DeepPlanning:検証可能な制約を用いた長期的エージェント計画のベンチマーク
DeepPlanningは、大規模言語モデル(LLM)エージェントが持つ長期的な計画能力を多角的に評価するために開発された新しいベンチマークであり、従来の評価手法が重視していた局所的なステップ単位の推論を超えて、予算や時間といった全体的なリソース制約を最適化する真の計画能力を厳格に測定することを目的としている。
TL;DR(結論)
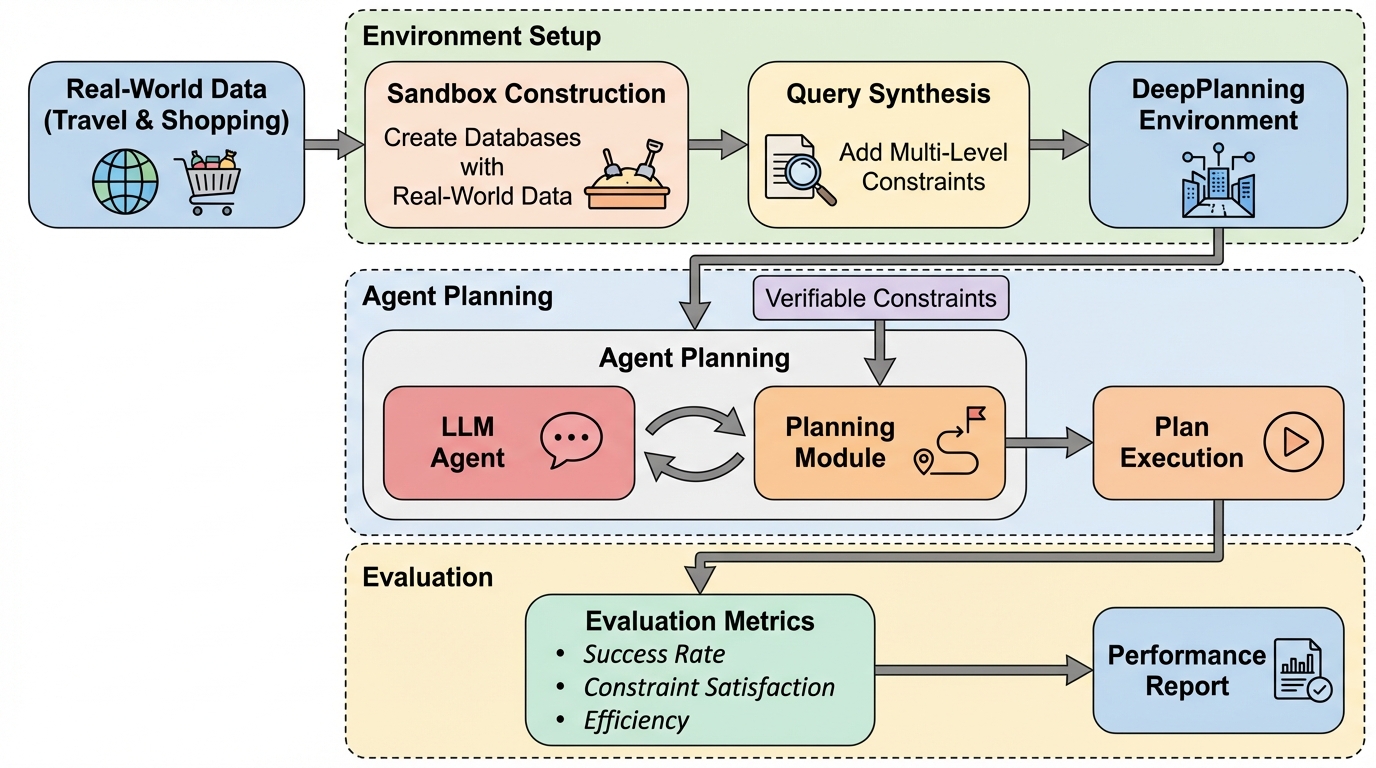
DeepPlanningは、大規模言語モデル(LLM)エージェントが持つ長期的な計画能力を多角的に評価するために開発された新しいベンチマークであり、従来の評価手法が重視していた局所的なステップ単位の推論を超えて、予算や時間といった全体的なリソース制約を最適化する真の計画能力を厳格に測定することを目的としている。 本ベンチマークは、数日間にわたる詳細な旅行計画と、複数の条件を満たす最適な商品購入を行うショッピング計画という2つの複雑な実世界のドメインで構成されており、エージェントは独立したサンドボックス環境内で提供される専用のAPIを能動的に駆使して情報を収集し、論理的な矛盾がなく実行可能な計画を構築することが求められる。 最新の推論型LLMを含む多様なモデルを対象とした大規模な評価の結果、最高性能のモデルであっても複雑な制約が絡み合う状況での整合性維持や暗黙的な環境制約の把握に苦戦しており、長期的な計画タスクを成功させるためには、信頼性の高い明示的な推論パターンや効率的な並列ツール利用といった高度な戦略が不可欠であることが明らかになった。
なぜこの問題か
現在、AIエージェントの評価は、単発のツール利用を問う短期間のタスクから、ユーザーの複雑な要求を満たす長期間のタスクへと急速に移行している。しかし、既存のベンチマークの多くは、個別のステップにおける局所的な推論や指示追従に重点を置いており、時間や予算といった全体的な制約を最適化する真の計画能力を十分に評価できていないという課題がある。現実世界のタスクでは、環境から能動的に情報を収集し、複数の制約が複雑に絡み合う中で最適な解を見つけ出す必要がある。例えば、旅行計画では移動時間、ホテルの空き状況、観光地の営業時間、そして全体の予算が相互に依存しており、一つの要素の変更が計画全体の破綻を招く可能性がある。既存の手法では、こうした高度な整合性やリソース管理を測定するための難易度が不足しており、また評価の検証可能性も不十分であった。 古典的な計画タスクのベンチマークも存在するが、それらは現実の複雑な情報取得プロセスを抽象化しすぎており、実用的なエージェントの能力を測るには乖離がある。したがって、実世界の複雑さを反映しつつ、客観的かつ厳格に計画能力を評価できる新しい基盤が求められていた。…
核心:何を提案したのか
本研究では、実用的な長期的エージェント計画を評価するための包括的なベンチマーク「DeepPlanning」を提案した。このベンチマークは、数日間にわたる詳細な旅行計画(Travel Planning)と、複数の条件を満たす最適な商品購入計画(Shopping Planning)という2つの複雑なドメインで構成されている。提案の核心は、エージェントが備えるべき3つの主要な能力を統合的に評価することにある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related