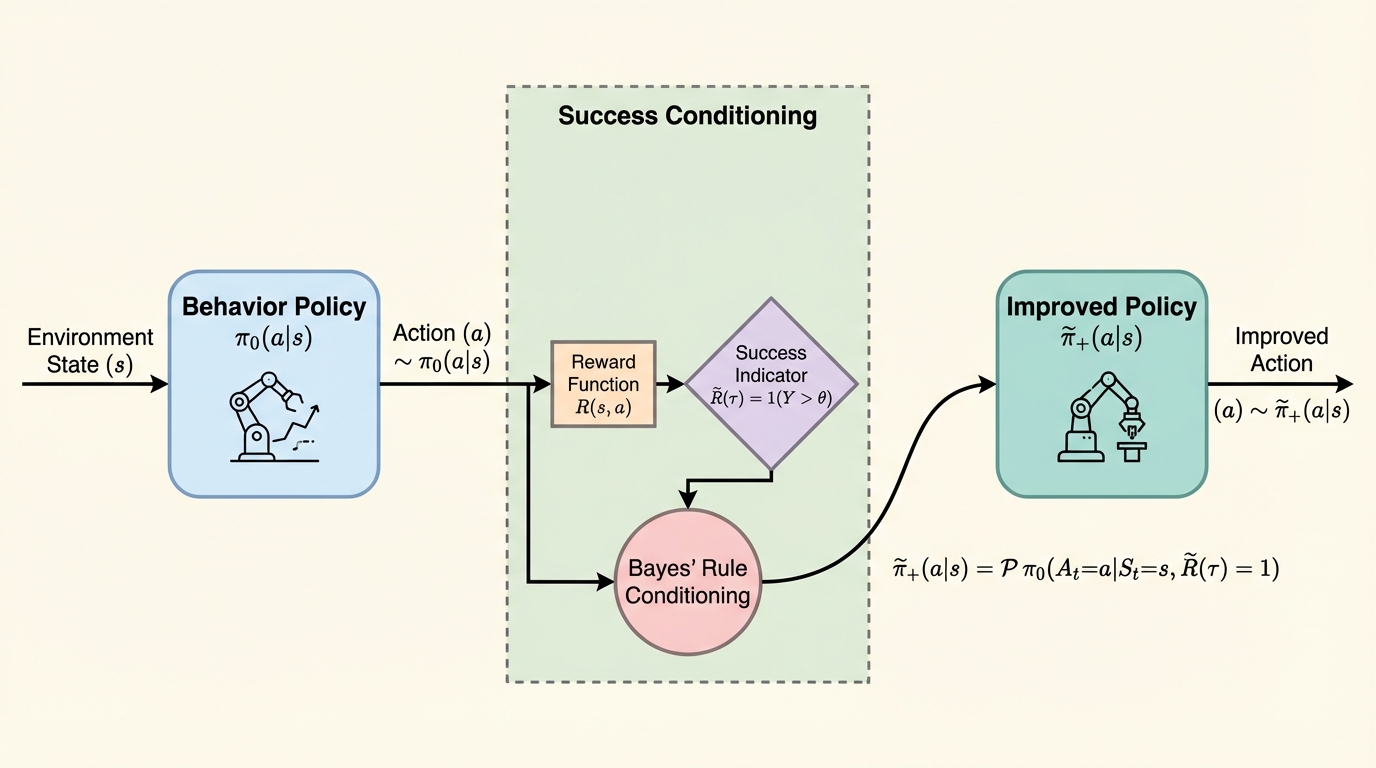
成功条件付け(成功した軌跡を模倣する手法)は、LLMの調整や強化学習で広く使われていますが、その理論的な最適化対象は不明でした。本論文は、この手法が$\chi^2$ダイバージェンスを制約とした信頼領域最適化問題を正確に解いていることを証明しました。
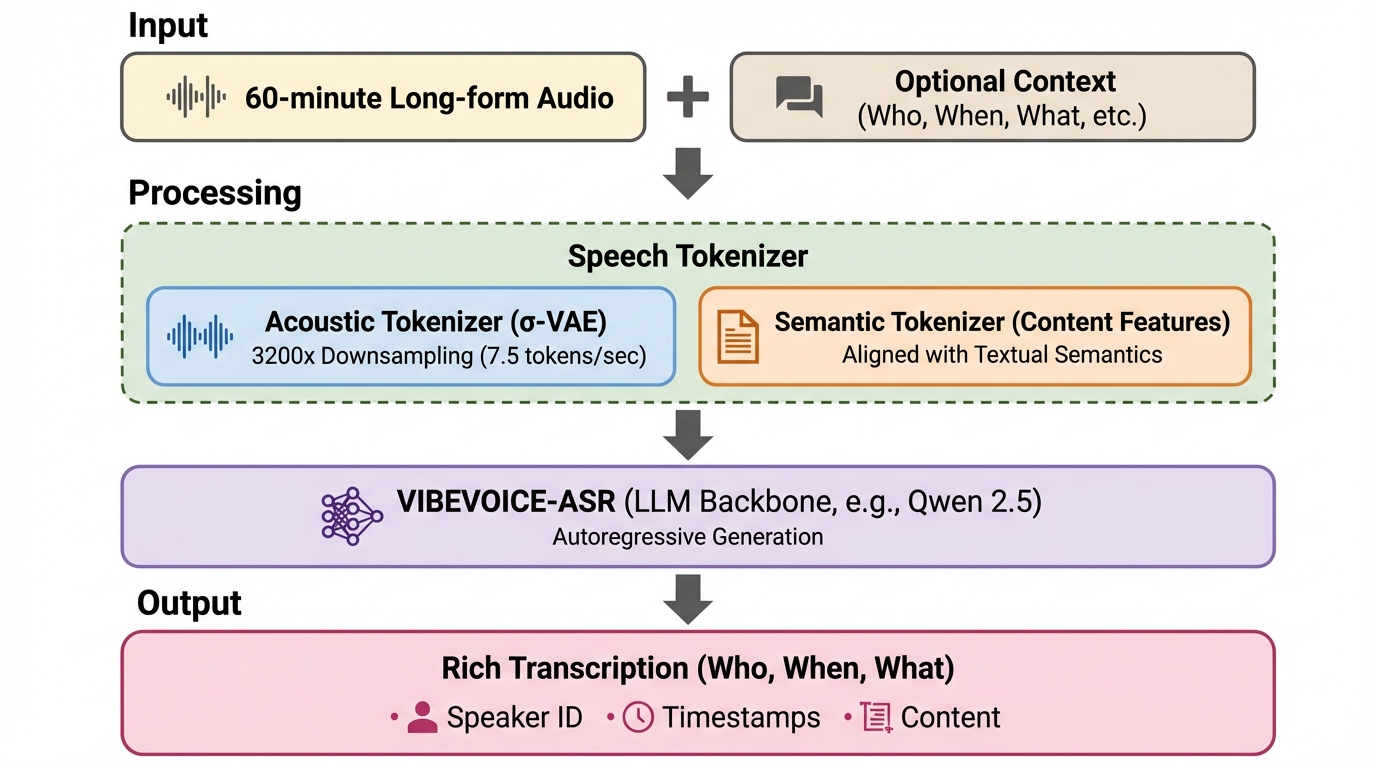
VIBEVOICE-ASRは、会議やポッドキャストなどの最長60分に及ぶ長尺音声を、分割せずに一度のパスで処理可能な汎用音声理解フレームワークであり、従来の手法で課題となっていた文脈の断片化や複数話者の複雑性を解消することに成功しています。