一対比較を超えて:知的財産法における機械生成物の識別性のための分布検定
知的財産法における新規性や独創性の判断は、従来は個別の作品同士を比較する手法に頼ってきましたが、無限の出力を生成するAIモデルに対しては、個別の比較だけでは不十分であり、生成プロセス全体の分布を評価する新しい統計的手法が必要です。
TL;DR(結論)
知的財産法における新規性や独創性の判断は、従来は個別の作品同士を比較する手法に頼ってきましたが、無限の出力を生成するAIモデルに対しては、個別の比較だけでは不十分であり、生成プロセス全体の分布を評価する新しい統計的手法が必要です。 本研究が提案する「最大平均差異(MMD)」を用いた分布検定は、意味的な埋め込みベクトルを活用することで、特定の訓練データを必要とせずに、わずか数個から数十個のサンプルだけで人間とAIの生成物の統計的な違いを客観的に識別することを可能にします。 検証の結果、人間がAI作品を判別できない場合でも、提案手法は明確な分布の差を検出しており、生成AIは単なる訓練データの模倣ではなく、学習された潜在空間内での意味的な補間を通じて、人間とは異なる統計的特性を持つ作品を生み出していることが明らかになりました。
なぜこの問題か
知的財産法(特許法、著作権法、商標法)の根幹には、ある作品が既存の参照群から意味のある形で区別されるべきであるという共通の経験的前提が存在します。特許における「新規性」、著作権における「独創性」、商標における「識別性」は、いずれも新しい作品が既存の資料(先行技術、パブリックドメイン、登録商標など)と十分に異なっているかを問うものです。しかし、現在の実務では、作品群全体の識別性を評価すべき場面であっても、個別のアイテム同士を比較する「一対比較」という分析単位の不一致が蔓延しています。人間が作成した有限の作品群であれば、個別の比較を積み重ねることで対応可能でしたが、生成AIの登場によってこの問題は解決困難なものとなりました。生成モデルは確率的なプロセスであり、事実上無制限の出力空間を持っているため、限られたサンプルのみを比較しても、その結果が系統的なものか偶然のものかを判断することができません。また、AIの生成プロセスは企業秘密の壁に守られていることが多く、訓練データやモデルの内部構造に直接アクセスして検証することは困難です。さらに、人間の観察者による直感的な判断も限界に達しています。…
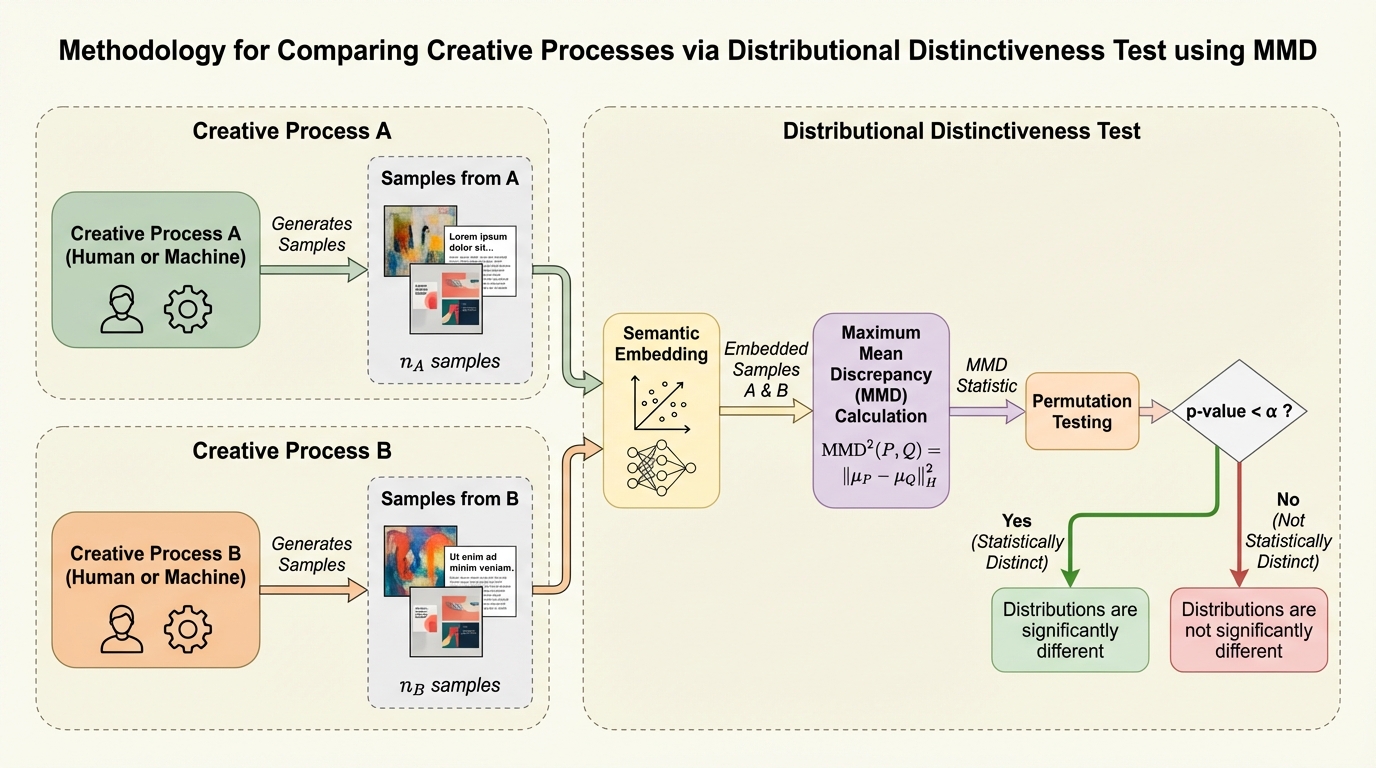
核心:何を提案したのか
本論文は、個別の作品比較に依存する従来の手法に代わるものとして、意味的埋め込み(Semantic Embeddings)上で計算される「最大平均差異(MMD)」に基づいた分布検定を提案しています。この手法は、個々の作品を点として見るのではなく、生成プロセス全体から得られるサンプルの集合を分布として捉え、二つの分布が統計的に同一のソースから抽出されたものかどうかを判定する二標本検定です。具体的には、テキストや画像を、その意味的な関係性が保存された高次元のベクトル空間(埋め込み空間)にマッピングし、その空間内での分布の距離を統計的に測定します。このアプローチの最大の特徴は、特定のタスクのための追加学習を一切必要としない「トレーニングフリー」な性質にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related